

1 Introduction
Science mapping is a generic process of domain analysis and visualization. The scope of a science mapping study can be a scientific discipline, a field of research, or topic areas concerning specific research questions. In other words, the unit of analysis in science mapping is a domain of scientific knowledge that is reflected through an aggregated collection of intellectual contributions from members of a scientific community or more precisely defined specialties. The scope of the domain should contain major components that are relevant to the underlying research program. The structure of the domain may experience constant and possibly revolutionary changes.
A science mapping study typically consists of several components, notably a body of scientific literature, a set of scientometric and visual analytic tools, metrics, and indicators that can highlight potentially significant patterns and trends, and theories of scientific change that can guide the exploration and interpretation of visualized intellectual structures and dynamic patterns.
Commonly used sources of scientific literature include the Web of Science, Scopus, Google Scholar, and PubMed. Scientometric methods include author co-citation analysis (ACA) (Chen, 1999a; White & McCain, 1998), document co-citation analysis (DCA) (Chen, 2006; Small, 1973), co-word analysis (Callon et al., 1983), and many other variations. Visualization techniques include graph or network visualization (Herman, Melançon, & Marshall, 2000), visualizations of hierarchies or trees (Johnson & Shneiderman, 1991), visualizations of temporaral structures (Morris et al., 2003), geospatial visualizations, and coordinated views of multiple types of visualizations. Metrics and indicators of research impact include citation counts (Garfield, 1955), the h-index (Hirsch, 2005) and its numerous extensions, and a rich set of altmetrics on social media (Thelwall et al., 2013). Theories of scientific change include the paradigmatic views of scientific revolutions, scientific advances driven by competitions, and evolutionary stages of a scientific discipline. In order to conduct a science mapping study, researchers need to develop a good understanding of each of the categories of skills and knowledge outlined above. Furthermore, each of these categories is a current and active research area in its own right, for instance, the current research on finding the optimal field normalization method and the debates over how various potentially conflicting theories of scientific change may be utilized to reveal the underlying mechanisms of how science advances.
The complexity of science mapping is shared by many research fields. In this article, our aim is to demonstrate the process of a systematic review based on a series of visual analytic functions implemented in the continously evolving software CiteSpace (Chen, 2004; Chen, 2006; Chen, Ibekwe-SanJuan, & Hou, 2010). We demonstrate the steps of preparing a representative dataset, how to generate visualizations that can guide our review, and how to identify salient patterns at various levels of granularity. We also aim to set an example of a systematic review that can address questions that are commonly asked by researchers when they need to grasp the state of the art of a fast growing and complex scientific domain.
Since the origin and major milestones of the science mapping research will become clear as we visualize and explain our results, we will first describe the methodology and then present the results with our interpretations and reflections as the systematic review.
2 Theories of Scientific Change
The widely known theory of scientific change is Thomas Kuhn’s scientific revolutions (Kuhn, 1962). According to Kuhn’s structure of scientific revolutions, science advances as an iterative revolutionary process, in which scientific paradigms compete for a predominant position, i.e. paradigm shifts. The process consists of several stages: normal science, crises, and revolutions. At the normal science stage, research in a field is primarily dominated by a particular scientific paradigm, consisting of a set of theories, methods, and a consensus of a research agenda. At the crisis stage, anomalies become inevitable and they challenge the fundation of the current paradigm. Alternative and competing paradigms are developed to address the anomalies. At the revolutionary stage, compeling evidence is accumulated and competing paradigms become mature enough to take over the existing paradigm that has been evidently incapable of handling the pressing crises. A new paradigm replaces the existing paradigm and provides the overarching framework for the research community. This process repeats itself as the new paradigm becomes the norm.
A sociological theory of scientific change proposed by Fuchs (1993) challenges the Kuhnian paradigm shift model as an oversimplified view of the complex reality. Instead, Fuchs proposes that advances of science are driven by sociological reasons, i.e. by scientists who are competing for recognition and reputation in their organizational settings. Fuchs suggests that interactions of two variables may derive four types of scientific change. The two variables are task uncertainty and mutual dependence. Task uncertainty refers to the level of uncertainty involved in the course of scientific inquiry. The task uncertainty is high in scientific frontiers where research is essentially exploratory in nature and there is a high amount of tacit knowledge involved, for example, scientific discoveries of high creativity. In contrast, the task uncertainty is low in areas where tasks are rountinized. Mutual dependence refers to the social and organizational dependencies between scientists and their competing peers. A combination of high task uncertainty and high mutual dependence will lead to original scientific discoveries, which will bring a substaintial degree of recognitions and reputations such as Nobel Prizes. A research area with intensified competitions is also likely to have a high retraction rate (Chen et al., 2013). A combination of low task uncertainty and high mutual dependence will result in specialization to maintain the tension between scientists with high mutual dependence while they work on routinized research.
A relatively new theory of the evolution of a scientific discipline is proposed by Shneider (2009). The evolution of a scientific discipline is divided into four stages. A new discipline, or more generically, a research specialty, begins with a conceptualization stage - Stage I. At this stage, the object of the research is established, for example, as in science mapping, the object of science mapping is a scientific knowledge domain. The goal of the new research is to answer a set of research questions concerning the newly identified target. The next stage, Stage II, is characterized by the development of research instruments, or tools, that will enable researchers to investigate the underlying phenomona. Once researchers are equipped with special purpose tools, the research moves to the third stage, Stage III, the investigation of the research questions supported by the newly developed enabling techniques. This is a prolific stage as many results are produced and the understanding of the research problems is substantially advanced. The deepened understanding and a thorough examination may reveal previously unknown phenomena. The need to address the previously unknown phenomena may lead to the emergence of another new line of research or a new research specialty. The original specialty may continue to investigate along the original research agenda. In addition, tools developed by the original specialty may find their way to contribute to the development of other subject domains. In other words, a Stage III specialty may contribute to a specialty in its own Stage II. The final stage of a specialty is Stage IV. The specialty at this stage is characterized by transferring tacit knowledge to condified and rountinized knowledge. Comprehensive textbooks are written. Accumulated domain knowledge is reviewed, synthesized, and conveyed to new comers to the specialty as well as the existing members of the specialty.
There are other theories of scientific change. For example, a transition model of Exploration →Unification →Decline/Displacement was proposed by Mulkay, Gilbert, and Woolgar (1975). Nevertheless, the three outlined above are represenative and they sufficiently cover the major characteristics of the development of a scientific field for the purpose of our systematic review.
We can see obvious overlaps as well as clear distinctions among them. For example, Shneider’s Stage III overlaps with Kuhn’s crisis stage. Fuchs’ high task uncertainty and high mutual dependence may characterize a Stage I specialty. As a specialty transits from Stage III to Stage IV, it may transform itself from a high-high uncertainty-dependence mode to a low-high mode. A specialty may start to decay and it may be forgotten, but it may be revitalized years later, as a sleeping beauty in the conceptual world (van Raan, 2003).
In addition to the four evoluationary stages, Shneider also proposes that each stage may suit a particular type of scientists better than other stage in terms of how a type of talent matches a particular stage. In fact, Shneider suggests that the better scientists understand the four stages of development the more effectively they may optimize their career path. In addition, Shneider emphasizes that researchers at different stages may not have the mindset that would enable them to evaluate a discipline at a different evolutionary stage.
In corresponding to the four stages, we may identify the most suitable scientists for each stage as creative thinkers, visioners, boundary spanners, or brokers for scientists who may excel at Stage I; inventors and tool builders for Stage II; adaptors and experimenters for Stage III; and sythesizers, codifiers, and educators for Stage IV. In this review, we will adopt Shneider’s four-stage model in our interpretation of the results.
3 Method
3.1 Data Collection
The input data of our review is generated by a combination of the results from multiple topic search queries to the Web of Science (Figure 1 ). The rationale of the query construction is as follows. First, we would like to ensure that currently widely used science mapping tools such as VOSViewer, CiteSpace, HistCite, SciMAT, and Sci2 are covered by our topic search query. Thus, publications that mention any of these software tools in their titles, abstracts, and/or keyword lists will be included. This query generates 135 records as Set #.
Second, since the goal of science mapping is to identify the intellectual structure of a scientific domain, the second query focuses on the object of science mapping, including topic terms such as intellectual structure, scientific change, research front, invisible college, and domain analysis. As we will see later on, terms such as domain analysis may be ambiguous as they are also used in other contexts that are irrelevant to science mapping. In practice, we recommend to defer the assessment of relevance until the analysis stage. This query produces 13,242 records as Set #2.
The third query focuses on scientometric and visual analytic techniques that are potentially relevant to science mapping. Topic terms include science mapping, knowledge domain visualization, information visualization, citation analysis, and co-citation analysis. This query leads to 4,772 records.
The queries #4-#10 aim to retrieve bibliographic records on the common data sources for science mapping, including Scopus (6,782 records), the Web of Science (15,401 records), Google Scholar (5,170 records), Pubmed (46,760 records), and Medline (61,405 records).
The final dataset is Set #14, containing 17,731 bibliographic records of the types of Article or Review in English. This query formation strategy is generic enough to be applicable to a science mapping study unless of course one has access to the entire database.
Patents and research grants are other types of data sources one may consider, but for this particular review, we are limited to the scientific literature indexed by the Web of Science.

Figure 1. Topic search queries used for data collection. |
3.2 Visualization and Analysis
We visualize and analyze the dataset with a new version of CiteSpace (5.0.R3 SE) (Figure 2 ). CiteSpace has been continuously developed to meet the needs for visual analytic tasks of science mapping. The new version will be released shortly to the public.
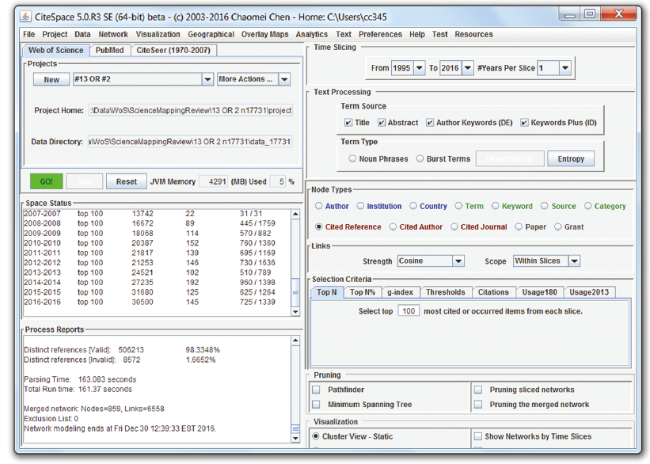
Figure 2. The main user interface of CiteSpace. |
CiteSpace takes a set of bibliographic records as its input and models the intellectual structure of the underlying domain in terms of a synthesized network based on a time series of networks derived from each year’s publications. CiteSpace supports several types of bibliometric studies, including collaboration network analysis, co-word analysis, author co-citation analysis, document co-citation analysis, and text and geospatial visualizations. In this study, we focus on the document co-citation analysis within the period of time between 1995 and 2016.
The Set #14 contains 16,250 records published in the range of 1980-2017 (Figure 3 ). These records collectively cited 515,026 references. The document co-citation analysis function in CiteSpace constructs networks of cited references. Connections between references represent co-citation strengths. CiteSpace uses a time slicing technique to build a time series of network models over time and synthesizes these individual networks to form an overview network for the systematic review of the relevant literature.
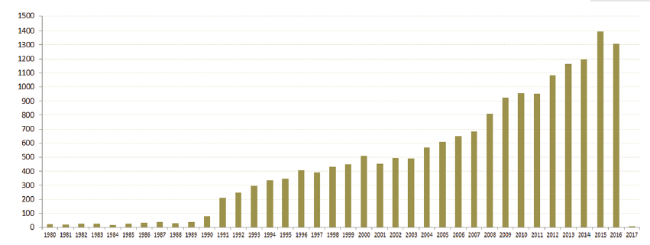
Figure 3. The distribution of the bibliographic records in Set #14. |
The synthesized network is divided into co-citation clusters of references. Citers to these references are considered as the research fronts associated with these clusters. Each cluster represents the intellectual base of the underlying specialty. According to Shneider’s four-stage model, the intellectual base of a specialty and the corresponding research fronts provide valuable insights into the current stage of the specialty as well as the intellectual milestones in the evolution of the specialty.
Our first step in the review is to make sense of the nature of major clusters and characteristics that may inform us about the stage of the underlying specialties. In this study, we consider a cluster as the embodiment of an underlying specialty. Thus, science mapping consists of multiple specialties that contribute to various aspects of the domain.
In each cluster, we focus on cluster members that are identified by structural and temporal metrics of research impact and evolutionary significance. A commonly used structural metric is the betweenness centrality of a node in a network. Studies have shown that nodes with high betweenness centrality values tend to identify boundary spanning potentials that may lead to transformative discoveries (Chen et al., 2009). Burst detection is a computational technique that has been used to identify abrupt changes of events and other types of information (Kleinberg, 2002). In CiteSpace, the sigma score of a node is a combinant metric of the betweenness centrality and the citation burstness of the node, i.e. the cited reference. CiteSpace represents the strength of these metrics through the design of visual encoding such that articles that are salient in terms of these metrics will be easy to see in the visualizations. For example, the citation history of a node is depicted as a number of treerings and each treering represents the number of citations received in the corresponding year of publication. If a citation burst is detected for a cited reference, the corresponding treering will be colored in red. Otherwise, treerings will be colored by a spectrum that ranges from cold colors such as blue to warm colors such as orange.
The nature of a cluster is identified from the following aspects: a hierarchy of key terms in articles that cite the cluster (Tibély et al., 2013), the prominent members of the cluster as the intellectual milestones in its evolution and as the intellectual base of the specialty, recurring themes in the citing articles to the cluster to reflect the interrelationship between the intellectual base and the research fronts. In particular, we will pay attention to indicators of the evolutionary stages of a specialty such as the original conceptualization, research instruments, applications, and routinization of the domain knowledge of the specialty.
In addition to the study of citation-based patterns, we will demonstrate the concept of citation trajectories in the context of distinct clusters. According to the theory of structural variation, the transformative potential of an article may be reflected by the extent to which it varies the existing intellectual structure (Chen, 2012). For example, if an article adds many inter-cluster links, it may alter the overall structure. If the structural change is subsequently accepted and reinforced by other researchers, then transformative changes of the knowledge become significant in a socio-cognitive view of the domain.
4 Results
A dual-map overlay of the science mapping literature represents the entire dataset in the context of a global map of science generated from ove 10,000 journals indexed in the Web of Science (Chen & Leydesdorff, 2014). The dual-map overlay shows that science mapping papers are published in almost all major disciplines (Figure 4 ). Publications in the discipline of information science (shown in the map as curves in cyan) are built on top of at least four disciplines on the right-hand side of the map.

Figure 4. A dual-map overlay of the science mapping literature. |
A hierarchical visualization of index terms, i.e. keywords, is generated to represent the coverage of the dataset (Figure 5 ). Five semantic types of nodes are annotated in the visualized hierarchy:

These semantic types will be also used to identify the evolutionary stage of a specialty. For example, if a cluster contains several articles that report the development of software tools, then the underlying specialty is considered as a specialty that has reached at least Stage II. If the methodologies appear in a cluster of knowledge domains external to information science, such as regenerative medicine and strategic management research, then we will consider the specialty has reached Stage III - tools developed by the specialty are applied to other subject domains. In the following analysis, we will use the terms in the hierarchy as the primary source of our vocabulary to identify the role of the contributions made by a scientific publication to a specialty.
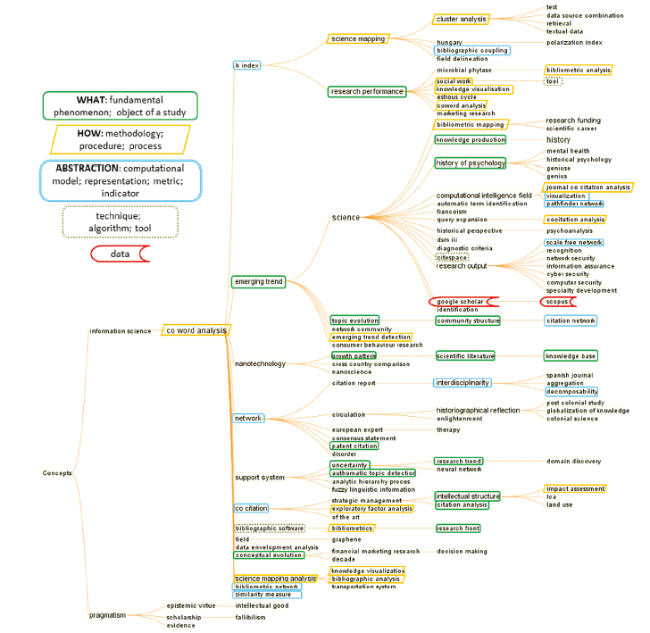
Figure 5. A hierarchy of index terms derived from Set #14. |
Major milestones in the development of science mapping can be identified from the list of references that have strong citation bursts between 1995 and 2016 (Figure 6 ). References with strong values in the Strength column tend to be significant milestones for the science mapping research. We label such references with high-level concepts. For example, the first milestone paper in the study is a landmark ACA study of information science (White & McCain, 1998). The next milestone is a major collection of seminal papers in information visualization (Card, Mackinlay, & Shneiderman, 1999). Other major milestones include visual analytics (Thomas & Cook, 2005), and the h-index (Hirsch, 2005).
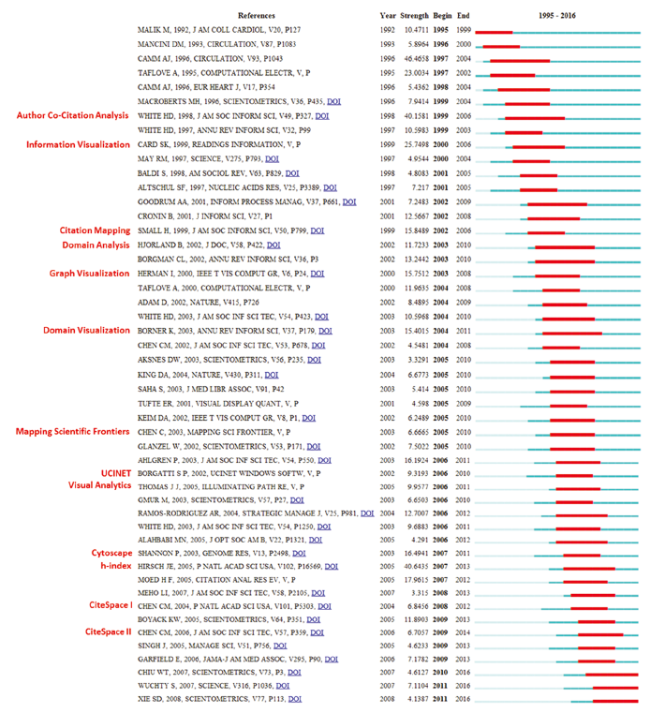
Figure 6. 49 references with citation bursts of at least 5 years. |
4.1 Landscape View
The following landscape view is generated based on publications between 1995 and 2016 (Figure 7 ). Top 100 most cited publications in each year are used to construct a network of references cited in that year. Then individual networks are synthesized. The synthesized network contains 3,145 references. The network contains 603 co-citation clusters. The three largest connected components include 1,729 nodes, which account for 54% of the entire network. The network has a modularity of 0.8925, which is considered as very high, suggesting that the specialties in science mapping are clearly defined in terms of co-citation clusters. The average silhouette score of 0.3678 is relative low mainly because of the numerous small clusters. The major clusters that we will focus on in the review are sufficiently high.
The areas of different colors indicate the time when co-citation links in those areas appeared for the first time. Areas in blue were generated earlier than areas in green. Areas in yellow were generated after the green areas and so on. Each cluster can be labled by title terms, keywords, and abstract terms of citing articles to the cluster. For example, the yellow-colored area at the upper right quadrant is labeled as #3 information visualization, indicating that Cluster #3 is cited by articles on information visualization. The largest node is the paper that introduces the h-index. Other nodes with red treerings are references with citation bursts (Figure 7 ).
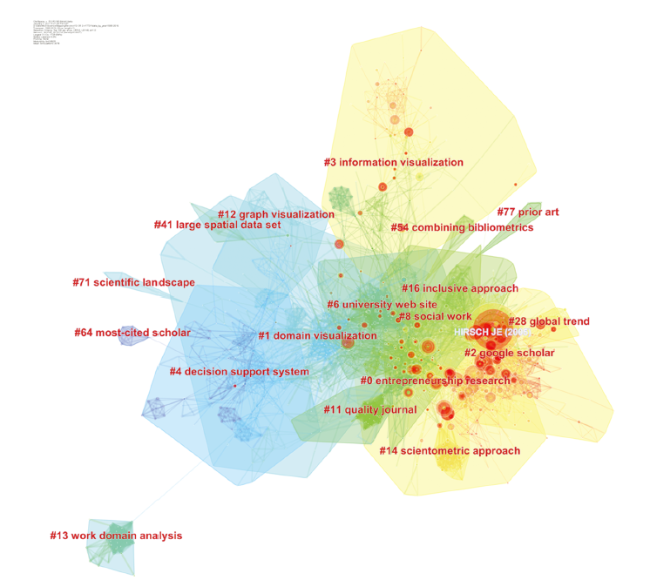
Figure 7. A landscape view of the co-citation network, generated by top 100 per slice between 1995 and 2016 (LRF = 3, LBY = 8, and e = 1.0). |
4.2 Timeline View
A timeline visualization in CiteSpace depicts clusters along horizontal timelines (Figure 8 ). Each cluster is displayed from left to right. The legend of the publication time is shown on top of the view. The clusters are arranged vertically in the descending order of their size. The largest cluster is shown at the top of the view. The colored curves represent co-citation links added in the year of the corresponding color. Large-sized nodes or nodes with red treerings are of particular interest because they are either highly cited or have citation bursts or both. Below each timeline the three most cited references in a particular year are displayed. The label of the most cited reference is placed at the lowest position. References published in the same year are placed so that the less cited references are shifted to the left. The new version of CiteSpace supports the function to generate labels of a cluster year by year based on terms identified by Latent Semantic Indexing (LSI) (Deerwester et al., 1990). The year-by-year labels can be displayed in a table or above the corresponding timeline. Users may control the displays interactively.
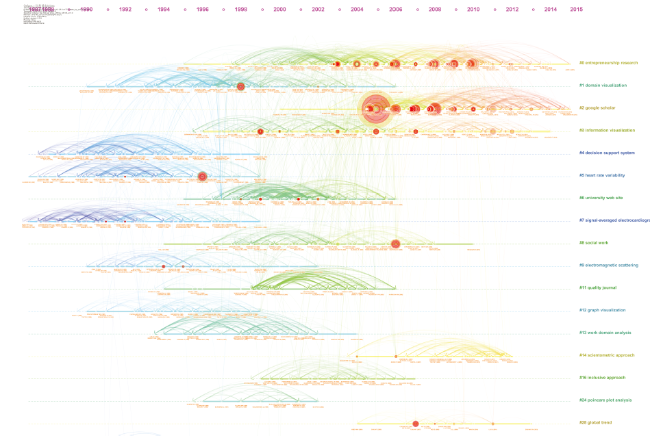
Figure 8. A timeline visualization of the largest clusters of the total of 603 clusters. |
Clusters are numbered from 0, i.e. Cluster #0 is the largest cluster and Cluster #1 is the second largest one. As shown in the timeline overview, the sustainability of a specialty varies. Some clusters sustain a period over 20 years, whereas some clusters are relatively short-lived. Some clusters remain active until 2015, the most recent year of publication for a cited reference in this study.
Each of the largest five clusters has over 150 members (Table 1 ). The largest cluster’s homogeneity in terms of the silhouette score is slightly lower than that of the smaller clusters. The largest cluster represents 4.5% of the references from the entire network and 8.1% of the largest three connected components of the network (LCCs). In this study, our review will primarily focus on the largest five clusters.
Table 1 The five largest clusters of co-cited references of the network of 3,145 references. The largest three connected components include 1,729 of the references. |
| Cluster | Size | Mean (year) | Silhouette | % of the network | Accumulated % of the network | % of top 3 LCCs | Accumulated % of LCCs |
|---|---|---|---|---|---|---|---|
| 0 | 214 | 2006 | 0.748 | 4.5 | 4.5 | 8.1 | 8.1 |
| 1 | 209 | 1997 | 0.765 | 2.3 | 6.7 | 4.1 | 12.2 |
| 2 | 190 | 2009 | 0.845 | 3.3 | 10.0 | 6.0 | 18.2 |
| 3 | 160 | 2005 | 0.954 | 2.9 | 12.9 | 5.3 | 23.5 |
| 4 | 152 | 1992 | 0.890 | 1.7 | 14.6 | 3.0 | 26.5 |
The duration of a cluster is particularly interesting (Table 2 ). The largest cluster lasts 21 years and it is still active. Cluster #3 spans a 19-year period and also remains to be active. In contrast, Cluster #6 on webometrics ends by 2006, but as we will see, relevant research finds its way in new specialties, notably in the form of altmetrics.
Table 2 Temporal properties of major clusters. |
| Cluster ID | Size | Silhouette | From | To | Duration | Median | Sustainability | Activeness | Theme |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 214 | 0.748 | 1995 | 2015 | 21 | 2006 | ++++++ | Active | Science mapping |
| 1 | 209 | 0.765 | 1990 | 2006 | 17 | 1997 | ++ | Inactive | Domain analysis |
| 2 | 190 | 0.845 | 2000 | 2015 | 16 | 2009 | Active | Research evaluation | |
| 3 | 160 | 0.954 | 1996 | 2014 | 19 | 2005 | ++++ | Active | Information visualization / Visual analytics |
| 4 | 152 | 0.890 | 1988 | 1999 | 12 | 1993 | Inactive | Applications of ACA | |
| 6 | 125 | 0.925 | 1995 | 2006 | 12 | 2001 | Inactive | Webometrics | |
| 8 | 93 | 0.882 | 1994 | 2010 | 17 | 2002 | ++ | Inactive | Bibliometric studies of social work in health |
| 11 | 48 | 0.965 | 1994 | 2006 | 13 | 2000 | Inactive | Bibliometric studies of management research | |
| 12 | 44 | 0.966 | 1990 | 1999 | 10 | 1996 | Inactive | Graph visualization | |
| 16 | 29 | 0.977 | 1999 | 2007 | 9 | 2003 | Inactive | Bibliometric studies of information systems | |
| 28 | 15 | 0.995 | 2004 | 2013 | 10 | 2008 | Inactive | Global trend; Water resources |
4.3 Major Specialties
In the following discussion, we will particularly focus on the five largest clusters (Table 1 ). A research programme, or a paradigm, in a field of research can be characterized by its intellectual base and research fronts. The intellectual base is the collection of scholarly works that have been cited by the corresponding research community, whereas research fronts are the works that are inspired by the ones of the intellectual base. A variety of research fronts may rise from a common intellectual base.
4.3.1 Cluster #0 - Science Mapping
Cluster #0 is the largest cluster, containing 214 references across a 21-year period from 1995 till 2015 (Table 2 ). The median year of all references in this cluster is 2006, but the median year of the 20 most representative citing articles to this cluster is 2010. This cluster’s silhouette value of 0.748 is the lowest among the major clusters, but this is generally considered a relatively high level of homogeneity.
The primary focus of the large and currently active cluster is on the intellectual structure of a scientific discipline, a field of research, or any sufficiently self-contained domain of scientific inquiry. Key concepts identified from the titles
of citing articles to this cluster can be algorithmically organized according to hierarchical relations derived from co-occurring concepts (Figure 9 ). The largest branch of such a hierarchy typically reflects the core concepts of scholarly publications produced by the specialty behind the cluster. For example, concepts such as intellectual structure, co-citation analysis, and co-authorship network underline the primary interest of this specialty.
of citing articles to this cluster can be algorithmically organized according to hierarchical relations derived from co-occurring concepts (

Figure 9. A hierarchy of key concepts selected from citing articles of Cluster #0 by log-likelihood ratio test. |
We can use a simple method to classify various terms into two broad categories: domain-intrinsic or domain-extrinsic. Domain-intrinsic terms belong to the research field that aims to advance the conceptual and methodological capabilities of science mapping, for example, intellectual structure and co-citation analysis. In contrast, domain-extrinsic terms belong to the domain to which science mapping techniques are applied. In other words, they belong to the domain that is the object of a science mapping study. For example, stem cell research per se may not directly influence the advance of a specialty that is mainly concerned with how to identify the intellectual structure of a research field from scientific literature. Information science has a unique position. On the one hand, it is the discipline that hosts a considerable number of fields relevant to science mapping. On the other hand, it is the most frequent choice of a knowledge domain to test drive newly developed techniques and methods.
The timeline visualization reveals three periods of its development (Figure 10 ). The first period is from 1995 to 2002. This period is relatively uneventful without high-profile references in terms of citation counts or bursts. Two visualization-centric domain analysis articles (Boyack, Wylie, & Davidson, 2002; Chen et al., 2002), preluded the subsequent wave of high-impact studies appeared in the second period. This period also features a social network analysis tool UCINET (Borgatti, Everett, & Freeman, 2002).

Figure 10. High-impact members of Cluster #0 |
The second period is from 2003 to 2010. Unlike the first period, the second period is full of high-impact contributions - large citation treerings and periods of citation bursts colored in red. Several types of high-impact contributions appeared in this period, notably:

The third period is from 2011 to 2015. Although no citation bursts were detected so far in this period, the themes of this period shed additional insights into the more recent developmental status of the specialty. Most cited publications in this period include a study of the cognitive structure of library and information science (Milojević et al., 2011) and a few studies that focus on domains with no apparent overlaps with computer and information science, for example regenerative medicine (Chen, Dubin, & Kim, 2014; Chen et al., 2012) and strategic management (Vogel & Güttel, 2013).
A specialty may experience the initial conceptualization stage, the growth of research capabilities through the fourish of research tools, the expansion stage when researchers apply their methods to subject domains beyond the original research problems, and the final stage of decay (Shneider, 2009). The largest cluster is dominated by an overwhelming number of tool-related references. The top 20 most cited members of the cluster include several software tools such as CiteSpace (Chen, 2006; Chen et al., 2010), UCINET (Borgatti et al., 2002), VOSViewer (van Eck & Waltman, 2010), and global maps of science (Leydesdorff & Rafols, 2009) (Figure 11 ). In terms of the four-stage evolution model of Shneider, the underlying specialty evidently reached Stage II - the tool building stage by 2010.
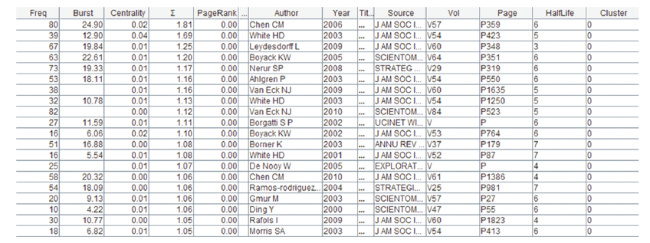
Figure 11. Top 20 most cited references in the largest cluster. |
The cluster also includes several author co-citation studies of disciplines and research areas such as information science (Chen et al., 2010; White, 2003) and strategic management (Nerur, 2008; Ramos-rodriguez, 2004). White (2003) revisits the intellectual structure of information science. Instead of using multidimensional scaling technique as they did in a previous study of the domain, the new study applied the Pathfinder network scaling technique and demonstrated the advantages of the technique. Pathfinder network scaling was first introduced to author co-citation analysis in (Chen, 1999b). Although the studies of strategic management research can be seen as applications outside the original specialty of author co-citation analysis, studies of information science typically involve the development of new tools as well as applications of existing tools.
Articles that cited members of the cluster convey additional information for us to understand the dynamics of the specialty. The top 20 citing articles ranked by the bibliographic overlap with the cluster reveal similar types of contributions, namely software tools and techniques (1, 2, 5, 8, 14), new methods (9, 11, 16, 19, 20), surveys and reviews (3, 10, 13), and applications of bibliometric studies (6, 12, 17) (Figure 12 ).

Figure 12. Major citing articles to the largest cluster. |
The timeline visualization suggests that the specialty represented by the largest cluster has cumulated sufficient research techniques and tools by the end of the third period and that the specialty is likely in Stage III of its evolution. In other words, the specialty is currently dominated by the need to apply these new techniques to a broader range of scientific domains and address research questions at new levels. According to Shneider’s four-stage model, Stage III is also the evolutionary stage when the specialty may encounter discoveries that could change the course of the development of the specialty.
At a more pragmatic level, one may monitor the further development of the specialty by tracking research fronts that are built on the early stages of the specialty. One can monitor emerging trends and patterns in terms of the major dimensions in the latent semantic space spanned by each year’s publications connected to this particular cluster. For example, the growing number of domain-extrinsic terms such as nanotechnology, case study, and solar cell suggest an expansion of the research scope - a hallmark of a Stage III specialty.
4.3.2 Cluster #1 - Domain Analysis
Cluster #1 is the second largest cluster, containing 209 references that range a 17-year duration from 1990 to 2006. The cluster, or its underlying specialty, is largely inactive with reference to the resolution of this study. This cluster is dominated by representative terms such as information retrieval, domain analysis, scholarly communication, and intellectual space (Figure 13 ). Although information retrieval is the root node in the hierarchy of key terms in this cluster, domain analysis underlines the conceptual fundation of this cluster, as we will see shortly.

Figure 13. A hierarchy of key concepts in Cluster #1. |
Two outstanding references from the timeline visualization of this cluster have strong citation burstness (Figure 14 ). One is a doman analysis of information science (White & McCain, 1998), in which the multidimensional scaling of an author co-citation space was utilized to visualize the intellectual structure of the domain. The other is a study of major approaches to domain analysis (Hjørland, 2002). In early 1990s, Hjørland developed a domain-analytic apporach, also known as socialogical-epistemological approach or a socio-cognitive view, as a methodological alternative to the then methodological individualism and cognitive perspective toward information science that largely marginalized the social, historical, and cultural roles in understanding a domain of scientific knowledge. Hjørland’s another article on domain analysis is also a member of the cluster (Hjørland, 1997).
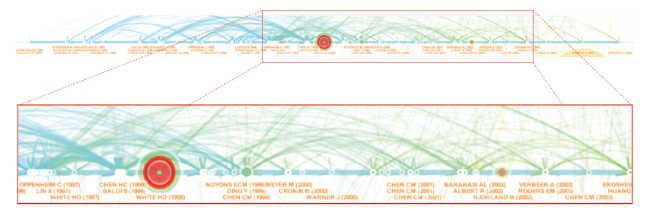
Figure 14. Key members of Cluster #1. |
The sigma score of a cited reference reflects its structural and temporal significance. In addition to the author co-citation analysis of information science (White & McCain, 1998), two more author co-citation studies are ranked highly by their
sigma scores, namely an author co-citation study of information retrieval (Ding, Chowdhury, & Foo, 1999), and an author co-citation study of hypertext (Chen, 1999b) (Figure 15 ).
sigma scores, namely an author co-citation study of information retrieval (Ding, Chowdhury, & Foo, 1999), and an author co-citation study of hypertext (Chen, 1999b) (
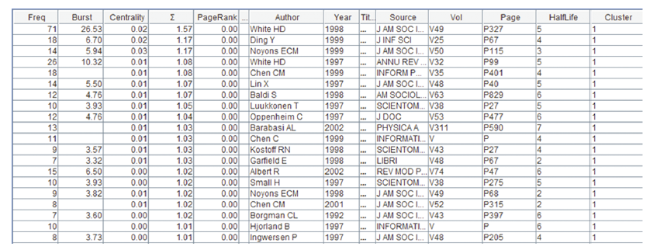
Figure 15. Key members of Cluster #1, sorted by sigma. |
The review article by White and McCain (1997) on “visualization of literature” is an important member of the cluster, whereas Tabah’s review of the study of literature dynamics (Tabah, 1999) is a citing article to the cluster. Although the term domain analysis was not used consistently during the period of this cluster, the contributions consistently focus on holistic views of a knowledge domain. As Hjørland argued, domain analysis serves a fundamental role in information science because its goal is to understand the subject matter from a holistic view of sociological, cognitive, historical, and epistemological dimensions.
Citing articles to Cluster #1 include some of the earliest attempts to integrate information visualization techniques to the methodology of a domain analysis (Börner et al., 2003; Boyack, Wylie, & Davidson, 2002; Chen et al., 2002) (Figure 16 ). Interestingly, some of these citing articles appear as cited references in Cluster #0. In other words, the downturn of Cluster #1 does not mean that researchers lost their interest in the domain analysis approaches. Rather, they shifted their focus to explore a new generation of domain analysis with the support of a variety of computational and visualization techniques. As a result, the specialty underlining Cluster #0 continues the vision conceived in the works of Cluster #1. The citers of Cluster #1 identify the group of researchers who would be the core members of the specialty of the new generation of domain analysis.

Figure 16. Citing articles to Cluster #1. |
Author co-citation analysis (ACA) plays an instrumental role in the development of the domain analysis specialty embodied in Cluster #1. It is not only a bibliometric method that has been adopted by researchers beyond information science, but also a research instrument that helps to reveal challenges that the next generation of domain analysis must deal with.
In their ACA study of information science, White and McCain (1998) masterfully demonstrated the power and the potential of what one may learn from a holistic view of the intellectual landscape of a discipline. They utilized the multidimensional scaling technique as a vehicle for visualization and tapped into their encyclopedic knowledge of the information science discipline in an intellectually rich guided tour across the literature. In an attempt to enrich and enhance the conventional methodology of ACA, Chen (1999b) introduced the Pathfinder network scaling technique. Using Pathfinder networks brings several advantages to the methodology of ACA, including the ability to identify and preserve salient structural patterns and algorithmically derived visual cues to assist the navigation and interpretation of resultant visualizations (Chen & Morris, 2003). White (2003) revisited the ACA study of information science with Pathfinder network scaling. A fast algorithm to compute Pathfinder networks is published in 2008 (Quirin et al., 2008).
The re-introduction of the network thinking opens up a wider variety of computational techniques to an ACA study, notably network modeling and visualization. Furthermore, technical advances resulted from the improvement of ACA have been applied to a broader range of biliometric studies, notably document co-citation analysis (DCA) (Chen, 2004; Small, 1973; 1999). As we will see shortly, the adaptation of network modeling and information visualization techniques in general results from a Stage III specialty of information visualization and visual analytics.
4.3.3 Cluster #2 - Research Evaluation
Cluster #2 is the third largest cluster with 190 cited references and a silhouette value of 0.845, which is slightly higher than the previous two larger clusters #0 and #1, suggesting a higher homogeneity. In other words, one would consider this specialty a more specialized than the previously identified specialties. This cluster is active over a 16-year period from 2000 till 2015. It represents an active specialty.
The overarching theme of the cluster is suggested by the two major branches shown in the hierarchy of key terms of this cluster: the information visualization branch and the much larger branch of research evaluation (Figures 17 & 18). The information visualization branch highlights the recurring themes of intellectual structure and co-citation analysis. The research evaluation branch highlights numerous concpets that are central to measuring scholarly impact, notably h-index, bibliometric ranking, bibliometric indicator, sub-field normalization, Web indicator, citation distribution, social media metrics, and alternative metrics.
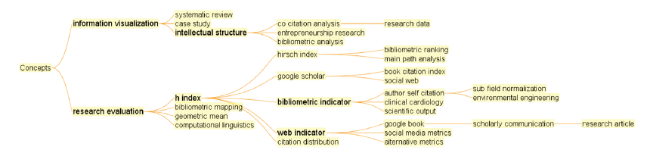
Figure 17. A hierarchy of key concepts in Cluster #2. |
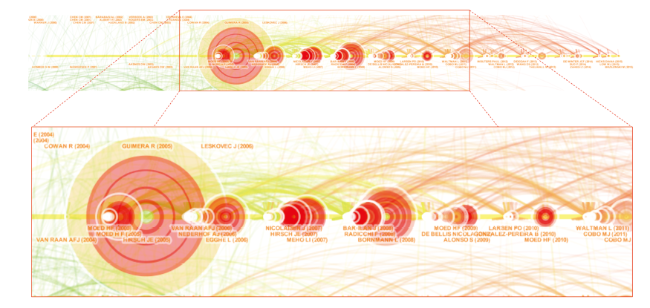
Figure 18. High-impact members of Cluster #2. |
The six-year period from 2005 through 2010 is a highly active period of the cluster (Figure 19 ). The most prominent contributions in this period include the original article that introduces the now widely known h-index (Hirsch, 2005),
the subsequent introduction of g-index as a refinement by taking citations into account (Egghe, 2006), a 2007 study that compares the impact of using the Web of Science, Scopus, and Google Scholar on citation-based ranking (Meho & Yang, 2007), a 2008 review entitled “What do citation counts measure?” (Bornmann & Daniel, 2008), and a study of the universality of citation distributions (Radicchi, Fortunato, & Castellano, 2008). These papers are also among the top sigma ranked members of this cluster because of their structural centrality as well as the strength of their citation burstness.
the subsequent introduction of g-index as a refinement by taking citations into account (Egghe, 2006), a 2007 study that compares the impact of using the Web of Science, Scopus, and Google Scholar on citation-based ranking (Meho & Yang, 2007), a 2008 review entitled “What do citation counts measure?” (Bornmann & Daniel, 2008), and a study of the universality of citation distributions (Radicchi, Fortunato, & Castellano, 2008). These papers are also among the top sigma ranked members of this cluster because of their structural centrality as well as the strength of their citation burstness.
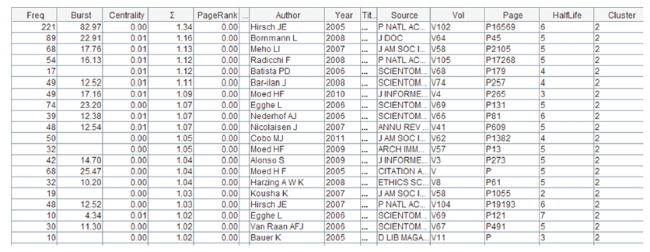
Figure 19. High-impact members of Cluster #2. |
The top 20 citing articles of the cluster reveal a considerable level of thematic consistency (Figure 20 ). The overarching theme of research evaluation is evidently behind all these articles with popular title terms identified by latent semantic indexing such as citation impact, scientific impact, impact measures, bibliometric indicators, research evaluation, and Web indicators.

Figure 20. Citing articles of Cluster #2. |
Some of the more recent and highly cited members in Cluster #2 include a comparative study of 11 altmetrics and counterpart articles matched in the Web of Science (Thelwall et al., 2013), the Leiden manifesto for research metrics (Hicks
et al., 2015), and a study of power law properties in citation distributions based on over 6 millions of Scopus records (Brzezinski, 2015).
et al., 2015), and a study of power law properties in citation distributions based on over 6 millions of Scopus records (Brzezinski, 2015).
4.3.4 Cluster #3 - Information Visualization and Visual Analytics
Cluster #3 is the fourth largest cluster. Its duration ranges from 2004 through 2014. The topic hierarchy has two branches: information visualization and heart rate variability (Figures 21 & 22). The heart rate variability does not belong to the domain analysis in the context of information science. In fact, its inclusion in the original results of the topic search was due to the ambiguity of the term domain analysis across multiple disciplines. Pragmatically it is easier and more efficient to simply skip an irrelevant branch than keep refining the original topic search query untill all noticeable irrelevant topics are eliminated. This is one of the foundamental challenges for information retrieval and this is where domain analysis has an instrumental role to play (Hjørland, 2002).
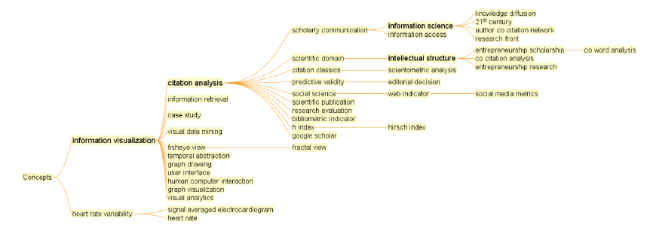
Figure 21. A hierarchy of key concepts in Cluster #3. |

Figure 22. High-impact members of Cluster #3. |
The information visualization branch includes a mixture of information visualization techniques such as fisheye view, group drawing, graph visualization, and visual analytics and topics that are center to information science such as citation analysis and information retrieval. The mixture is a sign of attempts to apply information visualization and visual analytic techniques to bibliometric approaches to the study of intellectual structure of a research domain. The vision of information visualization is to identify insightful patterns from abstract information (Card, Mackinlay, & Shneiderman, 1999; Chen, 2005; Chen, 2010). The subsequently emerged visual analytics emphasizes the critical and more specific role of sense-making and analytic reasoning in accomplishing such goals (Chen, 2008; Keim et al., 2008; Thomas & Cook, 2005).
High-impact contributions in Cluster #3 include the collection of seminal works in information visualization (Card, Mackinlay, & Shneiderman, 1999), a survey of graph visualization techniques (Herman, Melançon, & Marshall, 2000), Cytoscape - a widely used software tool for visualizing biomolecular interaction networks (Shannon et al., 2003), the ground breaking work of visual analytics (Thomas & Cook, 2005), Many Eyes - the popular Web-based visualization platform (Viégas et al., 2007), and a framework of seven types of interaction techniques in information visualization (Yi et al., 2007) (Figure 23 ).
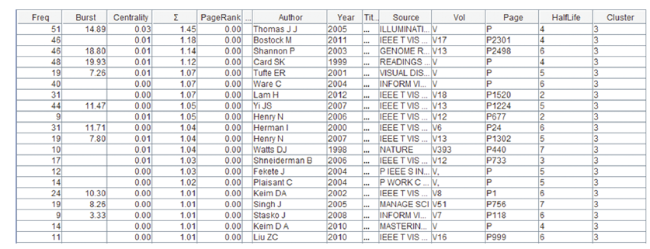
Figure 23. Key members of Cluster #3. |
In addition to the above high-impact contributions, this cluster features information visualization tools such as the InfoVis toolkit (Fekete, 2004), NodeTrix (Henry, Fekete, & McGuffin, 2007), Jigsaw - a visual analytic tool (Stasko, Gorg, & Liu, 2008), and D3 (Bostock, Ogievetsky, & Heer, 2011). The most widely used information visualization tools such as Many Eyes and D3 became available between 2007 and 2011 (Figure 24 ).

Figure 24. Citing articles of Cluster #3. |
According to Shneider’s four-stage model, the information visualization and visual analytics specialty in the context of domain analysis and literature visualization has demonstrated properties of a Stage IV specialty. For example, in the most recent few years of the cluster, researchers reflect on empirical evaluations of information visualization in various scenarios (Lam et al., 2012), revisit taxonomic organizations of abstract visualization tasks (Brehmer & Munzner, 2013), and synthesize and codify domain knowledge in the forms of textbooks (Munzner, 2014).
4.3.5 Remaining Clusters
The remaining clusters are either relatively small in size or short in terms of the length of their duration. We will omit detailed discussions of these clusters. Readers may refer to supplementary materials provided on the project website. We outline a few more relevant clusters as follows.
Cluster #4 focuses on applications of bibliometric studies to research domains such as decision support systems and information retrieval studies. Top cited references in this cluster are mostly articles published in the early 1990s.
Cluster #6 focuses on webometrics, led by an article on methodological approaches to webometrics (Almind & Ingwersen, 1997). This cluster was active during the period between 1995 and 2006. The leading contributors of this specialty such as Mike Thelwall continue to make active contributions to Cluster #2 Research Evaluation, especially in association with the development of altmetrics. A review of scholarly communication and bibliometrics by Borgman and Furner (2002) is also a key member of this cluster.
4.4 Trajectories of Citations across Cluster Boundaries
Cluster analysis helps us to understand the major specialties associated with science mapping. Now we turn our attention to the trajectories of several leading contributors in the landscape of these clusters. We are interested in what we may learn from citation links made in publications of a scholar, especially those links bridging distinct clusters.
4.4.1 Trajectories of Prolific Authors
The first example is the citation trajectory of Howard White (Figure 25 left). He is the author of several seminal papers featured in several clusters. His citation trajectories move across the citation landscape from the left to the center, ranging from #4 decision support system (applications of ACA), #1 domain visualization (domain analysis), and #8 social work (another cluster of bibliometric studies).
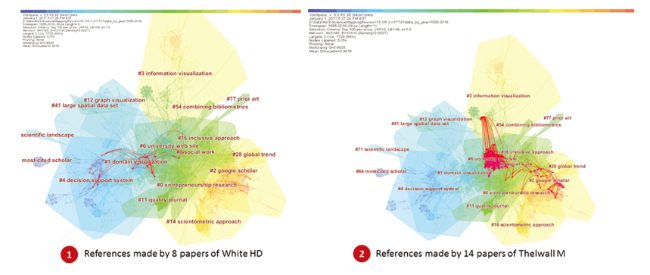
Figure 25. Novel co-citations made by 8 papers of White (left) and by 14 papers of Thelwall (right). |
The second example is the citation trajectory of Mike Thelwall (Figure 25 right). He is a prolific researcher who contributed to webometrics and altmetrics among other areas of bibliometrics. An overlay of his citation trajectories on a citation landscape view shows that his trajectories spanning clusters such as #6 university websites (webometrics) and # google scholar (research evaluation).
In both examples of citatoin trajectories, we have observed that their citation trajectories span across a wide area over the citation landscape. Monitoring the movement of citation trajectories in such a way provides an intuitive insight into the evolution of the underlying specialties and the context in which high-impact researchers make their contributions.
4.4.2 Articles with Transformative Potentials
It is widely known that a major limitation of any citation-based indicators is their reliance on citations accumulated over time. Thus, citation-based indicators are likely to overlook newly published articles. An alternative method is to focus on the extent to which a newly published article brings to the conceptual structure of the knowledge domain of interest (Chen, 2012). The idea is to identify the potential of an article to make extrordinary or unexpected connections across distinct clusters. According to theories of scientific discovery, many significant contributions are resulted from boundary spanning ideas.
Table 3 Potentially transformative papers published in recent years (2012-2016). |
| Year | ∆M | ∆CLw | CKL | Geometric Mean | GC | Title | Reference |
|---|---|---|---|---|---|---|---|
| 2016 | 6.0541 | 0.0152 | 0.0251 | 0.1322 | 5 | A review of the literature on citation impact indicators | (Waltman, 2016) |
| 2016 | 0.9235 | 0.0019 | 0.3407 | 0.0842 | 0 | How are they different? A quantitative domain comparison of information visualization and data visualization (2000-2014) | (Kim, Zhu, & Chen, 2016) |
| 2016 | 0.8207 | 0.0017 | 0.0640 | 0.0447 | 2 | A bibliometric analysis of 20 years of research on software product lines | (Heradio et al., 2016) |
| 2015 | 1.7498 | 0.0073 | 0.0380 | 0.0786 | 0 | Global ontology research progress: A bibliometric analysis | (Zhu et al., 2015) |
| 2015 | 1.9873 | 0.0052 | 0.0397 | 0.0743 | 9 | Bibliometric methods in management and organization | (Zupic, 2015) |
| 2015 | 1.9906 | 0.0029 | 0.0238 | 0.0516 | 13 | A review of theory and practice in scientometrics | (Mingers & Leydesdorff, 2015) |
| 2014 | 1.6240 | 0.0087 | 0.0434 | 0.0850 | 3 | Research dynamics: Measuring the continuity and popularity of research topics | (Yan, 2014) |
| 2014 | 1.1837 | 0.0031 | 0.0463 | 0.0554 | 1 | Making a mark: A computational and visual analysis of one researcher’s intellectual domain | (Skupin, 2014) |
| 2014 | 0.4462 | 0.0024 | 0.0270 | 0.0307 | 12 | The knowledge base and research front of information science 2006-2010: An author cocitation and bibliographic coupling analysis | (Zhao & Strotmann, 2014) |
| 2013 | 2.5398 | 0.0112 | 0.0643 | 0.1223 | 13 | Analysis of bibliometric indicators for individual scholars in a large data set | (Radicchi & Castellano, 2013) |
| 2013 | 1.0781 | 0.0065 | 0.2180 | 0.1152 | 6 | A visual analytic study of retracted articles in scientific literature | (Chen et al., 2013) |
| 2013 | 1.7978 | 0.0064 | 0.0542 | 0.0854 | 24 | Quantitative evaluation of alternative field normalization procedures | (Li et al., 2013) |
| 2012 | 3.6274 | 0.0107 | 0.0811 | 0.1466 | 29 | SciMAT: A new science mapping analysis software tool | (Cobo et al., 2012) |
| 2012 | 3.4380 | 0.0248 | 0.0259 | 0.1302 | 15 | A forward diversity index | (Carley & Porter, 2012) |
| 2012 | 1.0719 | 0.0032 | 0.0321 | 0.0479 | 11 | Visualizing and mapping the intellectual structure of information retrieval | (Rorissa & Yuan, 2012) |

Figure 26. Three examples of articles with high modularity change rates: 1) (Waltman, 2016), 2) (Zupic, 2015), and 3) (Zhu et al., 2015). |
These highly ranked articles represent a few types of studies that may serve as predictive indicators, namely review papers (Mingers & Leydesdorff, 2015; Waltman, 2016), applications of bibliometric studies to specific domains, software tools for science mapping (Cobo et al., 2012), new metrics and indicators (Li et al., 2013), and visual analytic studies of unconventional topics - retractions (Chen et al., 2013).
4.5 The Emergence of a Specialty
The emergence of a specialty is determined by two factors: the intellectual base and the research fronts associated with the intellectual base. The intellectual base is what the specialty cites, whereas the research fronts are what the specialty is currently addressing. As we have seen, on the one hand, a research front may remain in the same co-citation cluster as in the case of Cluster #2 Research Evaluation. On the other hand, a research front may belong to a different specialty and become the intellectual base of a new specialty as in the case of Cluster #1 Domain Analysis and Cluster #0 Science Mapping.
The citation trajectories of a researcher’s publications and the positions of these publications as cited references can be simultaneously shown by overlaying trajectories (dashed lines for novel links or solid lines for existing links) and citing papers as stars if they also appear in a co-citation cluster as cited references. For example, the series of stars in the following visualization tell us two things: First, the author is connecting topics in two clusters (Cluster #0 Science Mapping and Cluster 2 Research Evaluation) and second, the author belongs to the specialty of science mapping (Figure 27 ).
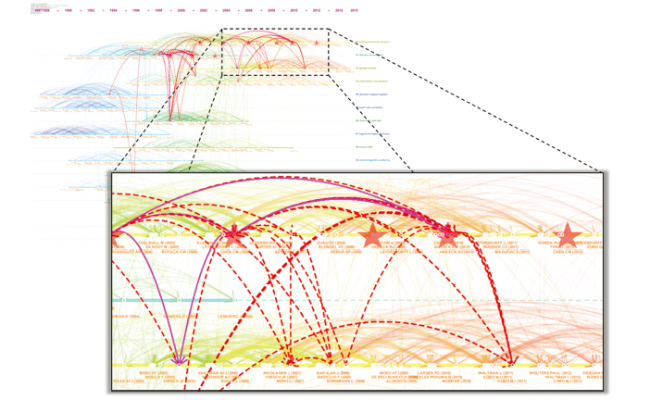
Figure 27. Stars indicate articles that are both cited and citing articles. Dashed lines indicate novel co-citation links. Illustrated based on 15 papers of the author’s own publications. |
The example below illustrates the citation trajectories of Howard White’s publications and their own positions in the timelines of clusters (Figure 28 ). His publications appear in the early stage of the science mapping cluster (#0) and make novel connections between science mapping and domain analysis (Cluster #1), domain analysis (Cluster #1) and applications of ACA (Cluster #4), domain analysis (Cluster #1) and webometrics (Cluster #6).
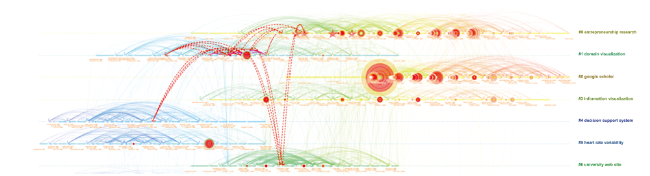
Figure 28. Citation trajectories of Howard White’s publications and their own locations. |
The next example depicts the novel co-citation links made by a review paper of informetrics (Bar-Ilan, 2008) (Figure 29 ). These novel links include within-cluster links as well as between-cluster links. It should be easy to tell that the scope of the review is essentially limited to research papers published about six to seven years prior to the time of the review. Furthermore, we can see that the review systematically emphasizes the diversity of topics instead of tracing to the origin of any particular specialty.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 29. Novel links made by a review paper of informetrics (Bar-Ilan, 2008). |
5 Discussions and Conclusions
We present a visual domain analysis of the science mapping research. Our intention is twofolds. First, our goal is to demonstrate the depth of a systematic review that one can reach by applying a science mapping approach to itself. In addition to the application of computational functions available in the new version of the CiteSpace software, we enrich the procedure of producing a systematic review of a knowledge domain by incorporating evolutionary models of a scientific specialty, especially the four-stage model of a scientific discipline, into the interpretation of the identified specialties. Our interpretation not only identifies thematic milestones of major streams of science mapping research, but also characterizes the developmental stages of the underlying specialties and the dynamics of transitions from one specialty to another.
Second, our goal is to provide a reliable historiographic survey of the science mapping research. The survey identifies the major clusters in terms of their high-impact members and citing articles that form new research fronts. We also demonstrate new insights that one can intuitively obtain through an inspection of citation trajectories and the positions of citing papers. The enhanced science mapping procedure introduced in this article is applicable to the analysis of other domains of interest. Researchers can utilize these visual analytic tools to perform timely surveys of the literature as frequently as they wish and find relevant publications more effectively.
The most active areas of scientific inquiries are also where the level of uncertainty is the highest (Chen, 2016; Fuchs, 1993). The evidence revealed in our study suggests that science mapping is a Stage III specialty. Research instruments become increasingly powerful and accessible. A wider range of applications of existing techniques will in turn widen our horizen and deepen our understanding of the challenges that we need to overcome in order to advance the state of the art of science mapping.

Dr. Chaomei Chen is a Professor of Informatics in the College of Computing and Informatics at Drexel University, USA. He received a B.Sc. in Mathematics (Nankai University, China), an M.Sc. in Computation (University of Oxford, UK) and a Ph.D. in Computer Science (University of Liverpool, UK). He served as a Visiting Professor at Brunel University, UK and a Chang Jiang Scholar at Dalian University of Technology, China. He served as a member of Thomson Reuter Strategic Advisory Board, the Research Portfolio Analysis Subcommittee of the CISE/SBE Advisory Committee of the National Science Foundation of the USA, a reviewer of the Chang Jiang Scholars Program of the Chinese Ministry of Education, and expert reviewers for national funding agencies of countries such as Austria, Canada, Ireland, the Netherlands as well as the USA. Dr. Chen is the founding editor and the Editor-in-Chief of the journal Information Visualization, the founding editor and the Specialty Chief Editor of Frontiers in Research Metrics and Analytics, and serves on the editorial board of Journal of Data and Information Science. His research and scholarly expertise is in the visual analytic reasoning and assessment of critical information in complex adaptive systems. His work focuses on identifying emerging trends and potentially transformative changes in the development of science and technology, especially through computational and visual analytic approaches. He is the author of The Fitness of Information: Quantitative Assessments of Critical Information Wiley, 2014), Turning Points: The Nature of Creativity (Springer, 2011), Information Visualization: Beyond the Horizon (Springer 2004 2006) and Mapping Scientific Frontiers: The Quest for Knowledge Visualization (Springer 2003, 2013). Dr. Chen has published over 200 peer-reviewed articles in multiple disciplines, including computer science and information science. His work has been cited over 12,000 times on Google Scholar. His research has been supported by the National Science Foundation (NSF) and other government agencies as well as industrial sponsors such as Elsevier, IMS Health, Lockheed Martin, and Pfizer. His earlier research was funded by the European Commission, the Engineering and Physical Sciences Research Council (UK), and the Library and Information Commission (UK). Dr. Chen has designed and developed the widely used visual analytics software CiteSpace for visualizing and analyzing structural and temporal patterns in scientific literature.