

1 Introduction
Knowledge organization systems (KOS) are developed to represent knowledge in publications and in natural and societal environments and used for information discovery and retrieval. Depending on the purpose, a KOS may be general and broad, such as the Library of Congress Subject Headings (LCSH), which is used to index books and other publications in library collections, while others may be very specific, such as the National Center for Biotechnology Information (NCBI) Taxonomy that serves as a nomenclature and classification for organisms (NCBI, 2018). Whether general or specific, traditional KOS are not designed for problem-solving purposes, but rather, as standards to normalize vocabularies and classification systems for organizing and retrieving data and information in different systems. As such, KOS aim at a complete, comprehensive coverage of the knowledge universe and emphasize the use of vocabulary to represent concepts and their relations from linguistic and scope perspective. The capabilities of inference or reasoning are not part of the design of these systems, even though relations in hierarchical and associative systems may imply the possibility for inferencing (e.g., the parent-child class relations in a hierarchical classification or the broader and narrower terms in a thesaurus). By contrast, knowledge representation (KR) in artificial intelligence (AI) applications produces a set of statements that express facts, relations, and conditions in formal languages or schemes upon which reasoning can be performed to determine actions or reach conclusions. The reasoning component is perhaps the most striking difference in KR between traditional knowledge organization and artificial intelligence (AI).
Despite differences between traditional knowledge organization (KO) and AI-style KR, the similarities between the two are perhaps more interesting for the KO community for a number of reasons. First, KR in the digital data era is closely tied to language and technology whether it is for KOS or for AI applications. Extracting or generalizing concepts and relations and expressing them in normalized, encoded formats have been extensively studied over the last 50 years by researchers from information science, computer science and other related disciplines. While pioneering work may be traced as far back as Alan Turing’s morphogenesis research (Turing, 1952) and the Weinberg panels and report on scientific information process and transfer (United States. President’s Science Advisory Committee, 1963), KR research flourished after computers became more efficient and more readily available. These studies generated and established similar techniques and methods (e.g., natural language processing, machine learning, and algorithms for concept detection/extraction) that have been applied in both KO and AI fields, such as graphical representations of knowledge or linked data (KO) and artificial neural networks (AI). Second, although the KO and AI communities as two research fields have largely developed in parallel in the past, this disconnection is being narrowed and the two fields started converging through advances in semantic web technologies and data science. The search for better and more effective ways to address the challenges that come with digital data and culture have prompted each community to look at the other for new ideas and methods. It is not uncommon, for example, to use machine learning algorithms to extract semantic relations or concepts from social tags (Castano & Varese, 2011; Chen et al., 2008) or classify concepts from research data (Kubat et al., 1993). Finally, there is an increase in KR convergence in the KO and AI communities, both from members’ desires to understand the implications of AI for KO and the urge to utilize state-of-the-art techniques and methods within the KO community, as shown from a recent discussion about AI and information science on the community forum of the Association for Information Science and Technology (ASIST) (Toms, 2019).
This paper will first briefly review the historical background of KR in both KO and AI in the last five decades, during which schematic representations of data and information became the main driving force for modernizing knowledge organization and representation. This brief review is by no means to be exhaustive and complete, but rather, it intends to present evidence to demonstrate the fundamental ideas of KR as a background understanding. While the historical background of KO and KR allows us to see and compare KR paradigms between traditional KO and AI, it is important to understand where paradigmatic similarities exist and how the two parallel fields are converging. Following the brief review and analysis, paradigmatic similarities and convergence of KR in KO and AI are discussed and case studies used to demonstrate the convergence trend.
2 Knowledge organization (KO) or knowledge representation (KR)?
What is knowledge representation? The answer to this question can take several different directions depending on which perspective one views KR. In the field of library and information science (LIS), the closest term to knowledge representation is knowledge organization, which in its narrow definition means “activities such as document description, indexing and classification performed in libraries, bibliographical databases, archives and other kinds of ‘memory institutions’ by librarians, archivists, information specialists, subject specialists, as well as by computer algorithms and laymen” (Hjørland, 2008). The focus here is placed on organizing and representing documents that embody knowledge. Hjørland (2008) further articulates that knowledge organization in its broader sense is about how knowledge is socially organized and how such knowledge organization systems (KOS) reflect reality. The activities involved in knowledge organization can be divided into two areas: first, knowledge is organized based on humans’ understanding of the world in various systems or tools such as classification schemes and thesauri, and second, these knowledge organization systems are applied by humans or machines to represent the document content through a generalized set of terms as the surrogate for the document. The activities of representing document content by using KOS can be deemed as a form of human-mediated knowledge representation due to the fact that the terms or classes are assigned to documents mainly by librarians or information specialists, although fully automated document representation does exist, such as the indexing service at LexisNexis, and the purpose of such activities is to organize the documents based on topics either on library shelves or in computer systems as catalogs and indexes for information discovery and use.
The deluge of digital data and information we have experienced in the last 30 years and our need to manage it puts traditional knowledge organization in the forefront. However, while “old tricks” in KO still work and are needed, they cannot keep up with the fast growth in the volume and complexity of digital data and information. Ontologies, as a special type of KOS, blend methods of classification and vocabulary control together with codified expressions and reasoning to handle the increasing complexity and volume of digital data and information. This new style of representing and organizing knowledge quickly attracted the attention of the LIS community. Early ontology models that emerged from the LIS community started with reengineering metadata models into ontologies, for example, the ABC ontology that used Entity as the root class and Artifact, Event, Situation, Action, Agent, Work, Manifestation, Item, Time, and Place as direct subclasses (Lagoze & Hunter, 2001), and the learning object ontology that remodeled the Gateway to Educational Materials (GEM) metadata schema into an ontological model (Qin & Paling, 2001). It should be pointed out here that these ontological models took an entity-centric, object-oriented view of the information world and presented a departure from term-dominant culture. Ontological models have also been developed and deployed to aggregate metadata from multiple sources and in multiple languages, as in the case of Europeana Data Model (Doerr et al., 2010), as well as in linking and opening datasets at cultural institutions to create broader access to art and archival collections, e.g., the well-known CIDOC Conceptual Reference Model (CRM) and the Linked Art Data Model (https://linked.art/model/index.html). After more than a decade’s exploration and testing, the library, archive, and museum (LAM) communities have made significant progress in developing ontology theories and practices. Even though whether linked data models and metadata models are a kind of ontologies is still debatable, the influence of ontological thinking in these modeling efforts is apparent.
The knowledge organization tradition in LIS has been summarized by Qin (2002) as falling into two paradigms: integration and disintegration. The integration paradigm has its root in the theory of “integrative levels” (Feibleman, 1954), which views the physical world as cumulative with increased complexity, and classification systems such as Dewey Decimal Classification (DDC) and the International Classification of Disease (IDC) are typical examples. The disintegration paradigm stands at the opposite: it does not use levels in organizing knowledge, but rather, focuses on the concept and all aspects related to it, which is also called “polyrepresentation” (Ingwersen, 1994). The spectrum from pragmatism to epistemologism represents the approaches utilizing the integration and disintegration paradigms.In the integration paradigm, both pragmatic and epistemological approaches share the same goal of organizing the universe of knowledge rather than solving problems (the left side of Figure 1 ), be it a hierarchical classification system, a faceted classification, or a system of controlled vocabulary with covert hierarchical relationships. In the disintegration paradigm, attention is given to data and problems in specific domains that require only relevant knowledge segments to solve the problems. As such, the scope of knowledge goes beyond publications to include data and other forms that embody knowledge. It is fair to say that, in the integration paradigm, the goal is to construct knowledge structures or systems to represent the knowledge universe by means of categorization, synthesis, and generalization, while the disintegration paradigm’s goal is to solve problems by using knowledge organization as a means. In this sense, the disintegration paradigm seems to be more aligned with the AI approaches in KR.
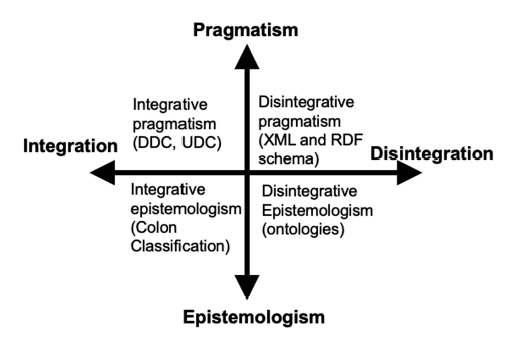
Figure 1. Paradigms in knowledge organization.^Source: Qin, 2002 |
From a methodological point of view, the integration paradigm is usually in favor of an enumerative (or “just-in-case”) approach, also called “pre-coordination” in KOS construction. The disintegration paradigm tends to represent the concepts in their smallest unit, often in the form of single word or short phrases without any subdivisions. This method allows simple concepts to be coordinated to express complex queries at the time of information retrieval, hence has been called “post-coordination” or “just-in-time” approach. Post-coordination has become the default method in many information systems for post-search filtering, which is another field of research with a vast body of publications and beyond the scope of this paper.
It is important to point out that KO activities and processes as well as KOS have some properties of KR, but they cannot be equated to KR in AI. Even though ontologies may be considered as the product of KR due to the fact that, in many ways, they resemble KR in artificial intelligence (AI), the objectives, methods through which KR is performed, and the outcomes differ fundamentally. Besides, not all KOS are born equally in purpose, complexity, and function. In this sense, KO is not an interchangeable term for KR. What is knowledge representation then?
3 What is knowledge representation?
There are many versions of the definition for knowledge representation in AI field. KR has been defined as “a set of syntactic and semantic conventions that makes it possible to describe things,” in which the syntax refers to “a set of rules for combining symbols so as to form valid expressions,” while semantics are the specification of how such expressions are to be interpreted (Bench-Capon, 1990). A more comprehensive definition is provided by Davies et al. (1993) who specify that a KR is a surrogate, a set of ontological commitments, a fragmentary theory of intelligent reasoning, a medium for efficient computation, and finally, a medium of human expression. Whether simple or comprehensive, these definitions share three core principles. First, knowledge about a domain can be represented systematically “in a sufficiently precise notation that it can be used in, or by, a computer program” and such a systematic representational method can be called a scheme (Hayes, 1974). According to Hayes (1974), such schemes include some programming languages, logical calculi, music notation, or “the systematic use of data structures to depict a world.” The term scheme signifies a symbolic paradigm of AI (Bench-Capon, 1990; Hoffmann, 1998).
Another core principle for KR is the formality of representational schemes. The formality of KR refers to the fact that the schemes used for representing knowledge meet the criteria of adequacy and expressiveness. The adequacy criterion relates to things that the representation must have if it is to do what it is required to do. In other words, we need to produce an adequate number of representations of physical objects in the world, and such representations should enable us to both express the facts we wish to express and allow us to perform reasoning by using such representations in problem solving; additionally, these representations should be manipulable by computer systems. Semantically, the representations should be unambiguous, uniform, notationally convenient, relevant, and declarative (Bench-Capon, 1990; Hayes, 1974). The adequacy and expressiveness criteria for representation naturally lead to a third principle: reasoning or making decisions for solving problems must be based on the facts represented by the schemes. The expert systems that were developed during the late 1980s and 1990s are good examples; for example, the MedIndex system developed at the U.S. National Library of Medicine used the knowledge base frames to guide indexers in completing indexing frames for medical research publications (Humphrey, 1989).
The principles above set the requirements for representing knowledge: they must be sufficiently precise and readable by computer programs to allow for reasoning in problem solving. Over the course of 30 years of KR research, the symbolic and connectionist paradigms have been prevalent in the AI field. While artificial intelligence has its intellectual predecessors from cognitive psychology, mathematics, philosophy of science, and cybernetics, the nature of intelligence and how to develop a formal theory of intelligence became the focus of early scholars in AI (Hoffmann, 1998). This influence is also clear in the study of KR, which has produced some classical works by pioneers such as Patrick J. Hayes, John McCarthy, Brian C. Smith, Ronald J. Brachman, Marvin Minsky, and others (Brachman, 1985). Three paradigms in KR emerged from research: (1) production rules (also called “symbolic paradigm” by Hoffmann (1998)) that are “the representation of knowledge as a set of condition action pairs,” (2) semantic networks (or simply nets) and frames that are rooted in efforts to build systems to understand natural language by structuring objects in graphs (in mathematics) or networks and object-oriented frames, and (3) first-order predicate calculus (also first-order logic) (Bench-Capon, 1990). Hoffmann (1998) named the semantic nets and frames as the “connectionist paradigm.” Whether it is rule-based, object-oriented, or logic-driven, these paradigms fulfill the expressive and adequacy criteria from different approaches and have strengths in different areas (as far as what these different approaches and strengths are, that would need another article to discuss).
4 Similarities between KO and KR paradigms
It is clear that paradigmatic differences exist between KO and KR in terms of the goals, methods, and functions. In general, KO works at the conceptual level and uses language to describe concepts with phrases or terms, while KR focuses on formalizing the expressions in natural language as well as other types of data to enable reasoning as in human intelligence. This seemingly wide gap between the KO and KR paradigms is being bridged by ontologies that have become popular since Berners-Lee et al. (2001) proposed the concept of semantic web. Ontologies by nature are “a formal, explicit specification of a shared conceptualization” (Gruber, 1993). Typically, an ontology defines concepts and specifies relations between them in a formal scheme that can be used for reasoning by computers. According to ISO 25964 Part 2, ontologies defined as such exclude thesauri, classification schemes, and structured vocabularies, even though these are sometimes called “lightweight ontologies” (ISO, 2013). As a specification of conceptualization, ontologies define classes of concepts or entities and relations between classes in a declarative formalism, which is then used to represent a set of objects (or instances). An example is the Gene Ontology (GO) that specifies about ten term elements and four main relations for gene terms from over 600,000 experimentally supported annotations. This central dataset offers “additional inference of over 6 million functional annotations for a diverse set of organisms spanning the tree of life” (Gene Ontology Consortium, 2019). Another example is Schema.org that contains a set of individual ontologies representing creative works, nontext objects, events, health and medical types, organizations, people, and other entities. From both ontologies, one can easily detect the inheritance of paradigms prevailed in the KO and KR communities.Table 1 provides a simplified summary of KO and KR paradigms based on goals, methods, and functions.
Table 1 Similarities in goals, methods, and functions between KO and KR paradigms. |
| Paradigm | Goals | Methods | Functions | |
|---|---|---|---|---|
| KO | Integration | Organize the knowledge universe | Categorize, classify generalize, synthesize | Represent knowledge in publications and organize knowledge about nature and/or society |
| Disintegration | Organize the knowledge in a domain | Categorize, classify, generalize, synthesize, model | Represent knowledge in data and publications in a domain | |
| KR | Production rules | Represent knowledge in condition-action pairs to solve problems | Use forward chaining algorithms to execute condition-action pairs | Represent fragmentary knowledge in entity-attribute-value (triple) format |
| Semantic networks and frames | Represent semantic relations between concepts | Express semantic relations in triples | Connect knowledge nodes through attributes or slots to form a knowledge graph | |
| First-order logic | Formalize qualifier construction in natural language | Express declarative propositions using the first-order logic syntax and semantics | Produce a set of axioms for reasoning | |
The disintegration paradigm in KO as shown in Figure 1 is marked by the adoption of ontology as a methodology in developing knowledge organization systems (KOS). This turned out to be revolutionary for the traditional KO paradigm; it prompted the community to reexamine the KOS structures and explore ways for KOS to fully take advantage of technology advances. One of the most visible efforts in this area is transforming traditional vocabularies into linked open data to allow for the vocabularies to have some ontology features. It is worth pointing out here that the resulting linked data sets (i.e., transformed controlled vocabularies or restructured bibliographic data) themselves are not ontologies; the model/framework together with the resulting linked data sets have been given the features and functions of ontologies, hence arguably can be considered as ontologies in the broadest sense. Remodeling controlled vocabularies into linked open data has made significant progress, as seen in linked data services offered by U.S. Library of Congress (http://id.loc.gov/) for its subject heading list and name authority file, among others, and the Getty Research Institute for its Art and Architecture Thesaurus (AAT), Thesaurus of Geographic Names (TGN), and the Union List of Artist Names (ULAN) (https://www.getty.edu/research/tools/vocabularies/lod/index.html).
Whether it is developing ontologies from scratch (as in the cases of Gene Ontology and Schema.org) or remodeling existing vocabularies, it appears that the use of ontologies as a methodology for conceptualizing domain knowledge concentrates on two key features from both KO and KR paradigms:
Formalism in representation schemes: the state-of-the-art encoding languages for ontologies offer a wide range of choices from Web Ontology Language to JSON. These representational languages allow for inference through the creation of axioms.
Structured objects as triples: The use of entity-attribute-value triples, for instance, (Jake age 18), is evidenced in rule-based paradigm as well as the semantic nets and frames. Although semantic nets and frames represent objects in a graph or network and are in a slightly different form from that used in a rule-based paradigm, the base representation is essentially the same triple structure.
Although the goals for KO and KR paradigms vary (Table 1 ), the similarities lie mainly in methods and functions. This new finding suggests that the KO community may look into the methodology and function similarities further to identify what new opportunities there may be for the KO community to make an impact in AI.
5 Challenging issues in KR
The paradigmatic similarities in KR between KO and AI offer not only theory foundations but also practicalities for KO to contribute its unique value for knowledge representation. As mentioned earlier in this paper, KR paradigms in AI follow two distinctive principles—the systematic, sufficiently precise representation schemes that can be processed by computer programs and the adequacy and expressiveness criteria in representing knowledge. Even though KO research has not yet directly discussed these theories and criteria and their implications to KO in the digital era, there have been numerous projects showing the adoption of such principles and criteria. For example, the Simple Knowledge Organization System (SKOS) and the Semantic Web technology standards suite (Resource Description Framework (RDF), Web Ontology Language (OWL), among others) have been used to convert, and sometimes crosswalk, existing knowledge organization systems into computer processable data structures and offer such structured data (linked data) as knowledge organization services.
While transforming existing KOS into structured data does have great value for open access and reuse of such data, it does not address the challenges in acquiring new knowledge for knowledge organization systems, a well-known bottleneck problem for knowledge representation in AI research. Both KO and KR face the same knowledge acquisition challenges not only because of the complexity of knowledge expressions in texts, data, and multimedia resources, but also due to the fast-changing language and terminologies in modern society and science and technology advances. Whether a logic-based, semantic net, or production-rule-based paradigm is used to represent knowledge, three things must be available for automatic knowledge acquisition: knowledge nodes (k-nodes), relations between the nodes, and rules (which may be labeled differently in different disciplinary fields). To address the bottleneck problem in knowledge acquisition will need an orchestration of natural language processing, machine learning, and clustering and classification techniques to acquire (new) knowledge from texts through clustering and classification (Fisher, 1987).
A recent study by Qin and her team (Qin & Zou, 2017; Qin et al., 2018) is such an attempt to build some foundation work for automatic knowledge acquisition from full-text articles. This study selected a sample of biomedical research papers to identify what types of knowledge nodes and relations may be extracted and expressed in semantic graphs. Table 2 contains example types of k-nodes derived from the sample publications. A further examination of the context of these k-nodes led to the discovery of some relation patterns or types (Table 3 ).
Table 2 Examples of knowledge nodes derived from the sample publications. |
| Category | Atomic level (name of things) | Concept level | Cluster level |
|---|---|---|---|
| Gene | Her2, BRCA1, BRCA2, EGFR | Oncogenes | EGFR mutations in lung cancer |
| Disease | Non-squamous carcinoma, squamous cell carcinoma | Non-small cell lung cancer | Lung cancer |
| Drug | Pertumzumab, Lmatinib, Crizotinib | Tyrosine kinase inhibitor | Oncogene de-addiction |
Source: Qin & Zou, 2017. |
Table 3 Major relationships types and patterns between knowledge nodes observed in the sample publications. |
| Relationship | Pattern | Example |
|---|---|---|
| has-biomarker | Disease has-biomarker Gene | chronic myeloid leukemia has-biomarker BCR-ABL non-small cell lung cancer has-biomarker EGFR |
| is-driver-of | Gene is-driver-of Disease | Her2 is-driver-of breast cancer c-Kit is-driver-of chronic granulocytic leukemia |
| targets | Drug targets Gene | Crizotinib targets ALK Olaparib targets BRCA1/2 |
| has-role-of | Drug has-role-of Treatment | Crizotinib has-role-of oncogene de-addiction Olaparib has-role-of DNA repair |
Source: Qin & Zou, 2017. |
These results were obtained by manual analysis of the article texts. A second study was performed to compare differences between manual and automatic detection of knowledge nodes and relations from natural language texts in the domain of biomedical research (Qin et al., 2018). While manual and automatic tools (MetaMap and SemRep) generated comparable results in identifying knowledge nodes or concepts, the automatic tools either totally missed or did a poor job in detecting relations between k-nodes compared to manually generated relations. In addition, not all relations detected manually had counterparts in the controlled vocabulary Unified Medical Language System (UMLS).
Acquiring and representing relations between k-nodes/concepts remains the most challenging problem in KR. Even powerful machine learning algorithms can fail to detect relations hidden in natural language that are critical for creating machine intelligence. This challenge calls for better algorithms for detecting k-node types and relation patterns for scaling up what human intelligence can achieve in k-node and relation detection. Fortunately, the well-established KOS can save a great deal of ground work for this type of effort. For example, UMLS has already identified a large number of relations as part of its vocabulary. Figure 2 shows part of the search results for the gene BRCA 1 (which causes breast cancer) in UMLS (which provides a long list of relations for this concept and Figure 2 shows only five of them).
Utilizing the data from UMLS, computer programs can be written to transform the data into the format suitable for KR. For example, the relations may be transformed into JSON format, one of the popular ontological encoding schemes:
{
“@context”: http://umls.gov/,
“@concept”: “BRCA1”,
“@semanticTypes”: “Gene or Genome”,
“@conceptRelations”: {
“@type”: “genetic analysis breast cancer gene (lab test)”
“@id”: “C2010863”
},
}
This simple example illustrates the potential for well-developed KOS to be restructured and/or remodeled to fit the needs of knowledge representation for artificial intelligence. However, transforming established KOS into KR-feasible structures would not be a trivial task. It is more than likely that new data and information will have to be added in order to make the transformation meaningful. As discussed above, relation detection and representation is still an area requiring further investigation. Manual methods can do a finer job than current tools, but would not be able to scale due to several constraints—the lack of specialized vocabulary sources, rules, and the difficulty in acquiring instances, to name only a few. Semi-automatic indexing, the middle ground between completely manual and completely automatic, has long been practiced to mitigate the problems in manual and automatic methods, e.g., the National Library of Medicine has been using an expert system to assist subject indexing for medical literature (Yang & Chute, 1994). The challenges are two sides: on the one hand, the KO community needs to leverage AI techniques and methods for developing new vocabularies and knowledge organization systems. On the other hand, the vast collections of knowledge organization systems established by years of research and development should also fulfill its value through contributing structured data to the knowledge acquisition and representation solutions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 2. A UMLS example of a concept and relation representation. |
6 Conclusion
The development of knowledge representation in AI provides ample opportunities and new perspectives for the KO community to reexamine the goals, methods, and products from KO activities. It is clear that some of the KO activities have already stepped into the KR domain, such as the linked data services mentioned earlier in this paper. Although the prospects that KOS may contribute to KR can be exciting, there is a need for more research to locate exactly where the trajectory is for KO to converge with KR. The topic of KO and KR paradigms involves much more than this paper has covered. Questions that are important and low-hanging fruit are waiting for exploration, such as How can automatic indexing be deployed by using well-formed KOS given born-digital documents and objects are the new norm today? How can KOS contribute to automatic knowledge acquisition and knowledge base building by using AI methods and techniques? The theory and methodology aspects in such a discussion will benefit both communities by broadening the research horizons in this field.