

1 Introduction
In recent years, we witnessed a general trend in research evaluation to measure the impact research has on society (beyond science) or the attention research receives from other parts of society. Whereas in the UK Research Excellence Framework (REF) the case-study approach was used for societal impact measurements, altmetrics has been proposed to measure impact or attention quantitatively (Bornmann, Haunschild, & Adams, 2019). Since the introduction of altmetrics, most quantitative studies focussed on Mendeley or Twitter data (e.g. saves of publications in this online reference manager and short messages with links to publications, respectively). Whereas Mendeley data might be useful in research evaluation to measure the early impact of publications (which can be scarcely measured by citations) (Thelwall, 2018), the usefulness of Twitter counts has frequently been questioned (e.g. Bornmann, 2015; Robinson-Garcia et al., 2017).
Hellsten and Leydesdorff (2020) analyzed Twitter data and mapped the co-occurrences of hashtags (as representation of topics) and usernames (as addressed actors). The resulting networks can show the relationships between three different types of nodes: authors, actors, and topics. The maps demonstrate how actors and topics are co-addressed in science-related communications. Wouters, Zahedi, and Costas (2019) discussed such an approach as a new and valid procedure to use social media data in research evaluation. Recently, Haunschild et al. (2019) explored a network-oriented approach for using Twitter data in research evaluation. Such a methodology can be used to measure the public discussion around a field or topic. For example, Haunschild et al. (2019) based their study on papers about climate change.
This approach can be used to study how the public discusses a certain topic differently from the discussion of the topic in the research community. In this study, we use all papers published during the period 2010-2017 in journals covered by the subject category “Information Science & Library Science” in the Web of Science (WoS, Clarivate Analytics). The objective is to explore the publicly discussed topics in comparison to topics of research as discussed within the journals classified as library and information science (LIS) by Clarivate Analytics.①(① This is a substantially extended study based on our ISSI 2019 conference contribution (Haunschild, Leydesdorff, & Bornmann, 2019), entitled “Library and Information Science papers as Topics on Twitter: A network approach to measuring public attention”.)
2 Methodology
2.1 Datasets
We used the WoS data of the in-house database of the Max Planck Society (MPG) derived from the Science Citation Index Expanded (SCI-E), Social Sciences Citation Index (SSCI), and Arts and Humanities Citation Index (AHCI) licensed from Clarivate Analytics (Philadelphia, USA). In this database, 86,657 papers were assigned to the WoS subject category “Information Science & Library Science” and published between 2010 and 2017. Of these papers, 31,348 (36.2%) have a DOI in the database. Following previous studies (Bornmann, Haunschild, & Marx, 2016), we used the Perl module Bib::CrossRef②(② See http://search.cpan.org/dist/Bib-CrossRef/lib/Bib/CrossRef.pm) to search for additional DOIs. Only 2,478 additional DOIs were obtained by this procedure. The combined set of WoS and CrossRef DOIs was searched for DOIs occurring multiple times. Such DOIs were removed. Finally, a set of 33,312 papers (38.4%) with DOI was obtained.
The company Altmetric.com (see https://www.altmetric.com) tracks mentions of scientific papers in various altmetrics sources (e.g. Twitter, Facebook, news outlets, and Wikipedia). Twitter is monitored by the company Altmetric.com for tweets that reference scientific papers. Tweets may refer to the content of papers. Twitter users often use hashtags to index their tweets. News outlets are also monitored by the company Altmetric.com for online news items which reference scientific papers (via direct links and text mining or unique identifiers in, e.g. the Washington Post). Altmetric.com provides free access to the resulting datasets for research purposes for free via their API or snapshots.
We received the most recent snapshot from Altmetric.com on October 30, 2019. This snapshot was imported and processed in our locally maintained PostgreSQL database at the Max Planck Institute for Solid State Research. We used the combined set of 33,312 papers to match them via the DOIs with our locally maintained database of altmetrics data. In Haunschild, Leydesdorff, and Bornmann (2019) an earlier snapshot from Altmetric.com from 10th June 2018 was used. Recently, we found data problems regarding this data snapshot: (i) Altmetric.com offered a partial dataset, the limitations of which were not made clear at the time of delivery. (ii) Inadvertently, we did not import all data provided by Altmetric.com at that time into our local database due to an error in our routine. Therefore, we used the newer data snapshot for this study (see also Haunschild et al., 2020).
2.2 Data
In the most-recent Altmetric.com data dump no tweet URLs were available but only the IDs of tweets. We used these tweet IDs to download the 87,529 tweets with all additionally available information from the Twitter API using R (R Core Team, 2019) between 5th and 6th November 2019. We are interested in all author keywords and hashtags, including name variants. Since these names start with the # sign, no stop-word list is needed. The most frequently occurring author keywords and hashtags were selected for further analysis (see below). We used a cosine-normalized term co-occurrence matrix generated with a dedicated routine written in Visual Basic (see https://www.leydesdorff.net/software/twitter).
We exported four different sets of author keywords: (1) author keywords of all LIS papers, (2) author keywords of not-tweeted papers, (3) author keywords of papers tweeted at least twice, and (4) author keywords of papers tweeted at least twice and mentioned in news outlets at least once. In total 1,366 different author keywords occurred in LIS papers tweeted by at least two accounts and mentioned in news outlets at least once; 211 of these author keywords occurred at least twice, and 65 of them occurred at least three times. We used the top-65 author keywords of the sets of the different author keywords in order to compare networks of the same and a displayable size.
When we refer below to “tweeted papers”, only papers tweeted at least twice are meant. When we refer to “not-tweeted papers”, indeed not-tweeted papers are meant. Papers tweeted exactly once (n=3,908 papers) are not included in the analysis in order to reduce noise. Many papers are tweeted only a single time by the publisher or the authors themselves for self-promotion. We consider these single occurrences as noise.
2.3 Visualization
The resulting files (containing cosine-normalized distributions of terms in the Pajek format, see http://mrvar.fdv.uni-lj.si/pajek) were laid-out using the algorithm of Kamada and Kawai (1989) in Pajek and then exported to VOSviewer v.1.6.12 for visualizations. The community-searching algorithm in VOSviewer was employed with a resolution parameter of 1.0, minimum cluster size of 1, 10 random starts, 10 iterations, a random seed of 0, and the option “merge small clusters” enabled. The size of a node indicates the frequency of co-occurrence of a specific term with all other terms on the map. Lines between two nodes and their thickness indicate the co-occurrence frequency of these specific terms.
3 Results
3.1 Author keywords

Figure 1. Top-65 author keywords of LIS papers published between 2011 and 2017. An interactive version of this network can be viewed at https://tinyurl.com/qwvtoeq. Note that the colour scheme may be different in the interactive version. |
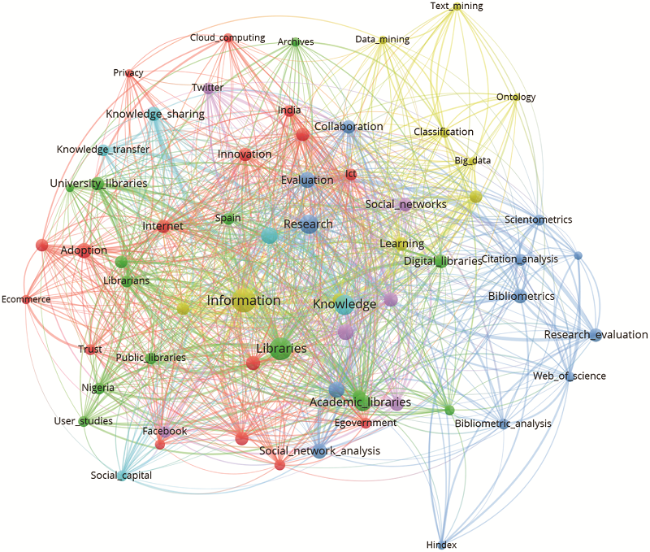
Figure 2. Top-64 author keywords of not-tweeted LIS papers published between 2011 and 2017. An interactive version of this network can be viewed at: https://tinyurl.com/u3569lc. Note that the colour scheme may be different in the interactive version. |

Figure 3. Top-63 author keywords of LIS papers tweeted and published between 2011 and 2017. An interactive version of this network can be viewed at: https://tinyurl.com/rfmy4vz. Note that the colour scheme may be different in the interactive version. |
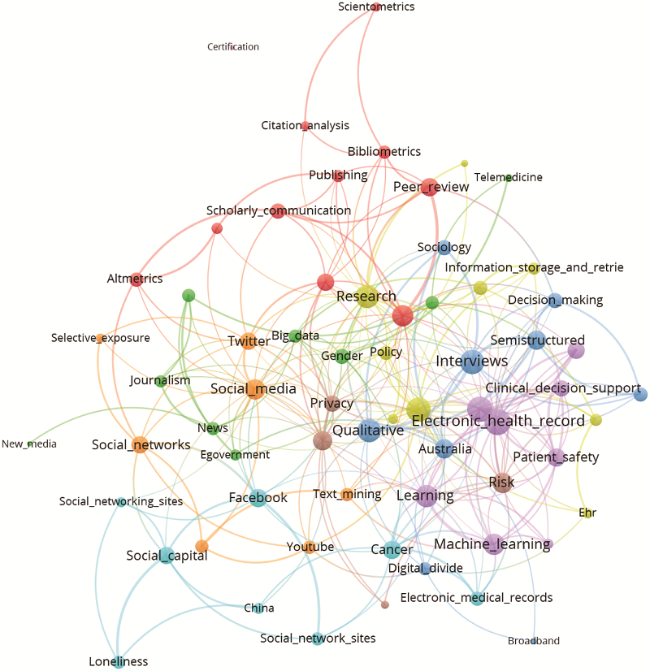
Figure 4. Top-65 author keywords of LIS papers tweeted, mentioned in news outlets at least once, and published between 2011 and 2017. An interactive version of this network can be viewed at: https://tinyurl.com/twssvt5. Note that the colour scheme may be different in the interactive version. |
Table 1 Overlap between top author keywords. The lower triangle shows the absolute number of overlapping keywords and the upper triangle shows the proportion of overlapping keywords. |
| All | Not tweeted | Tweeted | Tweeted and mentioned in the news | |
|---|---|---|---|---|
| All | 65 | 85.9% | 74.6% | 36.9% |
| Not tweeted | 55 | 64 | 58.7% | 29.7% |
| Tweeted | 47 | 37 | 63 | 44.4% |
| Tweeted and mentioned in the news | 24 | 19 | 28 | 65 |
The focus of top author keyword selection varies slightly from all and not-tweeted publications to publications tweeted at least twice, but the focus varies significantly to publications tweeted at least twice and also mentioned in news outlets. These results suggest that Twitter activity is rather high in library and information sciences in comparison with other subject categories (Bornmann & Haunschild, 2016). Most of the topics seem to be used both on Twitter and in the scholarly literature. Most of these author keywords of LIS papers which were mentioned also in news outlets have a strong thematic relation to health care.
3.2 Hashtags
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
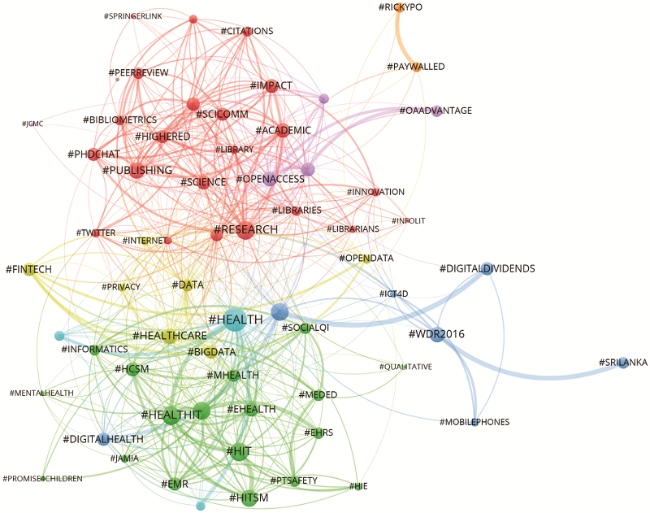
Figure 5. Top-65 hashtags from tweets which mentioned a LIS paper published between 2011 and 2017. An interactive version of this network can be viewed at: https://tinyurl.com/sv8gpax. Note that the colour scheme may be different in the interactive version. |
The semantic map in Figure 5 shows many hashtags which are mainly related to the author keywords of the semantic map in Figure 4 but also hashtags which seem to be unrelated to all other semantic maps, e.g. most of the hashtags in the green, light-blue, blue, and orange clusters. Many other hashtags focus stronger on specific events and buzzwords, e.g. “#WDR2016”, “#ICT4D”, “#PAYWALLED”, and “#WIKILEAKS” than the author keywords.
4 Discussion and conclusions
Many scientometric studies used Twitter counts for measuring societal impact, but the meaningfulness of this data for these measurements in research evaluations (or measurements of attention) has been questioned (Haunschild et al., 2019). We followed our recent proposal (Haunschild et al., 2019) to focus on hashtags in tweets and author keywords in scientific papers in separate sets to differentiate public discussions of certain topics from their addressing in research. We analyzed three datasets: (1) author keywords of all LIS papers, (2) author keywords of not tweeted papers, (3) author keywords of papers tweeted at least twice, and (4) author keywords of papers tweeted at least twice and mentioned in news outlets at least once.
Our results show that topics in LIS papers seem to be represented rather well on Twitter. Similar topics appear in the networks of author keywords of all LIS papers, not tweeted LIS papers, and tweeted LIS papers. The networks of the author keywords of all LIS papers and not tweeted LIS papers are most similar to each other in terms of author keyword overlap. Larger differences were found between these first three networks of scholarly communications, and the networks of hashtags and the networks author keywords of LIS papers which were tweeted by at least two accounts and mentioned in news outlets at least once as representations of public discourse. Both, the latter scholarly discourses and the tweets, are oriented towards digital and electronic health care more than tweeted LIS papers, not tweeted LIS papers, or all LIS papers. Our results confirm that only specific aspects of research outcomes intersect directly with the attention of the general public. Moving from the author keywords of all LIS papers to those author keywords of tweeted papers and those author keywords of papers additionally mentioned in the news, the focus shifts from theoretical applications and methodologies to health-applications, social media, privacy issues, and sociological studies.
Although we used another dump of data from Altmetric.com in this study than in our ISSI 2019 conference contribution (Haunschild, Leydesdorff, & Bornmann, 2019), the conclusions and interpretations in that conference paper were confirmed. In a similar paper on discussions about climate change, Haunschild et al. (2019) came to the following conclusion: “publications using scientific jargon are less likely to be tweeted than publications using more general keywords” (p. 18). A similar tendency was not visible in the current study using LIS papers and tweets as data. A possible reason for the difference is that the scientific jargon in LIS is less technical than in climate-change research.
Author contributions
Proposing the research problems: Robin Haunschild (R.Haunschild@fkf.mpg.de), Loet Leydesdorff (loet@leydesdorff.net), Lutz Bornmann (bornmann@gv.mpg.de); performing the research: RH, LL, LB; designing the research framework: RH, LL, LB; collecting and analyzing the data: RH; software development: RH, LL; writing and revising the manuscript: RH, LL, LB.