

1 Introduction
2 Methodology

Figure 2. Initial search and verified results of types of KOS. |
Table 2 Available serialization formats of KOS datasets (sorted based on data collected 2019). |
| Format | 2016 | 2017 | 2019 |
|---|---|---|---|
| JSON | 54 | 42 | 74 |
| HTML | 47 | 37 | 71 |
| XML | 55 | 42 | 69 |
| TSV | 44 | 30 | 63 |
| RDF+XML | 40 | 30 | 61 |
| DEFAULT/AUTO | 37 | 27 | 51 |
| TURTLE | 30 | 26 | 39 |
| CSV | 34 | 20 | 39 |
| N-TRIPLES | 26 | 18 | 36 |
| JAVASCRIPT | 23 | 11 | 31 |
| SPREADSHEET | 22 | 3 | 30 |
| PLAIN/TEXT | 20 | 21 | 28 |
| QUERY STRUCTURE | 15 | 15 | 23 |
| SERIALIZED PHP | 15 | 15 | 22 |
| JSON-LD | 3 | 1 |

Figure 3. Property checking (2016). |

Figure 4. Property checking (2019). |
3 Research findings and recommendations for LOD KOS as open datasets: FAIR
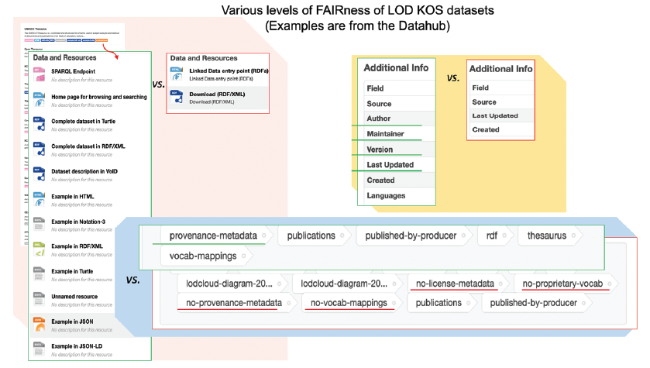
Figure 1. Various levels of FAIRness of LOD KOS datasets as seen from the Datahub. |
3.1 Findable
3.2 Accessible
RDF serialization formats, and provide examples in varying formats (e.g. left in
3.3 Interoperable
3.4 Reusable
4 Research findings and recommendations for LOD KOS as value vocabularies: FIT
4.1 Functional
Table 1 Number of SPARQL endpoints provided (data collected in 2016, 2017, and 2019 from the Datahub). |
| 2016 | 2017 | 2019 | ||||||
|---|---|---|---|---|---|---|---|---|
| Search Type of KOS/DATASET | # found | # with SPARQL endpoints | Search Type of KOS/DATASET | # found | # with SPARQL endpoints | Search Type of KOS/DATASET | # found | # with SPARQL endpoints |
| Thesaurus | 67 | 39 | Thesaurus | 79 | 40 | Thesaurus | 80 | 41 |
| Classification | 458 | 29 | Classification | 476 | 31 | Classification | 478 | 31 |
| Taxonomy | 26 | 8 | Taxonomy | 35 | 8 | Taxonomy | 37 | 10 |
| Terminology | 35 | 7 | Terminology | 39 | 8 | Terminology | 39 | 8 |
| List | 665 | 52 | List | 821 | 58 | List | 825 | 59 |
| Total | 1,251 | 135 | Total | 1,450 | 145 | Total | 1,459 | 149 |
Table 3 Query examples available by year. |
| Year | # of datasets | Endpoint provided | Endpoint no longer available | # providing default query | # providing example queries | # providing more than 3 example queries |
|---|---|---|---|---|---|---|
| 2019 | 1,459 | 149 | 74 | 66 | 26 | 9 |
| 2017 | 1,450 | 145 | 63 | 33 | 21 | 10 |
| 2016 | 1,251 | 135 | 29 | - | 16 | 6 |
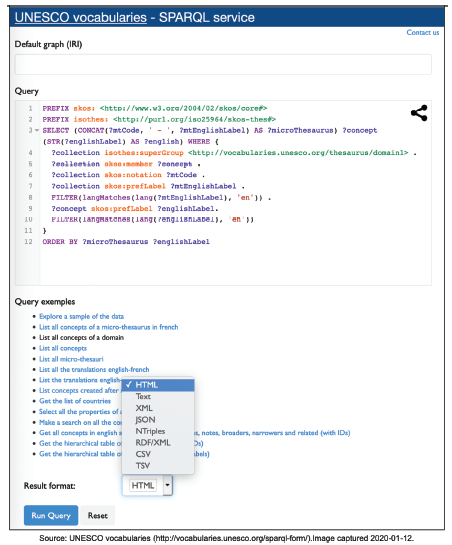
Figure 5. User friendly SPARQL service providing multiple templates for obtaining data. |
4.2 Impactful
The first recommended approach is to expose the LOD KOS vocabulary through terminology services such as vocabulary registries and repositories. The direct result of this action would be an increase of visibility. In our “KOS in the Semantic Web” study, major vocabulary registries and services are listed and explained, including (a) vocabulary registries and (b) vocabulary repositories/portals (Zeng, 2018)11)(11) https://www.isko.org/cyclo/interoperability.htm#app2).
a). Vocabulary registries offer information about vocabularies (i.e. metadata); they are the fundamental services for locating KOS products. The metadata usually contain both the descriptive contents and the management and provenance information. The registry may provide the data about the reuse of ontological classes and properties among the vocabularies, (e.g. at LOV)12)(12)https://lov.linkeddata.es/dataset/lov/), indicate the available RDF formats (e.g. at BARTOC)13)(13) https://bartoc.org/) and the mappings (e.g. at the Datahub).
b). Vocabulary repositories are services hosting the full content of a KOS vocabulary as well as the management data for each component, updated regularly on time. One prominent example of such a service is BioPortal, the world’s most comprehensive repository of biomedical KOS vocabularies. These terminology services’ primary functions include registering, publishing, and managing diverse vocabularies and schemas, as well as ensuring they are cross-linked, cross-walked, and searchable (Golub et al., 2014). KOS content such as concepts, classes, and relationships will become available in different kinds of tools via terminology services and may be used by humans or between machines. The impacts they bring to a KOS is clear as they facilitate KOS discovery, reuse, harmonization, and synergy across disciplines and communities. When exposing data to the terminology services, it is essential to fully follow the FAIR principles and the additional recommendations we provided in Section 3.
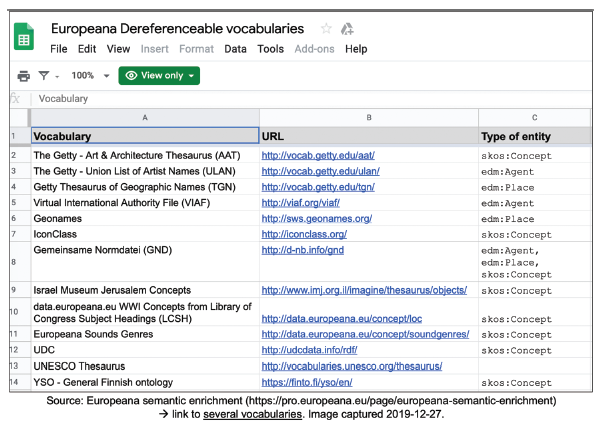
Figure 6. Vocabularies used by Europeana for semantic enrichment. |
4.3 Transformable

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 7. Query templates for ULAN and TGN (portion). |
5 Summary and conclusion
Table 4 FIT - Metrics for LOD KOS (as value vocabularies). |
| Functional | Impactful | Transformable |
|---|---|---|
| [The vocabulary is...] Made available in ways that enhance its inherent purpose Metrics: F1. The vocabulary is delivered in consumable formats F2. Provided SPARQL endpoints are operational F3. Dataset properties and structures are informed effectively F4. Services are user-friendly, making vocabulary contents reachable | [The vocabulary...] Maximizes the impact of a LOD KOS vocabulary Metrics: I1. Exposed through terminology services I2. Used by data providers a) as a primary value vocabulary b) in semantic enrichment I3. Mapped with other KOS vocabularies I4. Showed/discussed at professional conferences and publications | [The vocabulary...] Extends the functionality and impact through innovative adaptations Metrics: T1. Allows special KOS products to be derived from the original data T2. The user is given autonomy to determine what structure and information is desired and can be reproduced from the vocabulary T3. Enables extensibility to fit diverse needs T4. Supports innovative and transformative uses beyond normal “value vocabularies” |