

1 Introduction
Peer review is a standard professional practice that is designed to professionally assess the quality and feasibility of scientific projects and all academic projects/papers. Since appointed peer review experts directly create and/or contribute to
the review results and thus influence reader responses to the applicants’ project proposals, expert assignment has been one of the most important tasks in project management (Huang & Zhong, 2016).
the review results and thus influence reader responses to the applicants’ project proposals, expert assignment has been one of the most important tasks in project management (Huang & Zhong, 2016).
The core issue in peer review expert assignment is how to ensure its accuracy and impartiality (Gandhi & Sauser, 2008). Accuracy in this context means that the experts appointed for project review should be very familiar with the related research field, and show correctness and precision in their project. Impartiality means that these experts should make unbiased (independent and fair) reports on all the projects they review (Wu, 1996). A suitable expert, one who is informed and honest, can be expected to make more objective and impartial comments on the quality of the reviewed project. A good fit for peer reviewers and applicants’ work they assess can help maintain the prestige of the reviewers and better ensure the reputation of the project designers, authors, and affiliate institutions.
The expert assignment problem (EAP) as a common phenomenon has attracted considerable research interest in recent years. Most of these works focus on the accuracy of the expert assignment (Wang, 2007). Aiming to guarantee such assignment accuracy, Li and colleagues in the last decade proposed two heuristic algorithms to solve the EAP—a genetic algorithm (Kumar et al., 2010; Li et al., 2007) and an ant colony optimization algorithm (Dorigo & Blum, 2005; Li et al., 2008). Li, Peng, and Wei (2013) further proposed an adaptive parallel genetic algorithm focused on assignment accuracy and computational efficiency to address the EAP. While these algorithms can fulfill the fundamental task of expert assignment to some extent, two main problems with their methods need to be addressed. First, all of these proposed algorithms assume a closeness (or similarity) measurement between the research fields of every applicant and experts. A formal definition and a calculation method for the measurement, however, should be detailed to clarify these relationships. Second, reviewer impartiality has not been considered in these methods. To deal with this closeness/similarity limitation, Ho et al. (2017) have just created a proposal reviewer recommendation system using keywords with fuzzy weights based on big data. So the topic is starting to get needed attention at this time.
Impartiality in peer reviews is supposed to be supported or guaranteed by project sponsors or government agencies using administrative means (Wu, 1996). For example, the National Natural Science Foundation of China (NSFC)—the most important science foundation in China—requires that applicants’ relatives should be excluded from their peer review expert team (Zhang et al., 2016). But professional or personal relationships that can impact peer review dynamics may be more numerous and meaningful (if less obvious) than those of family members when addressing EAP concerns. Other criteria for judging potential conflict of interest are therefore necessary to ensure impartiality. Outside of certain discussions on rules and regulations (Agee, 2007; Wang et al., 2002), however, the impartiality of expert assignment has rarely been considered in designing algorithms or data assessment techniques to address EPA concerns.
To tackle the above problems, we propose a peer review expert assignment method that considers both accuracy and impartiality. During the expert assignment, the method simultaneously takes into account the fitness degree among the project proposals and review experts, the research intensity of the experts, their academic association(s), and potential conflict of interest in the peer review process. The fitness degree and research intensity criteria are designed to ensure assignment accuracy, while academic associationand conflict of interest criteria to help guarantee impartiality. In summary, the contributions of this paper are as follows: (1) we propose four criteria designed to express the characteristics of a good and appropriate peer review expert; (2) we formalize the expert assignment problem as an optimization problem (finding the best among multiple solutions) on the designed criteria; and (3) we implement a randomized algorithm to help solve the EAP problem and perform simulation to verify the effectiveness and feasibility of the proposed method.
The remainder of this paper is organized as follows. Section 2 defines the four criteria, gives the formal definition of the expert assignment problem, and presents the proposed randomized algorithm. Section 3 presents the simulation analysis of the algorithm. Section 4 offers the conclusion, limitations, discussion, and future research directions.
2 The Expert Assignment Problem and Proposed Solution
An appropriate peer review expert needs to have three main qualifications:
(1) sufficient knowledge of the area/field under review; (2) enough front-line research experience to grasp the area/field’s key research points and frontiers to better guarantee an accurate understanding of the project proposal quality; and (3) few or no interest associations with the applicant to ensure the fairness of the project review. Interest association in this context refers to (a) the applicants’ academic association (e.g. same organization, co-authored/co-funded works, and other relationships/links, past or present) with the review experts, and (b) other interest associations like similar project proposals of the experts related to the applicants.
(1) sufficient knowledge of the area/field under review; (2) enough front-line research experience to grasp the area/field’s key research points and frontiers to better guarantee an accurate understanding of the project proposal quality; and (3) few or no interest associations with the applicant to ensure the fairness of the project review. Interest association in this context refers to (a) the applicants’ academic association (e.g. same organization, co-authored/co-funded works, and other relationships/links, past or present) with the review experts, and (b) other interest associations like similar project proposals of the experts related to the applicants.
We then map the four (1, 2, 3-a, and 3-b) conditions into the proposed four criteria (fitness degree, research intensity, academic association, and conflict of interest) and explain how every criterion can be intuitively designed. A formal definition of each criterion is presented, along with details on how the expert assignment problem is addressed.
2.1 Fitness Degree
The reviewing experts who fit the project proposal’s research background are first selected. The most intuitive way of measuring the fitness between an expert and a project proposal is to assume each expert and proposal applicant has a vector of description keywords (related to the research area). The similarity between the two vectors is then selected as the fitness degree. The problem here is that keywords provided by different researchers may have high levels of personal relatedness, or one research point may apply different expressions depending on different researchers’ word choice. We thus make two assumptions about the research descriptions: (1) the topic description is hierarchically structured, in that it has more than one level of detail; and (2) the keywords in the description are (semi-)controlled, so that most of the words can be matched during similarity calculation.
Actually, the assumptions (about the research descriptions) have been met by the NSFC Committee, which set up an Internet-based Science Information System (ISIS) to manage users’ research resumes. A user of ISIS can log in as either an applicant or expert(1)((1)Only researchers who have been selected as peer review experts have the role of expert.). With either role, the system will require the users to register their research resumes. Among other variables, the research field section is used to collect scientific research backgrounds, consisting of three fields: familiarity code (FC), research direction(RD), and keywords ( ), which correspond to the research area/field, specific research direction, and specific research points (or methods), respectively. Thanks to the NSFC Committee’s efforts to standardize the process, each FC and RD is a pull-down single-selection domain, where RD can only be generated after FC is set. In other words, users with similar research fields and directions will very likely choose the same or a similar familiarity code and research direction. The keywords ( ) further consist of five semi-controlled text fields. When double clicked, the system will automatically generate the hottest keywords in the research direction. Users are recommended to employ auto-generated keywords rather than type in their own words, a strategy that greatly increases the probability of users with the same research interests to choose the same keywords to describe their work.
To link with appropriate peer review experts, applicants will usually find or accept recommendations on keywords that best fit their project proposal’s research area. Consequently, we calculate the two parties’ fitness degree hierarchically as follows. If the proposal applicant and the expert have the same familiarity code, they have a fitness score of 0.2. Further, if they have the same research direction, they gain a fitness score of 0.3. Given two keywords vectors, the cosine similarity of the vectors is first calculated, and then scaled with 0.5 as keywords fitness score. The three fitness scores are then added to make the final fitness degree between the applicant and the expert. Considering that the same keywords may have completely different meanings across research fields, the keywords only contribute to the fitness degree if the score of the familiarity code is not 0.
Let RF={FC,RD, } be the research field of a researcher R, where each FC and RD is an element of a different set of text descriptions, and is a 5-length vector of words. Since a researcher may have two different roles (applicant or expert), Ai and Ei are used to denote the role of applicant and expert of researcher Ri, respectively. Reference to Ai thus means that Ri has submitted a project proposal Pi. Further, given Ri, let be the research field of the applicant’s role, and b the research field of the expert’s role. Based on the notations, fitness degree is defined as follows.
Definition 1 Fitness Degree. Given a proposal Pi and an expert Ej, the fitness degree FDij between Pi and Ej can be calculated as Equation (1):
\[FD_{ij}=\left\{\begin{array}{rcl} \Gamma (FC^a_i,FC^e_j)\times (0.2+0.3 \times \Gamma (RD^a_i,RD^e_j)+0.5{∠}(\vec{K}^a_i,\vec{K}^e_j))\ \ if \ i \neq j\\ -1\ \ \ \ \ \ \ else\ \ \end{array}\right.\ \ (1)\]
where ∠(.,.) denotes cosine similarity and Γ(.,.) is a determination equation with Γ(a, b) = 1 if a = b, Γ(a, b) = 0 if a ≠ b. Note here that FDij = -1 is more of a flag than a score, as it notifies that an expert cannot review his/her own proposal.
2.2 Research Intensity
A researcher’s research status is described herein so that when the researcher is appointed as a peer review expert, the confidence level in relation to the value of the expert’s comments can be identified. Because an expert should have enough front-line research experience to grasp the key research points and frontiers of the field and make accurate review comments, we use the H-index and publication timeline to characterize the expert’s status.
Given an expert’s H-index and publication history, the ranking of her/his H-index is first derived based on all experts’ H-indexes from the same research field (i.e. researchers having the same FCe as the one given). A new parameter ranking percentage can be calculated as dividing the expert’s ranking by the total number of experts in the same research field. This ranking percentage indicates a researcher’s relative academic competence in the research field and can thus convey the meaning of preferable, that is, an expert with a higher H-index may be a preferred candidate for proposal evaluation. Next, the expert’s latest publication year is used to characterize her/his research vitality. The core idea is that a researcher’s ability of following up with academic frontiers declines with the lack of continuous output. The aging model is used to describe this vitality decline. The academic achievement and research vitality score is finally combined into the applicant’s research intensity score as follows.
Definition 2 Research Intensity. Let RP be an expert’s ranking percentage, and PY his/her latest publication year. The research intensity RI of the expert is defined as Equation (2):
where ∆t = Tc - PY, Tc is the current year, and γ ∈ (0, 1) is the attenuation factor that determines the expert’s declining speed in research intensity along with the number of years without research output. For instance, if γ = 0.95, and a researcher’s H-index ranking is 245/1000, with the latest publication year of 2015, then RP = 245/1000 = 0.245, RI = (1 - 0.245) × 0.952017-2015 = 0.681.
Note that in practice, however, an expert’s H-index may not be easy to acquire. This problem can be solved by information provided by the expert’s funding agencies. For example, NSFC is collaborating with ScholarMate(2)((2) www.scholarmate.com) to allow users to maintain their research resumes online. The data can be used to calculate H-indexes and construct academic social networks (used in the next subsection).
2.3 Academic Association
Up to now, fitness degree and research intensity can be used to assign an adequately accurate expert for peer review. It is then necessary to assure impartiality, where there should be little academic association and no conflict of interest between an applicant and the expert.
Academic association is defined based on the network distance between the applicant and expert on academic social networks, which are set up based on various relationships among applicants and experts. Experts having the least degree of association with the applicant can thus be assigned for peer review, where academic association is defined as follows.
Definition 3 Academic Association. Given an applicant Ai and an expert Ej, let Hij be the number of “hops” in the shortest path between Ai and Ej in the academic social network. The academic association AAij between Ai and Ej is then is defined as Equation (3):
where ξ > 1 is the attenuation factor that determines the academic association’s declining speed with respect to the network distance. For instance, let ξ = 2, where the shortest path between an applicant Ai and an expert Ej only has 1-hop (i.e. they have direct relationship), then AAij = 2-1+1 = 1, the highest degree of association two researchers can have. If the shortest path instead has 4-hops, then AAij = 2-4+1 = 0.125, indicating very little association between them.
2.4 Conflict of Interest
It is now important to assure that a review expert does not review a proposal in the research area that he/she has also applied for support. Since it is hard to say to what extent the similarity between the expert’s proposal and the reviewing proposal can influence the review result, an alarm value is set so the proposal will not be assigned to this expert if the similarity is larger than the threshold. If this is not the case, the expert is regarded as having no potential/actual conflict of interest with the applicant. Conflict of interest is defined as follows.
Definition 4 Conflict of Interest. Given an applicant Ai and an expert Ej, if Ej submitted Pj, the conflict of interest CoIij between Ai and Ej can be calculated as Equation (4):
where τ is a given threshold and \(c_{ij}=\Gamma (FC^a_i,DC^a_j)\times (0.2+0.3 \times \Gamma (RD^a_i,RD^a_j)+0.5{∠}(\vec{K}^a_i,\vec{K}^a_j))\).
2.5 Expert Assignment: Problem Formalization
Based on Definitions 1 to 4, we can assign the expert that best fits the proposal, has the highest research intensity, least degree of academic association, and no conflict of interest with the applicant for project review. The selectivity degree is used to unify the four concepts as follows.
Definition 5 Selectivity Degree. Given a proposal Pi and an expert Ej, the selectivity degree SDij of Pi on Ej is defined in Equation (5).
\[SD_{ij}=\left\{\begin{array}{rcl}-1 \ \ \ if\ \ CoI_{ij}|FD_{ij}|AA_{ij}=-1 \\ \sqrt[3]{CoI_{ij}\times FD_{ij} \times RI_{ij}\times min(\frac{AA^{-1}_{ij}}{\xi ^s})\ }\ \ else \end{array}\right. ,\ \ (5)\]
where | denotes logical OR, min(a,b) is the minimum function that returns the smaller numbers of a and b, and s is a positive integer.
Under Definition 5, if SDij = -1, then the proposal will not be assigned to the expert for review due to conflict of interest or avoiding self-reviews. If this is not the case, then the larger the fitness degree and research intensity is, the larger the selectivity degree. A proposal will be more likely assigned to an expert with considerable research intensity, which offers a better fit. As to academic association, for better understanding of , Equation (3) is plugged in and mathematical transformations are made as in Equation (6):
=mian (6)
That is, suppose ξ = 2, and suppose s = 3, then if Hij = 1 (direct collaboration), we have; if Hij = 4, we have ,1) = ,1)= 1; further, if Hij = 5, we have ,1)= ,1). From these examples it can be known that selectivity degree will increase with larger Hij (i.e. smaller academic association). However, when Hij reaches s+1, the further increase of Hij will no longer increase selectivity degree. We use s as a hop-lock to avoid the infinite increase of selectivity degree caused by the increase of network distance, and to convey the meaning that all experts with sufficient distance from an applicant will be considered having no academic association with the applicant.
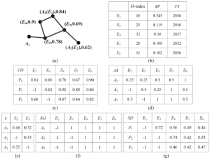
Figure 1. An example of expert assignment based on selectivity degree. |
In practice, a number of proposals need to be reviewed at the same time. Moreover, every proposal needs to be reviewed by more than one expert, and every expert can only receive a limited number of proposals. Hence, given m project proposals and n review experts, let N be the number of review experts a proposal should have, M be the largest number of proposals an expert can receive, and ={S } be the set of selectivity degrees. Where SDij denotes the selectivity degree of proposal Pi on expertEj, the expert assignment problem is defined as follows.
Definition 6 Expert Assignment Problem. Find a set of 0/1 appointments\(\sum^M_{i=1}\sum^n_{j=1}S_{ij}\times SD_{ij}\)that maximizes and satisfies both Equations (7) and (8):
\[\forall i\in [1,m],\sum^n_{j=1}S_{ij}=N \ \ (7)\] \[\forall j\in [1,n],\sum^m_{i=1} S_{ij}\leq M \ \ (8)\]
2.6 Expert Assignment: Proposed Solution
Definition 6 defines a version of the 0-1 knapsack problem (Freville, 2004), a famous NP-C problem in computer science. That means that the problem may not be solved in a finite amount of time. Hence, the 0-1 knapsack problem is always handled using dynamic programming, greedy algorithm, and randomized algorithm (Martello & Toth, 1987). In this paper, we adopt the randomized algorithm to solve the problem since it can efficiently find an acceptable solution within a reasonable time period.
Before carrying out the proposed algorithm, an example of possible assignments is given (Figure 2 ). Based on the selectivity degrees presented in Figure 1 (g), Figure 2 presents two possible assignments (where each assignment contains a set of 0/1 appointments), by assuming every proposal should be reviewed by two experts (i.e. N = 2), and each expert can receive no more than two proposals (M = 2). We can then calculate the total selectivity degree to identify the better assignment. The second assignment (Figure 2 (b)) is seen to gain a total selectivity degree of 3.46, much larger than the first assignment (Figure 2 (a)), with the total selectivity degree of 2.95.
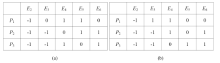
Figure 2. Two possible assignments (a) and (b). |
The possible assignments are seen to increase exponentially with the increase of experts and applicants. It is hard to find the best assignment in a limited amount of time when the number of experts and applicants is large. Hence, we design a randomized algorithm to find an adequately good assignment in a relatively short period of time. The idea is that, proposals to experts are randomly assigned until all the proposals have N review experts, while guaranteeing every expert has fewer than M appointments. The total selectivity degree is then calculated. The process is repeated ROUND (e.g. 105) times, where the assignment with the largest selectivity degree is employed, as noted in Algorithm 1 (Figure 3 ).

Figure 3. Algorithm 1 process. |
3 Simulation Analysis
In this section, we perform simulations to verify the effectiveness and feasibility of the proposed algorithm. During the simulation, four matrices are randomly generated, corresponding to the four proposed criteria. Then the matrix of selectivity degree is calculated, after which the randomized algorithm is run ROUND times to find the best assignment (i.e. the assignment having the maximum total selective degree), and the intermediate results are recorded for analysis.
3.1 Data Generation
For the generation of fitness degree, we assume applicants and experts are from the same research field, i.e. FD . This assumption is rational since we need experts with similar research content for reviewing, where the assumption can be easily confirmed by matching the familiarity codes of experts and applicants before assignment. We further assign the fitness degree subjects to the Normal Distribution N(0.6, 0.2) so that the average fitness degree will be 0.6, where 95% of the fitness degree will fall into [0.2, 1]. This assumption is based on the intuition that the researchers in the same research area/field will have roughly similar research content, where the probability of having exactly the same research content or extremely different content will be small. During the generation, values lower than 0.2 are assigned to the value of 0.2, and values greater than 1 are assigned to 1.
As to research intensity, we assume a uniform distribution of U(0,1) for generation. According to Definition 2, the ranking percentage part (i.e. 1-RP) is subject to uniform distribution. And if we assume all the researchers’ publication years are also subject to uniform distribution, the attenuation factor part ( ) will not affect the distribution of research intensity as a whole.
For academic association, we generate network distances based on the Sixth Degree Segmentation Theory (or Small World Phenomenon). Small World Phenomenon proposes that in a social network, there will be no more than six hops before a person can reach any stranger in the network (Milgram, 1967). This phenomenon is also closely applied to academic social networks, due to the particularity of academic circles (e.g. which consist of people with similar research backgrounds who are very willing to know each other) (Cainelli et al., 2015). Hence, we assume a researcher in the academic social network can reach 70% of other researchers in less than three hops, and can reach anyone in the network in less than six hops. More specifically, we assign the probability of reaching h-hop as 0.1, 0.2, 0.4, 0.1, 0.1, 0.1 for h = 1, 2, ..., 6, respectively. Finally, for conflict of interest, we randomly generate a matrix that contains 10% of -1s and 90% of 1s.
3.2 Effectiveness of the Proposed Algorithm
During the simulation, the algorithm parameters are set as: m = 200, n = 500, N = 4, M = 8, ROUND = 108. Note that 200 is a sufficiently large number of applicants in practice. Since according to statistics, the total number of proposals is subject to management science, where NSFC 2016 is 8,293 and there are 57 familiarity codes in management science. So there is an average of 145 proposals per familiarity code. Also note that while the proposed algorithm is expected to find a better result with a larger ROUND, our experimental results show that ROUND = 108 can return a good assignment for m = 200(4)((4) A larger m may need a larger ROUND due to the increase of solution space (search space).).
Since the output of the randomized algorithm is non-deterministic, we run the algorithm 100 times (see Figures 4 and 5 for analysis). For each run, we record the average fitness degree, research intensity, and academic association of the best assignment (best value) of all the ROUND assignments (overall value) and of the worst assignment (worst value). We then calculate the averages within the best, overall, and worst values of the 100 runs.
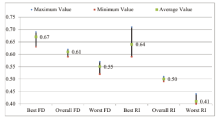
Figure 4. Results of fitness degree and research intensity. |
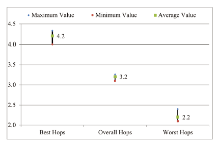
For academic association, we plot the maximum, average, and minimum hops of the best, overall, and worst assignments (see Figure 5 ). The results are very similar to those of fitness degree and research intensity. The converged (i.e. expected) average hops (between an expert and the applicant) is 3.2. Compared to the overall assignments and the worst assignment, on average our algorithm can find the experts for peer review with one or two hops away from the applicants.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 5. Results of academic association analysis (measured by hops). |
3.3 Feasibility Analysis
The time overhead of the algorithm is analyzed to verify whether it is feasible for expert assignment in practice. The same set of parameters is used here as those used in Section 3.1, except that m is varied from 10, 20, 50, 100, and 200 to 500 for verification. This approach is used because according to Algorithm 1, besides ROUND, the algorithm’s efficiency is mainly determined by m. Correspondingly, the algorithm needs approximately 50, 100, 250, 500, 1,000, and 2,500 seconds to return the best assignment. The results show that: (1) when ROUND is fixed, the algorithm’s time overhead is linearly correlated with the input m; (2) an assignment of 200 proposals needs less than 17 minutes on a computer with Intel Core i7-6700 (3.4GHz) and 8G memory, which is adequately efficient for the non-real-time expert assignment problem in this paper; (3) when there are large numbers of proposals that need to be assigned, a p-node parallel computing network can easily increase the speed of p times (e.g. the assignment of 200 proposals will need less than one minute if p = 20), and the parallelization can be very easily deployed. In this case each round of assignments can be executed independently, and the results of each round can be efficiently integrated and compared in one run.
4 Conclusion and Limitations
In this paper, we formally define the expert assignment problem as an optimization problem while considering both accuracy and impartiality of experts based on four carefully designed criteria. The criteria characterize the properties that a good peer review expert should have. With the help of the criteria, the integrated criterion (i.e. selectivity degree) is defined for expert selection, where a randomized algorithm is proposed to solve the optimization problem. Simulation results show that the proposed method can always identify experts with considerable research intensity, as well as adequate fitness degree and relatively fewer academic associations or conflict of interest with the proposal applicants for project review. Furthermore, the proposed algorithm can return results in an acceptable amount of time.
A limitation of this study is that real data (rather than simulation data) may be more convincing in proving the effectiveness of the proposed method. The authors are actively contacting the officers of project funding agencies (e.g. NSFC) for potential collaboration. Hence, our future work will be dedicated to improving the proposed method in terms of practical applications. For example, more criteria may be considered and adopted for expert characterization to further promote the accuracy and impartial of the assignment based on real data. Also, an algorithm with more sophisticated strategies (e.g. backtracking) may be designed to further improve the efficiency of the assignment when the data volume is extremely large.
Author Contributions
M.L. Yue (yueml@whlib.ac.cn) proposed the research question, designed the methods, and designed and implemented the algorithm. K.L. Tian (23950839@qq.com) wrote the manuscript. T.C. Ma (atc@whlib.ac.cn, corresponding author) designed the method and revised the manuscript.