

1 Introduction
Any form of research evaluation across disciplines that uses citation counts requires that the citations are normalized to the field or discipline involved. This is because there are very significant differences between research areas—science and particularly biology and medicine have very high citations rates; social sciences generally much less; and the arts and humanities relatively very low (Bornmann & Marx, 2015; Leydesdorff et al., 2011; Opthof & Leydesdorff, 2010; Waltman & van Eck, 2013). Normalization involves relativizing the research publication’s citations to the average1(1Often the average is measured in terms of the mean but as citation distributions are always heavily skewed the median is a better metric.) density of citations within the field. There are several ways of doing this, both in terms of the source of citations and the comparator used. In terms of sources, most normalization uses specialized citation databases such as Web of Science (WoS) or Scopus. These provide reliable data but are limited in coverage—they are poor in the social sciences and humanities, and they do not yet cover, comprehensively, books, conferences or reports (Glänzel et al., 2016; Kousha et al., 2011; Leydesdorff & Felt, 2012; Torres-Salinas et al., 2014). This has led to consideration of Google Scholar (GS) as a source which has much more comprehensive coverage of both disciplines and types of output but has unreliable data and a limited user interface (Adriaanse & Rensleigh, 2013; Crespo et al., 2014; Harzing & Alakangas, 2016; Meho & Yang, 2007;Mingers & Lipitakis, 2010; Prins et al., 2016).
So far, there have only been limited attempts to normalize Google Scholar data. Prins et al. (2016) compared citations from WoS and Google Scholar in the areas of anthropology and education. They tried to normalize the GS data using Publish or Perish (Harzing, 2007), which is a more user-friendly interface to GS, and concluded that it was technically feasible but that the results were unsatisfactory, although they did not explain why they were unsatisfactory. Following from this, Bornmann et al.(2016) conducted a more explicit test using data on 205 outputs from a research institute. Of these, 56 were papers also included in WoS, 29 papers not covered by WoS, 71 book chapters, 39 conference papers and 10 books. Their results were positive in that they managed to normalize the papers, book chapters and conference papers (but not the books) although it required considerable manual intervention to control for data errors. This test was replicated by Mingers and Meyer (2017) on a sample of 186 publications within the management area with similar results—papers, chapters and conference papers could be normalized but required considerable manual effort.
Neither study attempted to normalize books as they pose a particular problem for normalization, that is, what should be the comparator set of publications? Papers are generally compared with similar types of papers from similar journals of the same year. Book chapters can be compared to the other chapters in the book. Conference papers can be compared to the other papers at the conference. But how can one find a set of books that would provide a reasonable comparison? Would it be all the research books (as opposed to textbooks?) published within a discipline or field within the same year? If so, how would one generate such a list? And how would one delineate the discipline or field within it? Attempting to answer this question is the contribution of this paper.
When normalizing journal papers, there are broadly two approaches to determining the comparator set for a particular output (Leydesdorff et al., 2011; Mingers & Leydesdorff, 2015b; Waltman & van Eck, 2013)—cited-side (Mingers & Lipitakis, 2013; Opthof & Leydesdorff, 2010; Waltman et al., 2010; Waltman et al., 2011) and citing-side (source normalization) (Moed, 2010b; Waltman et al., 2013; Zitt, 2010, 2011). In cited-side normalization, the number of citations of the target paper are compared with the citations that have been received by similar papers where the comparator set consists of similar papers from the same journal in the same year, or from the set of journals used by the research entity under evaluation, or from the set of all journals in the same field as defined by WoS’s field lists. Whichever is used, it is the number of received citations that are counted, and the comparator list is pre-defined and is the same for all the papers being compared. Examples are the journal normalized citation score (JNCS) and the mean (field) normalized citation score (MNCS).
With citing-side normalization, it is the source of citations that is used for normalization, that is, the reference lists of the citing papers are used as a measure of the citation density in the field. This is based on Garfield’s view that “the most accurate measure of citation potential is the average number of references per paper published in a given field” (Garfield, 1979). An example is SNIP which is available in Scopus (Moed, 2010a; Moed, 2010b; Waltman et al., 2013). This method also differs from traditional cited-side normalization in the way it determines the reference set of journals or papers. Rather than taking a pre-defined list of journals in the field as defined by WoS, the subject field is defined as the set of papers that cite the target paper (Moed, 2010a), or more widely the set of journals that contain these citing papers. The reference lists of these papers, or relevant parts of them, are then averaged to generate the normalization factor. This means that each target paper has its own, unique reference set of citing papers, and that it is assumed that these papers represent the field of discipline appropriately.
In this research we use a hybrid of the two approaches to normalize book citations. We use the citing-side method to determine a set of books that have cited the target book, and which should therefore be relevant to it and delimit the book’s field or discipline, but then we count the number of citations that these books have received rather than the size of the reference lists to normalize with. It would theoretically be possible to use the books’ reference lists but these can be extremely large and unwieldy, and are not easily available in the citing databases.
Bornmann and Haunschild (2016) have also suggested a hybrid method for normalizing papers. In their method, the field for a target paper or journal is defined using the WoS field lists (as in the cited-side method) but it is the reference lists of these papers that are used for the normalization rather than the number of times they have been cited (as in the citing-side method). These differences are shown in Table 1 .
Table 1 Variations in methods of normalization. |
| Metric used for the normalization | |||
|---|---|---|---|
| Mean number of citations received by comparator papers | Mean number of references in the comparator papers | ||
| Method for determining the comparator set of papers | WoS field list of journals | Traditional cited-side methods such as MNCS | Bornmann and Haunschild hybrid |
| Papers that have cited the target paper or journal | Mingers and Kaymaz hybrid in this paper | Traditional citing-side methods such as SNIP | |
This shows that in some sense our method is the obverse of Bornmann and Haunschild’s.
The first section of the paper will explain the method in more detail; the second section will discuss the dataset and problems encountered in collecting the data; and the third section will present the results.
2 The hybrid method
2.1 Defining the comparator set
The hybrid method uses the citing-side approach to identify a set of relevant books with which to normalize the target book. These will be the books that have cited the target book according to GS. We choose to look only at citing books rather than papers for several reasons. First, generally all normalization approaches aim to compare like with like. They take into account the type of publication—journal paper, editorial, review, conference paper, report etc.—and they also only consider outputs produced in the same year. Second, studies of book citations have shown that they do indeed differ from citations of other types of publications in a variety of ways (Glänzel et al., 2016; Kousha et al., 2011; Leydesdorff & Felt, 2012; Torres-Salinas et al., 2014). There are also problems in bibliometrically identifying books that do not occur so much with journal papers (Giménez-Toledo et al., 2016; Williams et al., 2018; Zuccala et al., 2018; Zuccala & Cornacchia, 2016) which will be discussed in the data collection section.
One question that could be raised is, to what extent do the set of citing books (as opposed to a WoS field list) actually capture the appropriate field or discipline? This is fundamental to the purpose of normalization as Garfield stated:
“Evaluation studies using citation data must be sensitive to all divisions, both subtle and gross, between areas of research; and when they are found, the study must properly compensate for disparities in citation potential” ((Garfield, 1979) quoted in (Moed, 2010b)).
It could be the case, for example, that the citing books come from a range of different disciplines with different citing characteristics. There has been little research on this so far. We also have to be aware that our method, counting the citations (all citations not just book citations) to books that cite the focal book, makes them one step removed. This is related to the idea of a “citation wake” (Fragkiadaki & Evangelidis, 2014, 2016; Klosik & Bornholdt, 2014) which traces the citation network of indirect citations following the publication of a particular target paper, but this approach is more concerned with giving due credit to the impact of important papers rather than normalizing them.
As we outlined above, there are currently two main methods of delineating the field but we do not believe that there is, at the moment, a perfect answer—both methods have advantages and limitations. With our citing-side methodology, it is true that the set of citing books could potentially range across fields and even disciplines but the main reason for us choosing it is because there simply is no available equivalent of the WoS field lists for books—that is the main reason that no book normalization methods have been developed. More positively, however, this approach is well-established and accepted (Leydesdorff & Opthof, 2010; Moed, 2010a, 2010b; Zitt, 2010, 2011), and Moed argues that it is actually superior to field lists:
“Delimitation of a journal’s subject field does not depend upon some pre-defined categorization of journals into subject categories, but is entirely based on citation relationships. It is carried out on a (citing) paper-by-paper basis, rather than on a (citing) journal-by-journal basis.
The delimitation is ‘tailor-made’. A subject field can be defined accurately even when general or multidisciplinary journals covering several fields rather than one play an important role in it.” (Moed, 2010a)
Using WoS fields as in cited-side normalization has the advantage of a pre-defined list of journals that is open and transparent, and is the same for all the publications being normalized. And, clearly, in some sense it is seen, at least by WoS, as defining a field. However, there are also well recognized problems. Bornmann and Haunschild (2016) point out that there are multidisciplinary or interdisciplinary journals that cannot be easily assigned to a field, and that the WoS fields are themselves not well defined being a mix of broad and fine-grained categories with journals appearing in more than one category. Mingers and Leydesdorff (2015a) conducted an empirical analysis of the field of business and management, which is very diverse, using factor analysis on a journal cross-citation matrix from WoS. They found that clear groupings could be established although it was difficult to decide how many groups there should be, and the groupings were significantly different from those of WoS for this area.
2.2 Defining the normalization metric
We then count the number of citations in GS that each of these books have received and calculate the average either using the mean or the median (to be discussed later). One problem with this is that by definition the citing books will all be more recent than the target book otherwise they would not be able to cite it. This means that they will have had less time to generate citations and so the comparison would not be fair. To overcome this, we actually use the rate of citations rather than the absolute number of citations, that is the number of citations divided by the number of years since the book’s publication2(2Current year—original publication year. A book that was published in the current year would be excluded.). This is not perfect since it takes some years for citations to fully develop (Mingers, 2008) but no better alternative could be found.
Step 1 Identify the target book in Google Scholar using the authors, title and year of publication. Sometimes the ISBN from the Research Assessment Exercise (RAE) dataset was also used.
Step 2 Find all the citations of the target book within GS and the number of years since publication, and divide the citations by the years to calculate the citations per year for that book.
Step 3 Select only those citing works that are books. This turns out to be practically very difficult as will be discussed in the next section.
Step 4 Ascertain the number of citations that these books have received from all sources not just other books, and the number of years since publication, and calculate the citations per year for each one. Note that GS includes citations from many sources not just papers or books. Again there are problems in this stage.
Step 5 Calculate the mean or median of these citation rates.
Step 6 Divide the citation rate for the target book by the average citation rate for the citing books to give the normalized value.
3 The dataset and problems in data collection
3.1 The dataset
To test this method we required a set of books, primarily research books since textbooks are not usually included in research evaluations, that were published some time ago in order to allow citations to develop and about which we had accurate publication details. The set we chose was all the books submitted to the 2008 UK Research Assessment Exercise (RAE) in the field of Business and Management (this can be downloaded from http://www.rae.ac.uk). These were all books published between 2001 and 2007, and should all be research books. Their publication details should have been validated by the RAE although in fact some errors were found. This is the same source as used by Kousha and Thelwall (2011). In all there were 285 (there are only 283 in the dataset as two were not found as books)—although this is not a very large number, given the extensive manual work that was required it was still extremely time-consuming. They involved querying 5,366 citing books although the number of total citations is very much greater than this.
3.2 Problems in using the Google Scholar data
We will discuss the process and problems of data collection in terms of the six steps outlined above. All GS searches were done using the Publish or Perish (PoP) interface but while this makes it much easier to examine and analyze the results, PoP is only performing GS searches and so inherits all the data problems of GS. One noticeable problem it that searches are extremely sensitive to the particular information typed in, and the fields that are used. In general, we found it better to begin searches with a minimal amount of information, e.g. just the title, and then add in more if necessary. If one begins with the full information then sometimes GS cannot find it as it is too specific in comparison with the information that GS mines.
Step 1 Identifying the target book.
a) Type book name on “All of the words”
b) If more than one result found with different names, then look up for the ISBN number given on the list in GS; thus, find the correct name of the book and search again with this book name
c) If more than one result is found with different names, then type the authors name on “Authors” to narrow down the search
d) Check again number of cites on Google Scholar manually
e) If there are more than one entry, perhaps from different sources, then combine the citation lists but this must be done carefully as some of the citations may be the same.
Step 2 Having found all the citations, the publication date should also be known and so it was straightforward to calculate the citations per year for the target book. Note that this includes all citations, not just those by other books.
Step 3 For the target book, select from its citations only those that are books. At first sight this seemed easy but in fact it raised quite fundamental issues.
a) GS does try to classify citing works as being of particular types, one of which is “book”. This appears as a column in PoP. However, this is highly inaccurate both because some classified as books in fact are not, but more so because many that are not classified as books in fact are.
b) The first stage is with those classified as “books” by GS. Ideally the “publisher” field will have the actual publisher and clicking on the title does take you to the publisher’s website where it can be confirmed as a book. However, sometimes the publisher field refers to something else, perhaps an institutional repository, or is just blank. In these cases it is necessary to search manually to try and find the book, looking in Google Books, Amazon, the British Library or the Library of Congress and even occasionally eBay.
Different results for the same book can also be found, perhaps because the citations have been entered differently (e.g. the authors the wrong way round), or because GS finds it from different sources. It is necessary to investigate each one and if they do appear to refer to the same book, the citations are amalgamated.
c) With entries not classified as “books” the situation is more complex (Zuccala et al., 2018; Zuccala & Cornacchia, 2016). The general possibilities are “citation”, “pdf”, “html” or most commonly just “blank”. We can firstly rule out most journal papers because they generally have the journal in the “publisher” field and it is relatively rare that “pdf” or “html” refer to actual books. But that leaves a large number of “citation” and “blank” each one of which has to be investigated. Several publishers appeared regularly in the “publisher” field but were generally not books:
● Proquest are nearly always dissertations
● GRIN Publishing was rarely seen as books by GS but in fact specializes in e-books
● DiVA Portal is mainly dissertations but does have some books
● JSTOR is nearly always journal articles
● “gov”, “edu”, and “ac” are nearly always theses, reports or papers.
These investigations raised another issue which turned out to be rather fundamental and that is the question “what actually counts as a book?” One of the criteria that we tried to use was the possession of an International Standard Book Number (ISBN). After all, this is a “book” number and so should only be applied to a book. But we found that in fact many reports had ISBNs as did dissertations and conference proceedings. It turns out that ISBNs can be purchased by institutions and then applied fairly indiscriminately to anything they want. In fact, the ISBN website explains:
What does an ISBN identify?
ISBNs are assigned to text-based monographic publications (i.e. one-off publications rather than journals, newspapers, or other types of serials).
Any book made publicly available, whether for sale or on a gratis basis, can be identified by ISBN.
In addition, individual sections (such as chapters) of books or issues or articles from journals, periodicals or serials that are made available separately may also use the ISBN as an identifier.
(https://www.isbn-international.org/content/what-isbn, accessed 4/2/2018)
We then investigated a number of other sources including literature searches in the bibliometrics literature, databases such as WoS and Scopus, the REF, and the British Library and the Library of Congress but could find no clear definition that would distinguish between published books, dissertations or reports. In fact, librarians that we spoke to said that it varied between disciplines and countries. In some countries it was standard practice that PhD dissertations would be published as books with no changes. There were particular publishers who did this for a payment from the author. On the other hand, particularly in the humanities, it was considered necessary to make significant changes to a dissertation before it was published.
Similar conclusions were reached by Williams et al. (2018) in a study of the place of books in research evaluation within Europe. They found that the definition of books was equally unclear and differed between disciplines and also countries. For example, in the UK’s REF evaluation, which is by peer review, the definition was fairly broad and it was left to the reviewers to judge if an output was in fact a book, while in Poland and the Czech Republic where there are purely quantitative systems, books were defined very precisely. They concluded “None of these questions have easy answers or any answer at all. The reality is that much depends on the disciplines involved and on the evaluation policies of different institutions and countries.” (Williams et al., 2018)
For the purposes of this research we took an ad hoc definition that the item needed to have an ISBN and be traceable in either Google Books, Amazon, or the publisher’s website.
Step 4 Having decided which citing works were books, we then found the number of citations to the target book and the publication date of the citing work. Although generally straightforward, a problem emerged here when some of the citing books had extremely high numbers of citations—in the thousands rather than the usual hundreds. On investigation these generally were books that had been published many years ago and had many editions. GS, not unreasonably, counts all the citations to all the different editions of the book. The problem is that many of these editions would have been published before the target book and so could not possibly have cited it. Zuccala et al. (2018) have investigated this as part of the problem of accurate indexing and citation counts of “families” of books, that is books that have different editions, publishers or content (Zuccala & Cornacchia, 2016).
It is desirable to identify only those citations that had occurred in editions after the target book was published, but this again was not straightforward. Consulting the publisher’s website or Google Books or Amazon did not usually provide a full history of the various editions. It was possible to search for the book up in the British Library catalogue and sometimes, but not always, the publication history was available on the “Additional Information” tab. As we could not reliably get this information, we decided to use the years since first publication to calculate the citations per year otherwise they were unrealistically high.
Step 5 Once the citations per year for all the citing books were found their mean and median were calculated. One practical problem was that in some cases none of the citing works were books so no average figure could be calculated. In this case the target book could not be normalized.
Step 6 The citations for the target books were normalized by dividing their citations per year by the average of the citations per year for their citing books.
4 Results
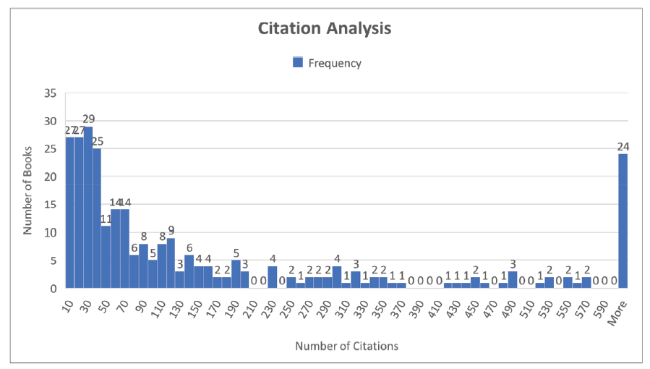
Figure 1. Citation frequency for the set of target books. |
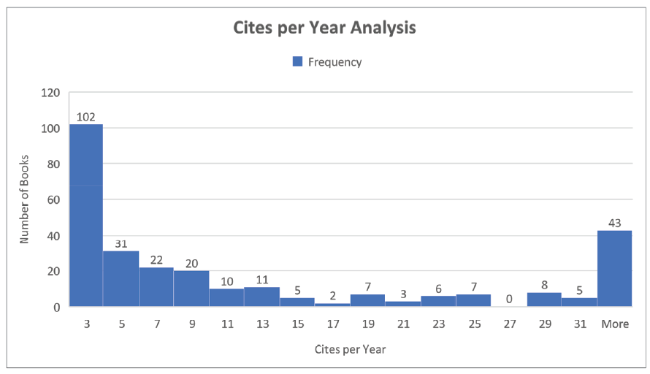
Figure 2. Frequency distribution of cites per year for target books. |
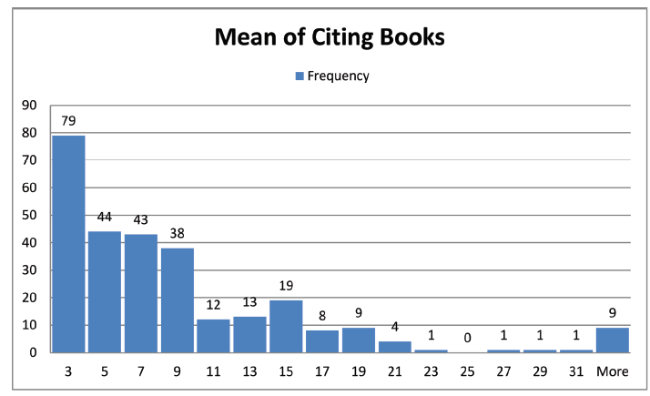
Figure 3. Distribution of the mean cites per year of the citing books for each target book. |
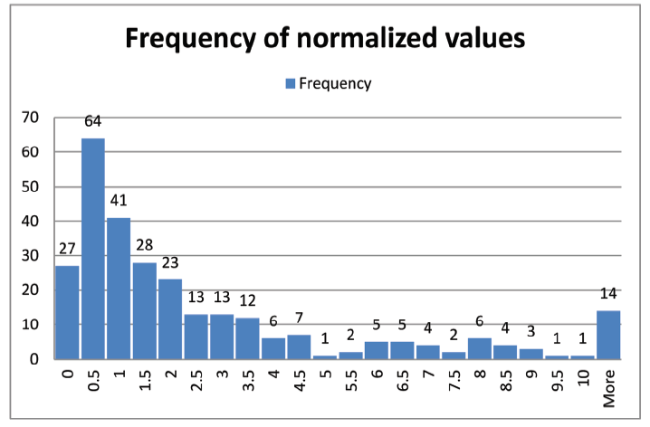
Finally, in Figure 4 , we see the distribution of the normalized data. With normalized citations, a value of 1 means that the book is being cited at the same rate as its reference set. Values above 1 show better citation rates and values below 1 show rates less good rates than the reference set.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 4. Distribution of normalized citation scores. |
Interesting, roughly half (53%) are above 1 and half below 1. Looking in more detail though, the 27 that have a value of zero are actually examples where there are no citing books and so a normalized value could not be calculated. After that, there are 64 (22%) up to and including 0.5 and a further 41 (14 %) up to 1. Generally, normalized values rarely go above 5 (i.e. 5 times the average citation rate) but here there are values going up to 74, which is certainly extreme. These large outliers were generally caused by very small mean citations of the citing books. For example, Cornford and Smithson (2005) had received 277 citations in 11 years, giving a rate of 27.2 per year. It had only eight citing books all of which had very few citations giving a mean citation rate of 0.37, thus generating the very high normalized value.
At the other extreme, there are books with very small normalized values, often because there was a citing book with a large number of citations which pushed the mean citations upwards. For example, Hecksher et al. (2003) has 44 citations but one of its citing books is Morgan’s (1986) “Images of Organization” which had 18,475 citations. Admittedly this was over 31 years but it still led to a large mean citations value giving a normalized score of 0.04. With this method it is better if books do not get cited by books that have very high citations.
In part, these extreme values are caused by there being relatively small numbers of citing books in each set generating mean citation scores with a large variance. We can also see that all the distributions are highly skewed and this affects the mean values significantly. Note that for the normalized cites, the mean is 3.2 but the median is close to 1. We will discuss possible ways of avoiding this later.
Table 2 Summary statistics for the citation distributions. |
| Mean | Median | SD | Skewness | Min | Max | |
|---|---|---|---|---|---|---|
| Cites of target books | 200.3 | 69 | 331.9 | 3.2 | 1.0 | 2,543 |
| Cites per year | 15.6 | 5.6 | 24.7 | 3 | 0.1 | 168.9 |
| Mean cites/year of citing books | 7.9 | 5.9 | 9.1 | 3.4 | 0.0 | 80.5 |
| Normalized cites | 3.2 | 1.1 | 7.5 | 6.3 | 0.0 | 74.5 |
Looking at Table 2 , we can see that the target set of books averaged 200 citations each in total and 15.6 per year. The median was significantly less at 69. The third row shows the summary statistics for the mean cites per year for the 283 sets of citing books. Thus the mean of 7.9 is actually a mean of means. Finally, the normalized citations have a mean of 3.2. That is, the target books are cited on average three times more than their reference sets. This may seem very high but it needs to be remembered that these books were submitted to the REF and would therefore be seen as very strong research books. There were over 12,000 outputs submitted to the REF but the vast majority were refereed journal papers as these were thought to be scored more highly so if books were submitted it was because they were felt to be very good. However, the median of this distribution is only 1.1 showing that the large outliers were affecting the mean and that the 50th percentile was in fact close to 1.
We also considered two ways to get around the problem of small sample sizes in the set of reference books. The first was to use the median cites per year for each set rather than the mean to avoid the influence of extreme outliers. However, as the distributions are positively skewed the medians are always lower and in fact the mean of the medians is 3.6, compared with 7.9 as the mean of the means. This results in the normalized values being even higher—a mean of 7.8 in comparison with 3.2—which seems excessively high.
The second approach was more radical. With the current hybrid methodology, each target book generates its own individual reference set of books and these sets can vary considerably in the number of citations they receive. We could move back to the more traditional cited-side approach and consider the complete set of citing books as the reference set for the whole field of business and management, and calculate a single overall mean for all of them. This value would then be used to normalize all the target books. This method would not be able to normalize between the target books within a subject but it would enable business and management to be normalized relative to the other fields. In the 2008 REF there were actually 68 subject panels so each would calculate its own normalization factor for books. This number was much reduced to only 36 panels in the 2014 REF.
With our data, the overall mean citation rate across all the citing books individually was 9.2 compared with 7.9 when they were taken in groups (the two values are different because of the different sizes of the sets). This makes the mean normalized value for the target books 1.7 compared with 3.2 with the individual sets method, which seems not unreasonable.
5 Conclusions
The aim of this paper was to investigate normalizing book citations using Google Scholar data. As far as we are aware, this has not been done before because there are no obvious reference sets with which to normalize books. For papers there are other papers published in the journal, or the journals of the field; for book chapters there are the other chapters in the book; and for conference papers there are the others from the conference. We have used GS because other citation databases do not yet cover books comprehensively. We have tested a novel hybrid method that uses the citing-side to generate a reference set of books for each target book but then uses their citations rather than their reference lists.
The results show that it is possible in principle to normalize books in this way. However, as with previous tests of GS for normalization, it is extremely time-consuming as it requires considerable manual intervention for searching and data correction in order to ensure even moderately reliable results. Indeed, GS data is quite unreliable and the user interface is crude.
The research threw up a more fundamental issue, what exactly is a book? There seems to be no precise or agreed definition of what should be classified as a book as opposed to a dissertation or a report for example. Both can have ISBNs as, indeed, can journals or journal papers where they are published stand-alone (https://www.isbn.org/faqs_isbn_eligibility). There are significant differences in practice between disciplines and between countries. Given that this is one of the fundamental categories in bibliometrics it surely deserves further research and debate.
Another fundamental question is how to understand and define the appropriate disciplinary field against which a book should be normalized, and how to measure the appropriate level of citation potential or citation rate. We have used the set of citing books as the field in this research, partly because of the lack of WoS-type field lists for books but also because it can be argued that this provides the most appropriate, fine-grained definition of a field unique for each focal book. It would be useful to have a more in-depth study of the disciplinary and citation fields of particular books to throw more light on these questions.
This paper is limited in that it is a fairly small-scale test—it would be interesting to conduct a much larger test perhaps using WoS or Scopus even though their repository of books is limited.
Author Contributions
John Mingers (j.mingers@kent.ac.uk) developed the concept and wrote the paper. Eren Kaymaz (ek361@kentforlife.net) collected and analyzed the data.