

1 Introduction
For scientific discovery and technological foresight, mapping the evolution of topics and detecting emerging topics in science and technology has been of interest to governments, companies, and individual scientists for many years.
With the development of natural language processing and information extraction techniques, text mining research is attracting more and more attention. Swan and Jensen (2000) presented the TimeMines system, which can detect, rank, and group terms or keywords from data-tagged free text corpora based on their statistical properties. Havre et al. (2002) developed the ThemeRiver visualization system to depict thematic variations over time within a large collection of documents. These systems, however, are neither open source nor freely available to other researchers. In recent years, many methods for topic evolution research based on probabilistic topic models have been published, and such models include, in particular, the seminal topic models of PLSA (probabilistic latent semantic analysis) and LDA (latent dirichlet allocation). Zhou, Yu, and Hu (2017) reviewed notable research on topic evolution based on probabilistic topic models from multiple aspects over the past decade. A certain level of computer programming skills is required, however, to establish and improve probabilistic topic models. It is thus necessary to standardize the synonyms and abbreviations for identical terms or to stop using certain terms to improve analysis results and to make them more accurate, but this is difficult to automate.
VOSviewer is an open source computer program for creating, visualizing, and exploring bibliometric maps (Van Eck & Waltman, 2010). It has been widely used by researchers from different research domains, such as entrepreneurship (Sassetti et al., 2018; Santos, Marques, & Ferreira, 2018), road safety (Zou, Yue, & Vu, 2018), biochemical engineering (Khudzari et al., 2018), psychology (Zyoud et al., 2018), knowledge management (Gaviria-Marin, Merigo, & Popa, 2018) and medical informatics (Chen et al., 2019). Since the release of version 1.4.0, based on the Apache OpenNLP toolkit (http://incubator.apache.org/opennlp/) and linguistic filter, extensive text mining functionality has been included in VOSviewer (Van Eck & Waltman, 2011). Little research, however, has mentioned both the text mining and thesaurus in VOSviewer’s data-cleaning functionality. Meanwhile, VOSviewer offers a direct visualization of a keywords map, giving a vague impression about temporal evolution and assigning colors to terms according to the average year of the publications that use them. The temporal evolution map for “perovskite solar cells research” generated directly by VOSviewer is shown in Figure 1 ; it only includes the dominant keywords and can neither detect nor reveal emerging topics in great detail.
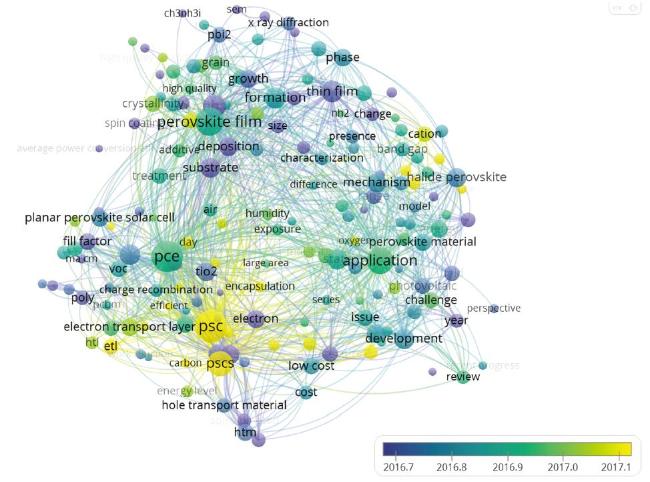
Figure 1. A temporal evolution map of VOSviewer. |
In this paper, through natural language processing techniques, information extraction techniques and thesaurus functionality provided by the open source bibliometric software VOSviewer, as well as some general functions provided by the easily accessible software Microsoft Office, we develop a flexible approach for topic evolution and emerging topic analysis on all kinds of data-tagged text. Our approach can be applied by researchers in both the bibliometric and scientometric communities, as well as in specific science and technology research domains; in addition, computer programming skills are not necessarily required.
2 Method
The mapping and clustering results of VOSviewer can be saved as map and network files. These file types can be viewed and edited using a text editor or a spreadsheet program (e.g. Excel) (Van Eck & Waltman, 2018). We make the most of the map file in our method, since the map file contains information about the items in a map, and items are characterized by a number of attributes. Each column in a map file corresponds to an attribute, as Figure 2 shows. The “label,” “cluster,” “weight <Total link strength>,” and “weight <Occurrences>” data in the map files are applied during topic evolution and emerging topic analysis in this paper, where “label” represents the terms of the research domain. For a given item, the “weight <Links>” indicates the number of links of an item with other items, whereas the “weight <Total link strength>” indicates the total strength of the links of an item with other items.
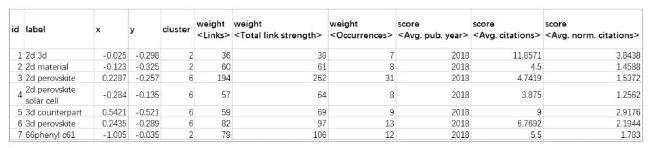
Figure 2. A map file generated by VOSviewer. |
The general approach includes:
• Data collection: Text data can be collected from commercial scientific literature databases like Web of Science and Scopus, and they can also be collected from project and newspaper websites. Through text pre-processing, both scientific literature and non-scientific literature can be analyzed. When putting the full text context in the “title” or “abstract” attributes, text mining analysis can be theoretically done in full text.
• Data slicing: To construct time series text data for trend analysis, text data should be sliced into several subperiods with an appropriate time span. This time span can be selected flexibly according to the amount of literature and the purpose of the research.
• Thesaurus construction: For a better analysis performance, a thesaurus file should be established during the pre-text mining procedure to merge terms and clean data. A thesaurus file has a “label” column and a “replace by” column, and the content in the “label” column will be replaced by the context in the “replace by” column. When the “replace by” column is empty, the content in the corresponding “label” column will be ignored (Van Eck & Waltman, 2018). This function can be utilized to stop the use of terms. In addition, some repeated construction processes are needed for an accurate thesaurus.
• Text mining and map files generation: Based on the thesaurus file, every meaningful text mining result by VOSviewer is saved as a map file for further analysis.
• Map files treatment and analysis: To identify the emerging terms of each subperiod, the “LOOKUP” function of Excel (Microsoft Office, 2019) is applied. By searching the “label” column in the map files, comparing the “label” column to previous subperiods and returning the information in the “weight <Occurrences>” column, emerging terms are detected. In addition, the content “#N/A” means that the relevant label or term does not exist in the compared subperiod’s text data.
• Visualization: This topic evolution and emerging topic analysis can be further visualized using other pieces of open source and easily accessible software such as Microsoft Office PowerPoint and Excel. Variations of term occurrences can also be accounted for and visualized, and future trends of terms can be forecasted by analyzing the increase or decrease of term occurrences.
3 Application
To show our analytical topic evolution and emerging topic method in a detailed and intuitive way, the “perovskite solar cells” (PSCs) research domain is used as an example.

Figure 3. The general approach to topic evolution and emerging topic analysis based on VOSviewer and Microsoft Office. |
3.1 Data collection
Data collection was conducted on December 23, 2018, using the Scopus database. The central theme in this study consisted of research articles containing PSCs in their titles, abstracts, or keywords. The query string used for this search was: TITLE-ABS-KEY (“perovskite solar cells”) AND DOCTYPE (ar OR re) AND PUBYEAR < 2019. This query string resulted in 7,125 documents, and the oldest publication was from 1999, as Figure 4 shows.
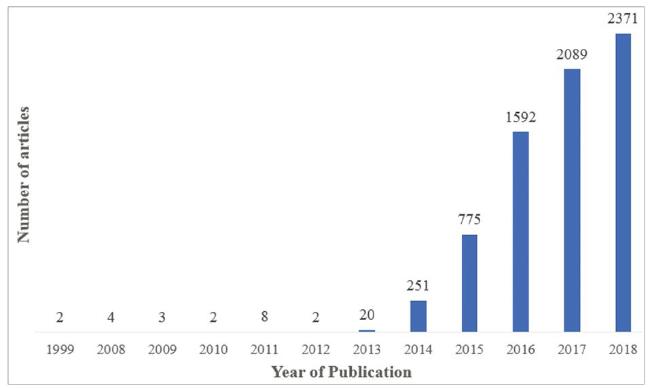
Figure 4. The annual number of research articles on PSCs indexed in Scopus from 1999 to 2018. |
3.2 Data slicing
Regarding PSCs, the total amount of literature in the subperiod and the need to highlight temporal evolution as much as possible were taken into consideration during slicing. The total number of articles published before 2013 were small and sliced as one subperiod, and the articles published between 2014 and 2018 were sliced as a separate subperiod, since the amount of this literature was appropriate for a yearly analysis.
3.3 Thesaurus construction
An example of a thesaurus file for VOSviewer is shown in Figure 5 . These “label” terms like “cm2,” “c cm2,” and “future” are stop-words. We figure there are two different ways to conduct pre-text mining and to generate map files. One is to pre-text mine the entire set of text data at once, and the other is to pre-text mine each subperiod’s text data. In our opinion, the second method is more reasonable, as the minimum occurrences of keywords to be analyzed can be set flexibly and the distribution of keywords in the entire set of text data is quite different from that of each subperiod’s text data. In the PSCs example, pre-text mining is performed for each subperiod’s text data, and the resulting thesaurus file is used and updated each time until a final version is achieved.
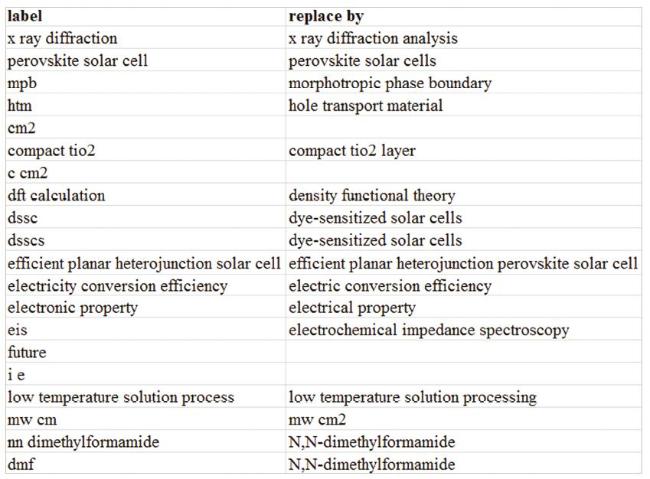
Figure 5. A part of the thesaurus constructed for PSCs in VOSviewer. |
3.4 Text mining and map files generation
With the final version of the thesaurus file, a series of subperiod text data are processed using the natural language processing, information extraction, co-occurrence term analysis, clustering, and visualization techniques offered by VOSviewer, and terms are extracted from titles and abstracts. The corresponding map files are generated and saved for further analysis.
3.5 Map files treatment and analysis
Each cluster in the map file of every subperiod’s text data can be seen as a topic. By analyzing the total link strength of terms in each cluster, we label the cluster with the most dominant and meaningful terms as the topic, and these topics are shown in Figure 6 . As the most dominant terms are not always the ones that best describe a cluster’s general nature, a careful manual review by a researcher on the scientific domain could be useful. The number of topics in each subperiod’s text data is dependent on the minimum occurrences of a term to be analyzed, which we set.
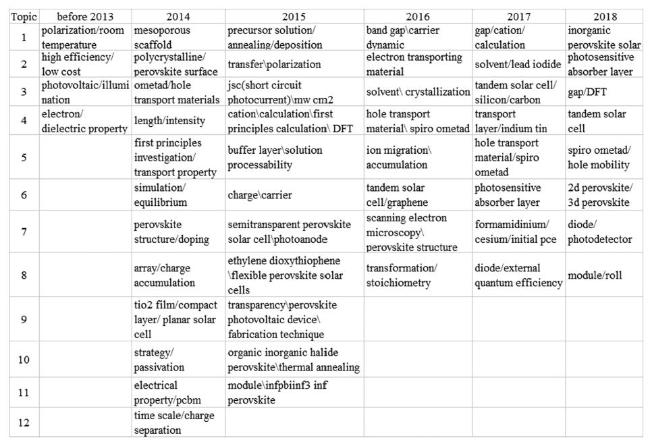
Figure 6. Topic evolution for PSCs. |
The emerging terms in PSCs were detected by the “LOOKUP” function of Excel, where “#N/A” means that the label or the term does not exist in the compared subperiod’s text data. As shown in Figure 7 , “inorganic perovskite solar cell” was one of the emerging terms in 2017. In addition, “halide perovskite” and “gap” were two of the emerging terms in 2016, and “tin oxide” “module” “tandem solar cell” and “photodetector” were four of the emerging terms in 2015.
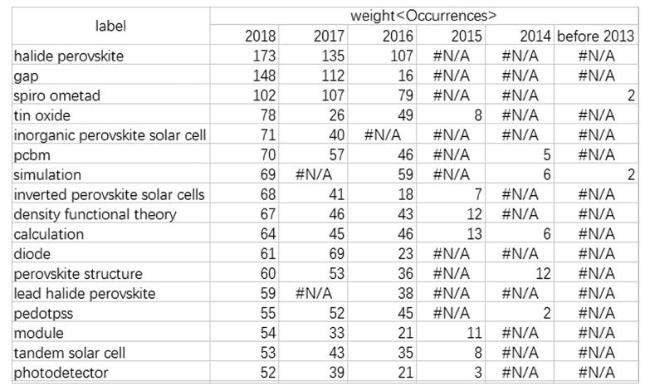
Figure 7. Detecting emerging terms using Excel’s “LOOKUP” function. |
3.6 Visualization
We used Microsoft Office PowerPoint and Excel to visualize the analysis results. The Top 10 emerging terms for PSCs were picked by researchers in descending order of occurrence, and they were visualized by PowerPoint, as shown in Figure 8 .

Figure 8. Examples of emerging PSC Terms from 2014 to 2018. |
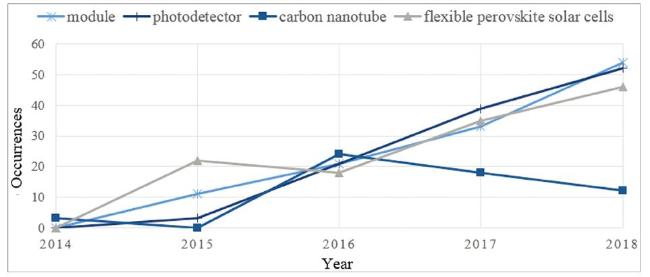
In addition, we also used Excel to visualize variations in term occurrence and to forecast the future trends of terms. As Figure 9 shows, by analyzing the increase or decrease of term occurrence in PSCs research, the “module” “photodetector” and “flexible perovskite solar cells” topics may receive more attention from researchers in the near future, while the “carbon nanotube” topic may receive less attention.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 9. Variation in PSC term occurrence. |
4 Verification and discussion
The emerging terms detected by our method were verified by comparing them to the search results in the Scopus database and by combining “perovskite solar cells” with emerging terms. Generally, few or only a small percentage of articles were published before the year for which our method detected the term in use. Taking the emerging term “flexible perovskite solar cells” in 2015 as an example, there was only one paper published in 2014 (Jung, Williams, & Jen, 2014), but the number of papers published containing “flexible perovskite solar cells” rose to 21 in 2015, indicating that this method is quite effective.
For better performance analyzing emerging terms and topic evolution by this approach, the following ideas should be considered: (1) an appropriate threshold of minimum occurrences of a term to be analyzed should be set, and it should be as small as possible; (2) a detailed thesaurus file should be constructed, and it should be as detailed as possible. It takes time to merge the synonyms and abbreviations of identical terms, and it is quite difficult to clarify the relationships between the upper and lower levels of a concept, even for specific scientists in a particular research domain. Certainly, with the development of natural language processing, semantic processing and text mining techniques, the performance of topic evolution and emerging term analysis will improve.
5 Conclusion
In this paper, through natural language processing, information extraction, thesaurus utilization, co-occurrence term analysis, clustering techniques, and the use of the LOOKUP function, a flexible approach for topic evolution, emerging topic analysis and visualization based on VOSviewer and Microsoft Office has been presented. As an example, the topic evolution and emerging topics of perovskite solar cells research was analyzed. The new attempts and applications of open source bibliometric software in this paper could be a valuable supplement to text mining analysis. Also, they could be quite effective for interdisciplinary researchers, especially those with low or no skills in computer programming. In addition, the proposed approach can be used to analyze large amounts of text data, including both scientific text and non-scientific text (e.g. project files, policy files, and newspaper articles). Finally, this process of analysis can be optionally adjusted by researchers according to their specific needs.
Acknowledgments
We would like to thank Professor Van Eck and Professor Waltman for developing the useful, open source software VOSviewer, and we would also like to thank the anonymous reviewers of this paper for their valuable comments.
Author contributions
Proposing the research problems: Xiang Shen (shenx@mail.las.ac.cn); performing the research: XS; designing the research framework: XS, Li Wang (wangli@mail.las.ac.cn); collecting and analyzing the data: XS; writing and revising the manuscript: XS, LW.