

1 Introduction
2 Related work
2.1 Topic detection for online community
2.2 Sentiment analysis for online students
3 Introduction to LDA and FCA
3.1 Latent Dirichlet Allocation
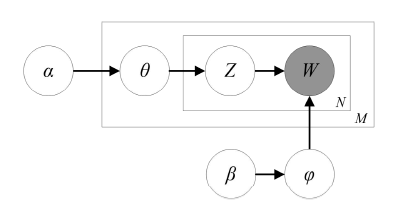
Figure 1. Schematic diagram of topic generation based on LDA model. |
3.2 Formal concept analysis
4 Topic sentiment analysis method
4.1 Design of the framework
4.2 Data preprocessing
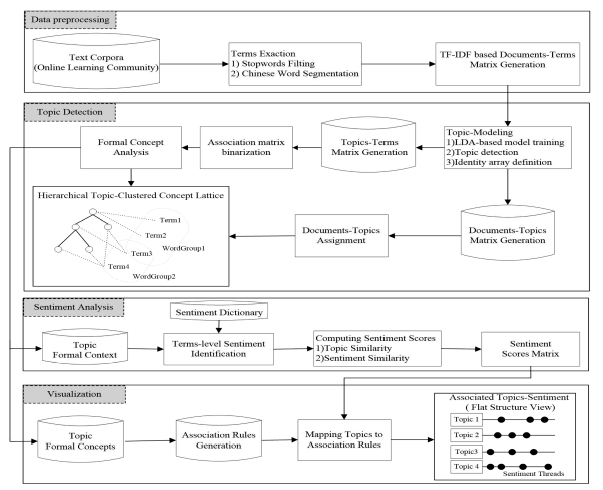
Figure 2. The overall structure of the proposed methodology. |
4.3 Topic detection
Table 1 A proposed method algorithm for topic-clustered concept lattice generation. |
| Input: A set of topic and comment documentation D, where | D |=n, the number of potential topics m. Output: A topic-clustered concept lattice CL, a topics-terms probability matrix P and a documents-topics probability matrix R. |
|---|
| 1. for each . |
| 2. . // Convert the document into a word segment. |
| 3. for each cws in CWSi. |
| 4. . // Obtain a collection of phrases that contains topic attribute. |
| 5. end for. |
| 6. end for. |
| 7. for each cws in CWSi. |
| 8. . // Calculate the term frequency of attributes. |
| 9. . // Obtain term frequency vector. |
| 10. end for. |
| 11. . // Perform topic detection. |
| 12. . // Classify topic association matrix. |
| 13. Find the subset of topic attributes represented as tj. |
| 14. for j=1 to 2m. |
| 15. Compute the set of objects by applying the Glois connection. |
| 16. . // Convert topic association matrix to multi-valued formalcontext. |
| 17. . // Convert multi-valued formalcontext to binary single-valuedformalcontext. |
| 18. . // Construct a hierarchical topic concept lattice. |
| 19. end for. |
| 20. Return . |
| 21. Derive the topic-clustered sets. |
4.4 Sentiment analysis
Table 2 Classification weights for adverb of degree. |
| Level(weights) | Included adverbs |
|---|---|
| adv1(1.5) | excessively, completely, extensively, dreadfully, entirely, absulutely |
| adv2(1.3) | fairly, pretty, rather, quite, very, much, greatly, by far, hightly, deeply |
| adv3(1.1) | really, almost, nearly, bven, just, still |
| adv4(1) | slightly, a little, a bit, trifle, somewhat |
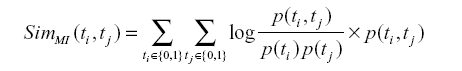
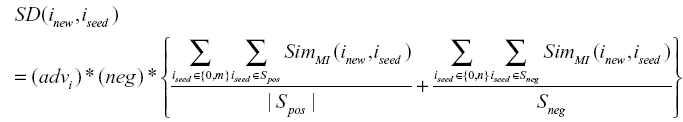
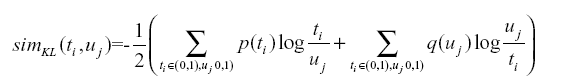
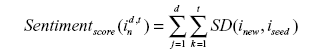
Table 3 A proposed method algorithm for calculating sentiment scores matrix. |
| Input: A topic formal context K=(U, T, I),where U={u1,u2,…,un} represents a set of topics belonging to a group of students, T={t1,t2,…,tm}, n is the size of student set, m is the size of topics. Output: A sentiment scores matrix Sentimentscore(ti), where irepresents sentiment score of each topic. |
|---|
| 1. for each topic ti in T. |
| 2. Sentimentscore(ti)=0. |
| 3. P(ti, ui)=0. |
| 4. Derive the positive and negative seed terms on the basis of domain experts. 5. Compute simKL(ti, uj) // Compute the mutual information. 6. Compute SD(ti, tseed) // Compute the sentiment comprehensive value. |
| 7. for each topic of student uj in the topic formal context K. |
| 8. SD(ti, uj)=0. |
| 9. for each topic of tiin the topic formal context K. |
| 10. SD(ti, uj)= SD(ti, tseed)+ SD(uj, tseed). 11. end for. |
| 12. Sentimentscore(ti)= Sentimentscore(ti)+ SD(ti, uj). |
| 13. end for. |
| 14. end for. |
| 15. Return Sentimentscore(ti). |
Note: For the selection of positive and negative seed terms, domain expert refers to ten participants, including authors, who use Borda counts to vote on different seed terms. Specifically, for any term to be classified, it is called three alternative sentiment datasets (positive sentiment, negative sentiment, and neutral sentiment), sorted by score, and finally classified as the highest according to the majority voting principle. |
4.5 Visualization based on FCA
5 Implementation
Table 4 Recognition results of topic terms. |
| Topic | Term and its probability |
|---|---|
| T1 | Course selection/0.023, Learning objectives/0.021, Difficulty of knowledge/0.018, Teaching methods/0.017, Guidance methods/0.013 |
| T2 | Credits/0.025, Content organization/0.023, Teaching methods/0.021, Learning support/0.021, Homework and assessment methods/0.020 |
| T3 | Case presentation/0.032, Procedural evaluation/0.031, Knowledge expansion/0.029, Analysis of difficult points/0.027, Group discussion/0.027 |
| T4 | Communication and feedback/0.033, Resource sharing/0.033, Information update/0.032, Response time/0.031, Information acceptance/0.030 |
T1: Instructional design; T2: Course content; T3: Teaching effect; T4: Teaching interaction. |
Table 5 Multi-valued sentiment formal context based on topic association matrix. |
| T1 | T2 | T3 | T4 | |
|---|---|---|---|---|
| D1 | -3.427 | 2.874 | 4.315 | -1.306 |
| D2 | 2.641 | -0.597 | -2.105 | 2.635 |
| D3 | 4.715 | 2.132 | 1.624 | 0 |
| D4 | 2.334 | 0 | -1.748 | 4.316 |
| D5 | -3.619 | -1.857 | 3.624 | -0.391 |
| D6 | -2.107 | 2.167 | 2.419 | 2.361 |
| D7 | 0 | -0.524 | -0.267 | 2.638 |
| D8 | 2.369 | 1.629 | 2.364 | 0 |
| D9 | 1.024 | -0.121 | 3.478 | 2.964 |
| D10 | 2.361 | 1.493 | -0.328 | -1.267 |
Table 6 The binary sentiment of the single-valued formal context. |

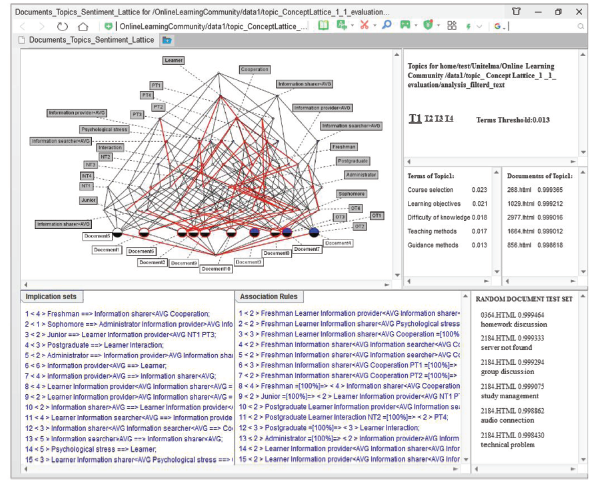
Figure 3. A screenshot of the tool of documents-topics for sentiment mining. |
6 Results and discussions
6.1 Analysis of the implication rules and association rules
6.2 Experimental verification and evaluation criteria
Table 7 The implication rules and association rules. |
| Association rules | 1<3>Learner Information provider<AVG NT2=[100%]=><3>Information searcher>AVG; |
|---|---|
| 2<4>Learner Psychological stress PT1=[75%]=><3>Information provider<AVG NT3; | |
| 3<4>Learner NT2 =[75%]=><3>Interaction; | |
| 4<4>Learner NT2 =[75%]=><3>Information sharer>AVG Information searcher>AVG; | |
| 5<3>Learner Information sharer<AVG Psychological stress Cooperation PT1=[67%]=><2> Information provider<AVG NT3; | |
| 6<3>Learner Information searcher>AVG Psychological stress PT1 NT3 =[67%]=><2> Postgraduate Information searcher<AVG Interaction; | |
| 7<3>Learner Information provider<AVG PT1 PT4=[67%]=><2>Information searcher<AVG NT2; | |
| 8<3> Learner Information provider<AVG Information searcher<AVG NT2=[67%]=><2> Information sharer>AVG Psychological stress Interaction; | |
| 9<3>Learner NT2 PT4 =[67%]=><2>Postgraduate Interaction; | |
| 10<3>Learner NT2 PT4 =[67%]=><2>Information sharer<AVG; | |
| Implication rules | 1<2>Learner Information sharer>AVGInteraction cooperation ==> Information searcher>AVG Psychological stress PT2; |
| 2<2>Learner Interaction sharer>AVG NT3==> Information searcher<AVG Psychological stress; | |
| 3<2>Learner Information searcher>AVG Interaction cooperation ==> Information sharer>AVG Psychological stress PT4; |
Note: The pre-setting condition for the association rule is (Preconditions contain learners= [>50%] => Conclusions related to student behavior); The pre-setting condition for the implication rule is (Preconditions related to student behaviors => Conclusions related to student identities or student behaviors). When the frequency of the user behavior in |
6.3 Illustrative example
Table 8 Precision contrast between different methods based on SVM. |
| St1 | St2 | St3 | St4 | St5 | St6 | St7 | |
|---|---|---|---|---|---|---|---|
| RA | 49.32 | 37.51 | 40.67 | 42.52 | 43.77 | 41.26 | 45.33 |
| CG | 52.33 | 34.96 | 38.79 | 41.68 | 40.17 | 37.74 | 42.59 |
| CoT | 57.73 | 46.28 | 48.85 | 44.84 | 51.39 | 47.77 | 48.25 |
| TextBlob | 58.86 | 45.16 | 46.07 | 42.33 | 52.78 | 45.56 | 52.63 |
| TSAOLC | 61.34 | 50.23 | 54.95 | 49.83 | 53.95 | 62.98 | 54.36 |
Table 9 Recall contrast between different methods based on SVM. |
| St1 | St2 | St3 | St4 | St5 | St6 | St7 | |
|---|---|---|---|---|---|---|---|
| RA | 44.45 | 42.06 | 47.64 | 44.37 | 45.98 | 41.63 | 48.21 |
| CG | 42.68 | 40.97 | 48.86 | 42.07 | 43.63 | 42.88 | 47.71 |
| CoT | 49.99 | 47.38 | 52.84 | 55.36 | 52.09 | 49.23 | 53.84 |
| TextBlob | 54.18 | 45.84 | 51.67 | 58.07 | 62.29 | 53.46 | 60.06 |
| TSAOLC | 56.49 | 58.03 | 62.27 | 59.96 | 65.59 | 58.76 | 62.34 |
Table 1 0. F-measure contrast between different methods based on SVM. |
| St1 | St2 | St3 | St4 | St5 | St6 | St7 | |
|---|---|---|---|---|---|---|---|
| RA | 46.67 | 39.65 | 43.88 | 43.43 | 44.85 | 41.44 | 46.73 |
| CG | 47.01 | 37.73 | 43.25 | 41.87 | 41.83 | 40.15 | 45.00 |
| CoT | 53.58 | 46.82 | 50.77 | 49.55 | 51.74 | 48.49 | 50.89 |
| TextBlob | 56.42 | 45.50 | 48.71 | 48.97 | 57.14 | 49.19 | 56.10 |
| TSAOLC | 58.82 | 53.85 | 59.38 | 54.43 | 59.20 | 60.80 | 58.08 |
Table 1 1. MAE contrast between different methods based on SVM. |
| St1 | St2 | St3 | St4 | St5 | St6 | St7 | |
|---|---|---|---|---|---|---|---|
| RA | 98.42 | 92.46 | 90.87 | 88.38 | 89.07 | 91.45 | 95.63 |
| CG | 82.03 | 85.56 | 87.69 | 89.06 | 92.61 | 94.97 | 86.36 |
| CoT | 78.84 | 76.34 | 72.19 | 68.78 | 75.43 | 76.35 | 78.62 |
| TextBlob | 72.93 | 67.45 | 69.37 | 64.92 | 70.14 | 68.62 | 62.15 |
| TSAOLC | 58.99 | 54.56 | 57.32 | 55.25 | 57.20 | 59.15 | 53.13 |
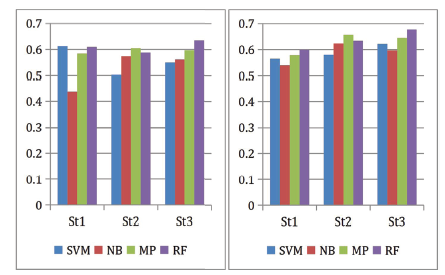
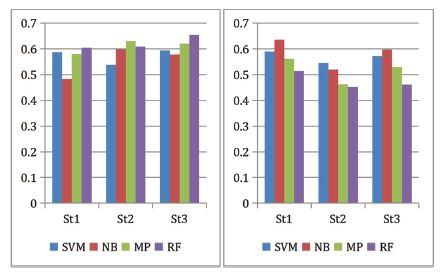
Figure 4. Precision (left) and recall (right) comparison based on various classifiers. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 5. F-measure (left) and MAE (right) comparison based on various classifiers. |