


1 Introduction
Scientific knowledge can be divided into explicit knowledge and tacit knowledge. In the medical context, knowledge is considered explicit due to the strict training standard and education system of medicine, especially modern medicine, which can be recorded and directly used by others (Wyatt & Scott, 2020). However, current explicit medical knowledge is generally expressed and stored in unstructured natural language form, regularly in PDF or HTML files in published digital literature, and it is hard to comprehend and compute by machines. A vast number of knowledge assertions implied in the medical literature have not been effectively managed and utilized. There is an increasing need for computable biomedical knowledge due to the information overload of scientific literature.
Several efforts have been made to fill this gap. The current model of computable medical knowledge includes 1) the knowledge units extracted from unstructured scientific text in the form of subject-predicate-object triples (SPO triples), called semantic predications (Kilicoglu et al., 2020), and 2) computable knowledge objects from structured data, such as disease prediction models, diagnostic rules, and structured clinical guidelines generated from big data (Flynn et al., 2018; Friedman & Flynn, 2019). This article primarily focused on the extraction of SPO triples from unstructured medical literature to reduce information overload. Biomedical knowledge claims are often expressed in an uncertain way as hypotheses, speculations, or even controversial and contradictory opinions rather than explicit facts. SPO triples could be conceivably extracted from those assertions, where knowledge status (i.e., uncertainty), an integral and critical part of scientific knowledge, has been largely overlooked.
Uncertain scientific knowledge refers to the knowledge originating from hypothetical, speculative statements or even conflicting and contradictory assertions. It is critical to understand the incremental and transformative development of scientific knowledge (Chen, Song, & Heo, 2018; Li, Peng, & Du, 2021; Small, 2020). For example, it is common in medical research or clinical practice to encounter medical reversals, with contradictory results in subsequent research. Based on recent analysis (Herrera-perez et al., 2019) from more than 3,000 randomized controlled trials (RCTs) published in three leading medical journals, 396 medical reversals were identified, among which cardiovascular disease was the most common category (20%). Therefore, there are increasing calls for physicians, patients, and the whole health care system to acknowledge and accept the concept of uncertain medical knowledge (Simpkin & Schwartzstein, 2016). These findings inspired us to investigate the uncertain medical knowledge of cardiovascular diseases since there are frequent medical reversals in this area. To narrow the whole dataset, we specifically focused on cardiovascular research publications in China.
2 Related work
2.1 SPO triples: a structured representation for knowledge claims
Computable knowledge must be structured, or machine-readable. A simple representation of computable knowledge is the SPO triple, which consists of a subject argument, an object argument, and the predicate that binds them. For instance, drug knowledge can be expressed as triples (Elkin et al., 2011). Based on the comparison between triples from PubMed articles and the Food and Drug Administration (FDA) drug labeling documents, one can identify novel and unreported medical knowledge in the literature (Malec & Boyce, 2020).
The SemRep tool and SemMedDB knowledge database, which were developed and maintained by the Semantic Knowledge Representation program of the National Library of Medicine (NLM), are typical representatives for SPO triple extraction from biomedical free text. SemRep, the abbreviation for Semantic Representation, is a rule-based natural language processing tool that extracts SPO triples from sentences in biomedical texts. It is based on standardized medical concepts, concept types, and semantic relations between concepts in the Unified Medical Language System (UMLS). The latest 2021 version of UMLS contains approximately 4.5 million concepts, 127 concept types, and 54 semantic relations. SemMedDB, short for Semantic MEDLINE Database, is a repository consisting of SPO triples extracted from the titles and abstracts of all of the PubMed publications (Kilicoglu et al., 2012) by SemRep (Rindflesch & Fiszman, 2003). The SemMedDB also stores SPO triple-related information, including the supporting sentences as well as the original publication (Kilicoglu et al., 2012). NLM regularly releases a new version of SemMedDB with improvement, including modifications of incorrect concepts and relations extracted by the SemRep, which is currently being redesigned to improve its overall performance (Kilicoglu et al., 2020). SemRep and SemMedDB form a fundamental database that realizes the extraction and storage of large-scale knowledge units, supports secondary knowledge discovery, and supports a variety of clinical decision-making and applications to help improve health outcomes. For example, the MELODI Presto system (http://melodipresto.mercies.ac.uk) has recently been developed for web-based SemMedDB SPO triple and metadata queries (Elsworth & Gaunt, 2021).
2.2 Nanopublication: a richer semantic representation for knowledge claims
In recent years, progress in the field of biosemantics has provided solutions for the representation of biomedical knowledge. As Barend Mons and other scientists proposed (Groth, Gibson, & Velterop, 2010; Mons et al., 2011), the basic structure of the nanopublication model includes the following components: a) assertion, the scientific claims represented by SPO triples; b) provenance, referring to the author, institution, time, position, and other necessary information of a triple; and c) publication information, or the metadata of a nanopublication itself, including the creator, date of creation, and version of a nanopublication. The three components are indispensable to ensure the integrity of the information and effectively improve the possibility of reusing scientific research information. Expressed in RDF format, the contents of these components are machine-readable. Surveys in the biomedical domain indicate that there are approximately 1014 such assertions, with an enormous increase every year. After eliminating duplicate findings, 1011 canonical assertions still remain. Further processing yields approximately 106 so-called knowlets, which can be seen as core concepts of assertions related to sets of different findings (Mons, 2019), and they can be used to draw conclusions or for proper health treatments.
Nanopublication has been applied for scientific research. Currently, converting existing relational databases (such as DisGeNet, a gene-disease association knowledge database) to nanopublications (Fabris, Kuhn, & Silvello, 2020) or storing and computing triples at online platforms such as The Open Pharmaceutical Triple Store (Open PHACTS, a pharmaceutical semantic triple discovery platform) (Williams et al., 2012) are two representatives of nanopublication applications. However, the nanopublication model has not been widely utilized in clinical research and practice. To promote the reuse of nanopublications and increase acceptance, scholars have recently proposed a nanocitation format that can cite individual nanopublications and allocate credits to the contributor. Therefore, it is possible to design bibliometric indicators, conduct fine-grained analysis of knowledge units, and combine them with current scientific research (Fabris, Kuhn, & Silvello, 2019).
Barend Mons (2019) also suggested aggregating common assertions that appear in all nanopublications into a cardinal assertion for presenting a basic knowledge unit to reduce redundancy. This process can be considered the formation of a knowlet, which combines all of the directly linked concepts around a central concept. We think that the knowlet, or the knowledge subgraph, can represent an independent knowledge unit in the knowledge graph. Compared with the rapid growth of support text related to a particular assertion, the growth of the knowledge subgraph is relatively slower. For instance, a large amount of text may involve only one piece of knowledge unit. The knowledge subgraph is an independent digital object, and the smallest knowledge unit can be discoverable, accessible, interoperable, and reusable.
2.3 Uncertainty: a fundamental role in representing and communicating claims in scientific literature
Uncertainty is an inherent part of knowledge. It is a rhetorical means, or a communicative technique, to convey the degree of uncertainty associated with a statement or an assertion (Chen & Song, 2017). Understanding the wide variety of types and the degree of uncertainties in science and their roles in the advancement of science itself and in the broader context of everyday life is the first step toward a better understanding of how science works (Chen & Song, 2017). The uncertainty associated with a scientific proposition implies the epistemic status of scientific knowledge, which is easily neglected meta-knowledge. Pluralistic epistemic statuses may indicate the emergence of a new paradigm. The degree of uncertainty may affect the attentions to scientific research because it may imply different levels of achievements.
Kilicoglu, Rosemblat, and Rindflesch (2017) annotated semantic predications with seven factuality values (fact, probable, possible, doubtful, counterfact, uncommitted, and conditional), and extended a rule-based, compositional approach that uses lexical and syntactic information to predict factuality levels. Uncertainty cues are a particularly relevant traits in understanding how scientists characterize the tentative and context-dependent nature of scientific claims (Chen & Song, 2017). Szarvas et al. (2012) identified uncertainty cues in each of these categories. For instance, “probably,” “likely,” and “possible” are uncertainty cues in the adjective and adverb category. Examples of auxiliaries as uncertain cues include “may,” “might,” and “could.” Speculative verbs include “suggest,” “seem,” and “appear.” Nouns include “speculation,” “proposal,” and “rumor.” In scientific writing, uncertainty cues come from adjectives, adverbs, auxiliaries, verbs, conjunctions, and nouns in general.
In this article, by combining informetric methods with computational linguistics, we aimed to extract knowledge units from scientific statements in cardiovascular research publications in China. In our previous work, we proposed a framework for medical knowmetrics using SPO triples as the knowledge units and uncertainty as the knowledge context. However, it is not well resolved how to measure the uncertainty level for a given SPO triple or concept pairs. Therefore, inspired by Chen's work (2020), we introduced the concept of information entropy (IE) to measure the level of uncertainty for a given knowledge unit.
3 Methods
A brief research framework can be seen in Figure 1 . We first constructed a dataset of structured semantic triples extracted from the cardiovascular literature. Then, we proposed an approach to identify and measure uncertainty by semantically equivalent uncertainty cue words and information entropy (IE).
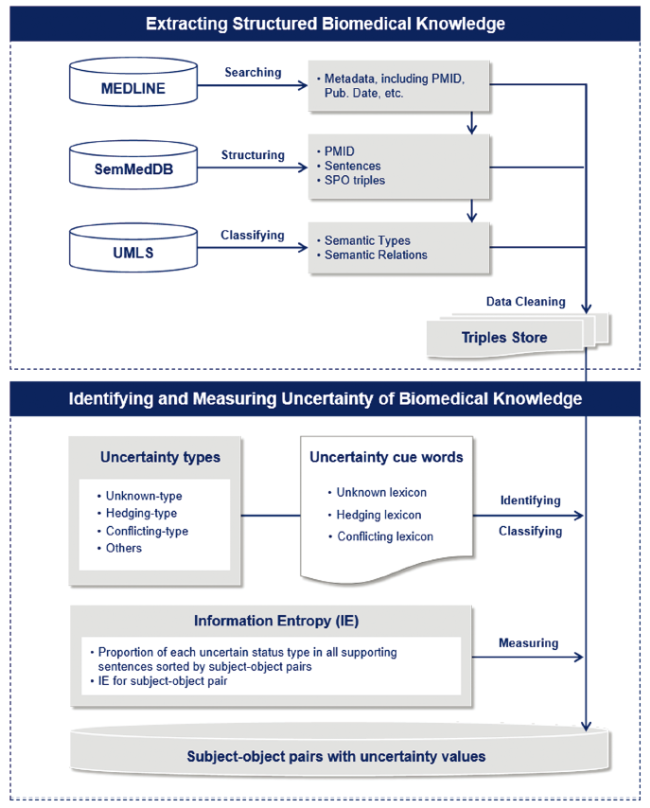
Figure 1. Research framework for extracting and measuring computable biomedical knowledge. |
3.1 Extracting structured biomedical knowledge
For constructing the dataset of structured biomedical knowledge from scientific literature, the process consists of collecting related publications, extracting structured semantic predications (SPO triples) from those publications, and classifying semantic types and relations for the extracted SPO triples.
3.1.1 Collecting related publications
We retrieved cardiovascular research publications during the period between 2001 and 2020 in China from PubMed. Cardiovascular disease-related Medical Subject Headings (MeSH) terms were combined to archive cardiovascular research publications. We further narrowed our dataset by focusing on research conducted in China or targeting the Chinese population. Cardiovascular research publications with 1) “China” or “Chinese” in the title or abstract and 2) Chinese language were included in our study. The acquisition of the metadata of the included publications was performed on October 23, 2020.
3.1.2 Extracting SPO triples
To execute literature-derived structured biomedical knowledge, we retrieved SPO triples and their corresponding sentences from SemMedDB by acquired PMIDs. SemMedDB provides SPO triples extracted from the titles and abstracts
of MEDLINE publications with essential metadata. We constructed our dataset by consolidating the tables in the SemMedDB database, including information about each concept, SPO triple, sentence, and publication. SemMedDB version 43R was retrieved on February 8, 2021 and used in our study.
of MEDLINE publications with essential metadata. We constructed our dataset by consolidating the tables in the SemMedDB database, including information about each concept, SPO triple, sentence, and publication. SemMedDB version 43R was retrieved on February 8, 2021 and used in our study.
3.1.3 Classifying semantic types and relations
The UMLS Semantic Network, one of the UMLS knowledge sources, consists of (1) Semantic Types, which provide a consistent categorization of all concepts represented in the UMLS Metathesaurus, and (2) Semantic Relations, which exist between Semantic Types. The UMLS Semantic Network reduces the complexity of the Metathesaurus by grouping concepts according to the semantic types that have been assigned to them (for details see the UMLS Semantic Network Browser: https://uts.nlm.nih.gov/uts/umls/semantic-network/root). In our work, semantic relations were grouped into eight major categories, i.e., “isa,” “associated with,” “physically related to,” “spatially related to,” “temporally related to,” “functionally related to,” “conceptually related to,” and unclassified “others,” which contained notions such as “higher than” or “converts to.” Concepts were divided into 15 semantic groups, i.e., “Objects,” “Living Beings,” “Anatomy,” “Genes & Molecular Sequences,” “Chemicals & Drugs,” “Devices,” “Geographic Areas,” “Organizations,” “Concepts & Ideas,” “Physiology,” “Phenomena,” “Disorders,” “Activities & Behaviors,” “Procedures,” and “Occupations”. We constructed triples store including the following data fields:
PREDICATION_ID: Auto-generated primary key for each unique predication
SUBJECT_NAME: The preferred name of the subject of the predication
SUBJECT_SEMTYPE: The semantic type of the subject of the predication
SUBJECT_SEMGROUP: The semantic group of the subject of the predication
PREDICATE: The string representation of the predicate (semantic relationship) of the predication
PREDICATE_SEMTYPE: The category of predicate (semantic relationship)
OBJECT_NAME: The preferred name of the object of the predication
OBJECT_SEMTYPE: The semantic type of the object of the predication
OBJECT_SEMGROUP: The semantic group of the object of the predication
SENTENCE_ID: Foreign key to the SENTENCE table
SENTENCE: The actual string or text of the sentence
TYPE: 'ti' for the title of the publication, 'ab' for the abstract
PMID: The PubMed identifier of the citation to which the predication belongs
YEAR: Publication year
We analyzed the difference between the total and unique triples. The number of total triples was summarized by the Predication ID provided by SemMedDB. Unique triples were defined as SPO triples with an identical subject, object, and predicate, among which the first occurrence time was labeled as the publication date. We utilized Python programs for data processing and statistical analysis, including identifying uncertain cue words within all of the sentences in triple store, and computing the value of IE, which will be discussed in the next part of the methods.
3.2 Identifying and measuring uncertainty of biomedical knowledge
3.2.1 Uncertainty types and uncertainty cue words
Chen and Song (2017) demonstrated two sources of uncertainty, hedging and contradictions, and they proposed a framework of uncertainty with three major types, namely, epistemic uncertainty (E), hedging (H), and transitional (T) (Chen, 2020). We briefly proposed a model of uncertainty with three major types, namely, unknown (U), hedging (H), and conflicting (C), and selected corresponding lexicons as uncertainty cue words list. Uncertain biomedical knowledge was defined as triples extracted from sentences with uncertainty cue words, and it was divided into different types. Supporting sentences of semantic triples were filtered with the hedging lexicon proposed by Bornmann (Bornmann, Wray, & Haunschild, 2020), and Dakota's measuring disagreement in science (Murray et al., 2019) was applied for unknown and conflicting lexicons. The uncertain cue word list consisted of the unknown, hedging, and conflicting lexicon (Table 1 ).
Table 1. Frequencies of the uncertain cue words. |
| Cue words | Frequency in all SemMedDB sentences | Frequency in our Triples Store sentences | ||
|---|---|---|---|---|
| Unknown lexicon | ||||
| uncertain* | 227,014 | (10.57‱) | 191 | (12.87‱) |
| unknown | 525,536 | (24.48‱) | 499 | (33.62‱) |
| Hedging lexicon | ||||
| maybe | 10,286 | (0.48‱) | 142 | (9.57‱) |
| may | 5,946,955 | (276.96‱) | 10,050 | (677.19‱) |
| might | 949,536 | (44.22‱) | 2,639 | (177.82‱) |
| possible | 1,751,994 | (81.59‱) | 1,611 | (108.55‱) |
| potential | 2,879,336 | (134.10‱) | 2,675 | (180.25‱) |
| seems | 333,677 | (15.54‱) | 154 | (10.38‱) |
| perhaps | 84,058 | (3.91‱) | 32 | (2.16‱) |
| likely | 1,052,986 | (49.04‱) | 1,248 | (84.09‱) |
| sometimes | 119,942 | (5.59‱) | 26 | (1.75‱) |
| Conflicting lexicon | ||||
| conflict* | 175,516 | (8.17‱) | 59 | (3.98‱) |
| contradict* | 46,639 | (2.17‱) | 10 | (0.67‱) |
| controvers* | 208,264 | (9.70‱) | 308 | (20.75‱) |
| debat* | 122,332 | (5.70‱) | 54 | (3.64‱) |
| no consensus | 17,907 | (0.83‱) | 9 | (0.61‱) |
| questionable* | 21,159 | (0.99‱) | 5 | (0.34‱) |
| refut* | 9,710 | (0.45‱) | 9 | (0.61‱) |
“*” stands for all of the possible derivations of the word. |
3.3.2 Information entropy
For measuring uncertainty of biomedical knowledge, we introduced information entropy (IE), which reflected the features and distribution of epistemic status (uncertainty types) in the biomedical knowledge. Given a set of sentences from which the concept, concept co-occurrence pairs (SO pairs), as well as “concept-relation-concept” (SPO triples) were extracted, the uncertainty value of a given SO pair or concept, H(x), was defined as the IE, which gave different weights to each uncertainty type (t) based on the probability p(t). In SemMedDB, an SO pair or concept can be linked to n sentences, n ≥ 1. The p(t) was estimated based on the proportion of uncertainty status type in the related supporting sentences. The formula of IE is as follows:
$H(x) = -\sum_{t \in x} p(t). log(p(t))$
4 Results
4.1 Overview of structured biomedical knowledge in cardiovascular research in China
A total of 17,594 English articles and 17,196 Chinese articles published between 2001 and 2020 satisfied our specification. After excluding Chinese articles without English abstracts, articles with multiple PMIDs, and entirely equivalent SPO triples extracted from the same sentence, we obtained 29,800 articles, 148,409 unique sentences, and 259,067 predications. Among them, a total of 100,103 unique triples were related to 17,829 concepts, which were grouped into 117 semantic types and then 15 semantic groups; 61 semantic relationships were grouped into 8 categories, and we constructed the dataset with relevant information. For identifying overall evolution of cardiovascular research in China, Figure 2 presents the basic statistics of the articles and the triples in our dataset. Over a 20-year period, extraordinary progress of cardiovascular research in China was observed. The number of total SPO triples parsed from all articles has significantly enlarged year over year, reaching 20,660 by the end of 2019, which indicates an increase by 6.1 times.It was almost consistent with five-fold growth of the number of publications.In contrast, the number of novel triples (the newly occurring triples) increased by 2.9 times since 2001 with modest growth (Figure 2 A).
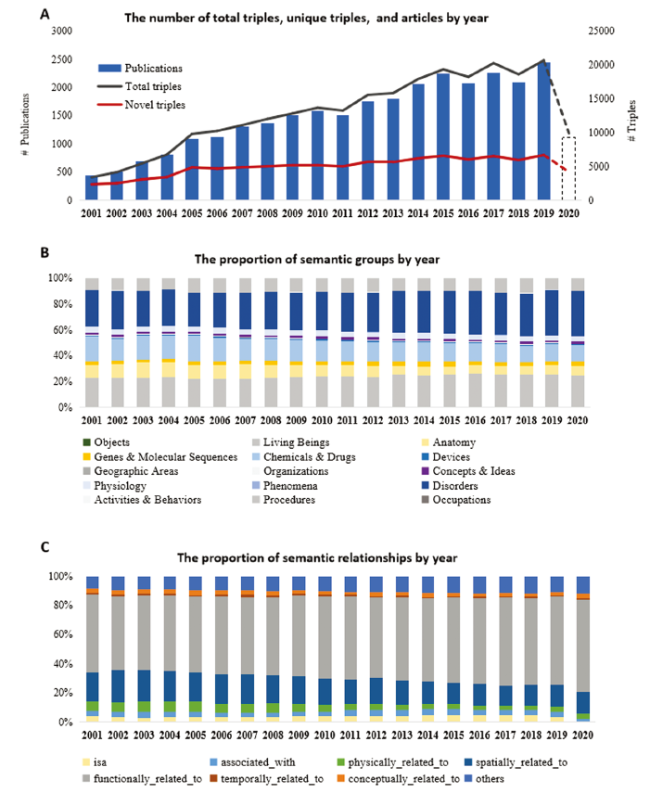
Figure 2. The evolution of structured biomedical knowledge in cardiovascular research in China. |
For discovering the evolution of topics in structured biomedical knowledge over time, we examined the concepts and relations in SPO triples. A total of 17,829 semantic concepts and 117 semantic relationships were clustered into 15 semantic groups and eight categories, respectively. As shown in Figure 2B , “Disorder” was the leading area growing over time (top, dark blue). Concepts within this semantic group included “Hypertensive disease,” “Cerebrovascular accident,” “Coronary arteriosclerosis,” “Coronary heart disease,” and “Atrial Fibrillation.” The proportion of “Chemicals & Drugs,” such as “Serum,” “Aspirin,” and “Glucose,” showed a relative decline, although their number increased gradually. Among the eight semantic relation categories, “functionally_related_to” (such as “PROCESS_OF,” “CAUSES,” and “AFFECTS”) accounted for the largest proportion, with up to 60% with significant growth. In contrast, the proportion of “spatially_related_to” decreased from 20% in 2001 to 15% in 2019. Other groups were relatively small and remained stable over the years (Figure 2C ).
To describe the core dataset, we provide SPO triples extracted from cardiovascular literature and relevant information in Table 2 . We found the following: (1) examples of #1, #4, #5, and #6 were typical representatives of scientific assertions reconstructing biological knowledge in the literature; (2) some triples were more likely to be general concepts or facts rather than scientific claims, i.e., “Stem cells_Part_of _Marrow” standing for “MSCs (mesenchymal stem cells)” in #3; (3) multiple triples extracted from a given sentence could express richer semantic information, in spite of missing some semantics in #2; and (4) different predicates in the triples of same subjects and same objects tended to present similar or progressive viewpoints, such as #4 and #5.
Table 2. Examples of SPO triples extracted from scientific statements. |
| # | PMID | Year | Sentence | Subject | Predicate | Object |
|---|---|---|---|---|---|---|
| 1 | 11748351 | 2001 | 95232561. The high level of low-density lipoprotein (LDL) is a risk factor for cardiovascular disease. | Low-Density Lipoproteins | PREDISPOSES | Cardiovascular Diseases |
| (Chem. & Drugs) | (others) | (Disorders) | ||||
| 2 | 16541193 | 2006 | 62140. Our finding suggests that the CYP2C9*3 gene variant significantly alters the plasma concentration and acute DBP response at the 6-h point following irbesartan treatment in Chinese hypertensive patients | Hypertensive | PROCESS_OF | Patients |
| (Disorders) | (functionally_related_to) | Living Beings | ||||
| Therapeutic procedure | USES | irbesartan | ||||
| Procedures | (functionally_related_to) | (Chem. & Drugs) | ||||
| irbesartan | TREATS | Patients | ||||
| (Chem. & Drugs) | (functionally_related_to) | Living Beings | ||||
| irbesartan | TREATS | Hypertensive | ||||
| (Chem. & Drugs) | (functionally_related_to) | (Disorders) | ||||
| 3 | 27733220 | 2016 | 7853995. Subgroup analysis for each outcome measure was performed for the observing time point after the transplantation of MSCs. | Stem cells | PART_OF | Marrow |
| Anatomy | physically_related_to | Anatomy | ||||
| 4 | 32421381 | 2020 | 345332630. Our data seem to suggest that COVID-19 is probably an additional risk factor for DVT in hospitalized patients. | COVID-19 | PREDISPOSES | Deep Vein Thrombosis |
| (Disorders) | others | Physiology | ||||
| 5 | 32493073 | 2020 | 345298871. COVID-19 presented with deep vein thrombosis: an unusual presentation. | COVID-19 | COEXISTS_WITH | Deep Vein Thrombosis |
| (Disorders) | others | Physiology | ||||
| 6 | 32351121 | 2020 | 345367243. In this brief review, we will elaborate on the role of RAS and ACE2 in pathogenesis of COVID-19. | Angiotensin converting enzyme 2 | CAUSES | COVID-19 |
| (Chem. & Drugs) | (functionally_related_to) | (Disorders) |
Terms in parentheses stand for semantic groups. "Chem. & Drugs" is short for "Chemicals & Drugs". |
4.2 Evaluation of uncertain biomedical knowledge in cardiovascular research
Considering the topic mainly determined by concepts, we identified and measured uncertain biological knowledge at a subject-object pair (SO pair) level in the following study. Therefore, IE was applied to measure the uncertainty of each SO pair. The uncertain knowledge with the highest IE was related to the SO pairs in Table 3 , in which the number of supporting sentences is no less than 4. The following information indicated disease-centric uncertain knowledge since our dataset involved cardiovascular research publications. We found that the uncertainty in “genetic function,” “fibrinogen,” and “epinephrine,” related to cardiovascular research in China remained at a high level in general. All of these emerged after 2000, and the number of their supporting sentences was not more than 15. The epistemic statuses of scientific knowledge in these topics are pluralistical, implying its active role in cardiovascular research.
Table 3. Top 10 SO pairs with the highest IE value. |
| # | Subject_Object Pair | Start year | End year | # Sentence | IE | ||
|---|---|---|---|---|---|---|---|
| 1 | Polymorphism, Genetic (Genetic Function / Physiology) | _ | Coronary Arteriosclerosis (Disease or Syndrome / Disorders) | 2010 | 2019 | 9 | 1.837 |
| 2 | Fibrinogen (AAPP / Chem. & Drugs) | _ | Ischemic stroke (Disease or Syndrome / Disorders) | 2006 | 2015 | 5 | 1.522 |
| 3 | Vascular Diseases (Disease or Syndrome / Disorders) | _ | Human (Human / Living Beings) | 2003 | 2013 | 4 | 1.500 |
| 4 | Epinephrine (Hormone / Chem. & Drugs) | _ | Cardiopulmonary Arrest (Pathologic Function / Disorders) | 2007 | 2007 | 4 | 1.500 |
| 5 | Ischemic stroke (Disease or Syndrome / Disorders) | _ | Variation (Genetics) (NPOP / Phenomena) | 2008 | 2016 | 4 | 1.500 |
| 6 | Gene Expression (Genetic Function / Physiology) | _ | Population Group (Human / Living Beings) | 2016 | 2018 | 4 | 1.500 |
| 7 | Reactive Oxygen Species (BACS / Chem. & Drugs) | _ | Apoptosis (Cell Function / Physiology) | 2017 | 2020 | 4 | 1.500 |
| 8 | Basal Ganglia (BPOC / Anatomy) | _ | Hematoma (Pathologic Function / Disorders) | 2012 | 2017 | 4 | 1.500 |
| 9 | HMG-CoA Reductase Inhibitors (Organic Chemical /Chem. & Drugs) | _ | Acute coronary Syndrome (Disease or Syndrome / Disorders) | 2009 | 2019 | 6 | 1.459 |
| 10 | Hyperuricemia (Disease or Syndrome / Disorders) | _ | Hypertensive Disease (Disease or Syndrome / Disorders) | 2012 | 2019 | 14 | 1.430 |
Terms in parentheses stand for semantic types / semantic groups. “Chem. & Drugs” is short for “Chemicals & Drugs;” “AAPP” is short for “Amino Acid, Peptide, or Protein;” “BACS” is short for “Biologically Active Substance;” “BPOC” is short for “Body Part, Organ, or Organ Component;” and “NPOP” is short for “Natural Phenomenon or Process.” |
We examined the supporting sentences of the SO pairs with high IE, and details are presented in Table 4 . Overall, a given SPO triple extracted from biomedical literature was only a frame part of propositions. As for “Polymorphism, Genetic_ Coronary Arteriosclerosis,” the scientific statements concerned different genes, i.e., “receptor for advanced glycation end product (RAGE),” “myocyte enhancer factor 2A (MEF2A),” “renin-angiotensin system (RAS),” “fibroblast growth factor receptor 4 (FGFR-4),” “myeloperoxidase (MPO),” “nitric oxide synthase (NOS3),” and “interleukin-8 (IL-8)”. In “Hydroxymethylglutaryl-CoA Reductase Inhibitors_ Acute coronary syndrome,” the SO pair was not representative of specific conditions, such as “intensive lipid lowering,” “advanced age,” “percutaneous coronary intervention (PCI),” “early use,” “combined treatment,” and “use of prehospital.” In “Hyperuricemia_Hypertensive disease,” “PREDISPOSES” reflects that “hyperuricemia is a risk factor for hypertension” appropriately. However, there was hardly any regularity of epistemic status evolution in terms of uncertainty type. When considering various research differentiation in a given topic, the IE in this article did not assign factuality values to the scientific assertion, but rather indicated epistemic status pluralism of the SO pair, which implied its activity in the area.
Table 4. Sample sentences from SO pairs with high IE. |
| Polymorphism, Genetic_Coronary Arteriosclerosis | ||||
|---|---|---|---|---|
| # | PMID | Year | Predicate | Sentence |
| 1.1 | 20668462 | 2010 | AFFECTS | To clarify whether polymorphisms of the RAGE gene were related to CAD, we performed a case-control study in Chinese Han patients. |
| 1.2 | 22363637 | 2012 | AFFECTS | Our findings failed to demonstrate a correlation between (CAG)(n) polymorphism with CAD; however, we concluded that the rare 21bp deletion might have a more compelling effect on CAD than the common (CAG)(n) polymorphism, and MEF2A genetic variant might be a rare but specific cause of CAD/MI. |
| 1.3 | 22345093 | 2012 | NEG_AFFECTS | The three other polymorphisms of the RAS do not seem to influence the development of CAD in type 2 diabetes. |
| 1.4 | 23583798 | 2013 | AFFECTS | However, given the limited number of studies and the potential biases, the influence of this (myeloperoxidase (MPO) G463A) polymorphism on CAD risk needs further investigation. |
| 1.5 | 24155913 | 2013 | CAUSES | Our findings provided strong evidence for the potentially contributory roles of RAGE multiple genetic polymorphisms, especially in the context of locus-to-locus interaction, in the pathogenesis of CAD among northeastern Han Chinese. |
| 1.6 | 24239227 | 2014 | AFFECTS | Some polymorphisms in the fibroblast growth factor receptor 4 gene (FGFR-4) have been correlated with coronary artery disease, however, the role of polymorphisms in the FGFR-4 gene in ischemic stroke remain unknown. |
| 1.7 | 27323132 | 2016 | AFFECTS | There is growing evidence that polymorphisms in NOS3 influence the progression of CAD; however, there is also a controversy regarding the association of polymorphisms in the gene encoding NOS3 and CAD. |
| 1.8 | 30826813 | 2019 | AFFECTS | Studies have reported that inflammatory cytokine interleukin-8 (IL-8) gene -251 A/T (rs4073) polymorphism is correlated with CAD susceptibility, but the result remains controversial. |
| 1.9 | 31770200 | 2019 | AFFECTS | Thus, a meta-analysis was conducted to reassess the effects of this (interleukin-8 gene) polymorphism on CAD risks. |
| Hydroxymethylglutaryl-CoA Reductase Inhibitors_Acute Coronary Syndrome | ||||
| # | PMID | Year | Predicate | Sentence |
| 9.1 | 19781407 | 2009 | TREATS | Rationale and design of China intensive lipid lowering with statins in acute coronary syndrome: the CHILLAS study. |
| 9.2 | 23990595 | 2014 | TREATS | The effect of statins in patients with acute coronary syndrome (ACS) at advanced age with lower low-density lipoprotein cholesterol (LDL-C) levels undergoing percutaneous coronary intervention (PCI) remains unknown. |
| 9.3 | 24216317 | 2014 | TREATS | Results of the current study merit further investigation of the early use of statins in patients with NSTE-ACS to delineate patient subgroups who may benefit from this therapy. |
| 9.4 | 25879728 | 2015 | TREATS | Combination therapy analysis of ezetimibe and statins in Chinese patients with acute coronary syndrome and type 2 diabetes. |
| 9.5 | 25879728 | 2015 | TREATS | The effects and safety of the combined treatment of ezetimibe (EZ) and statins in Chinese patients with acute coronary syndrome (ACS) and type 2 diabetes mellitus (T2DM) remain unknown. |
| 9.6 | 30986750 | 2019 | TREATS | This study aimed to assess use of prehospital statins and LDL-C levels at admission in ACS patients with history of MI or revascularization. |
| Hyperuricemia_Hypertensive Disease | ||||
| # | PMID | Year | Predicate | Sentence |
| 10.1 | 22377586 | 2012 | PREDISPOSES | Multivariate logistic regression showed that age, gender, overweight/obesity, dyslipidemia and alcohol use were risk factors for prehypertension, and age, overweight/obesity, dyslipidemia, alcohol use, family history of hypertension and hyperuricemia were risk factors for hypertension. |
| 10.2 | 24905962 | 2014 | PREDISPOSES | In addition, after adjusting for potential confounders, hyperuricemia was associated with increased risk of hypertension in both males and females, with odds ratios (95% CI) of 1.680 (1.110-2.543) and 1.065 (1.012-1.118), respectively. |
| 10.3 | 25437867 | 2014 | PREDISPOSES | Hyperuricemia may modestly increase the risk of hypertension incidence, consistent with a dose-response relationship. |
| 10.4 | 25863573 | 2015 | PREDISPOSES | Besides traditional risk factors, multiple logistic regression analysis indicated that obesity, diabetes, dyslipidemia, and hyperuricemia were becoming risk factors for hypertension in this rural area. The status of hypertension is grim currently in rural Northeast China. |
| 10.5 | 25919438 | 2015 | PREDISPOSES | Hyperuricemia is an independent risk factor for hypertension. |
| 10.6 | 27129957 | 2016 | PREDISPOSES | A Kaplan-Meier survival analysis showed that hyperuricemia predicted higher incidences of hypertension in a dose-dependent manner: hypertension onset significantly differed across SUA quartiles. |
| 10.7 | 28176036 | 2017 | PREDISPOSES | Whether hyperuricemia is an independent risk factor for hypertension in adults is still under debate. |
| 10.8 | 28808071 | 2017 | PREDISPOSES | Temporal Relationship Between Hyperuricemia and Insulin Resistance and Its Impact on Future Risk of Hypertension. |
| 10.9 | 28808071 | 2017 | PREDISPOSES | Although hyperuricemia and insulin resistance significantly correlated, their temporal sequence and how the sequence influence on future risk of hypertension are largely unknown. |
| 10.10 | 29390287 | 2017 | PREDISPOSES | HUA was also a risk factor for hypertension in this age group (odds ratio 1.425, 95% confidence interval, 1.217-1.668, P <.001). |
| 10.11 | 28445311 | 2017 | PREDISPOSES | Besides, after adjustment for confounding variables, hyperuricemia was associated with an increased risk of hypertension in both male and female patients, with odds ratios of 2.152 (95% confidence interval 1.324-3.498) and 2.133 (95% confidence interval 1.409-3.229), respectively. |
| 10.12 | 28445311 | 2017 | PREDISPOSES | Hyperuricemia was significantly associated with the risk of hypertension. |
| 10.13 | 30817449 | 2019 | PREDISPOSES | This study aimed to develop a cumulative score composed of seven risk factors: age, resting heart rate, overweight or obesity, dyslipidemia, hyperuricemia, impaired glucose regulation, and impaired estimated glomerular filtration rate (eGFR), to evaluate the risk of new-onset hypertension. |
| 10.14 | 31908434 | 2019 | AFFECTS | Hyperuricemia is an important potential pathogenic factor for hypertension, cardiovascular disease and stroke. |
4.3 Visual presentation of the SO pairs in cardiovascular literature
For a visual and comprehensive overview, we prepared a map of SO pairs and their interrelation based on co-occurrence within publications using a network analysis tool, VOSviewer (Figure 3 ). The nodes weighted by occurrence were top 1000 SO pairs with greatest total link strength, following exclusion of “patients” and “population group” among objects. In Figure 3 A, the clusters are depicted in different colors, representing similarity of research, clinical (center, red/pink/dark green), population (left, green/blue), and basic research (right, orange/yellow). Large nodes in seven clusters suggested the following major research directions: (1) “implantation procedure_stents” and “percutaneous coronary intervention_acute myocardial infarction” in clinical research of surgery (red); (2) “therapeutic procedure_pharmaceutical preparations” in the study of drug intervention (pink); (3) “mucocutaneous lymph node syndrome_child” and “congenital heart disease_child” in clinical research on childhood-onset diseases (dark green); (4) “plasma_glucose” and “hypertensive diseases_adult” in population research on cardiovascular risk factors (green); (5) “patients_single nucleotide polymorphism” in the genetic polymorphism study (blue); (6) “myocytes, cardiac_apoptosis” in basic research of heart diseases (orange); and (7) “cerebral ischemia_rattus norvegicus” in basic research of cerebrovascular diseases (yellow).
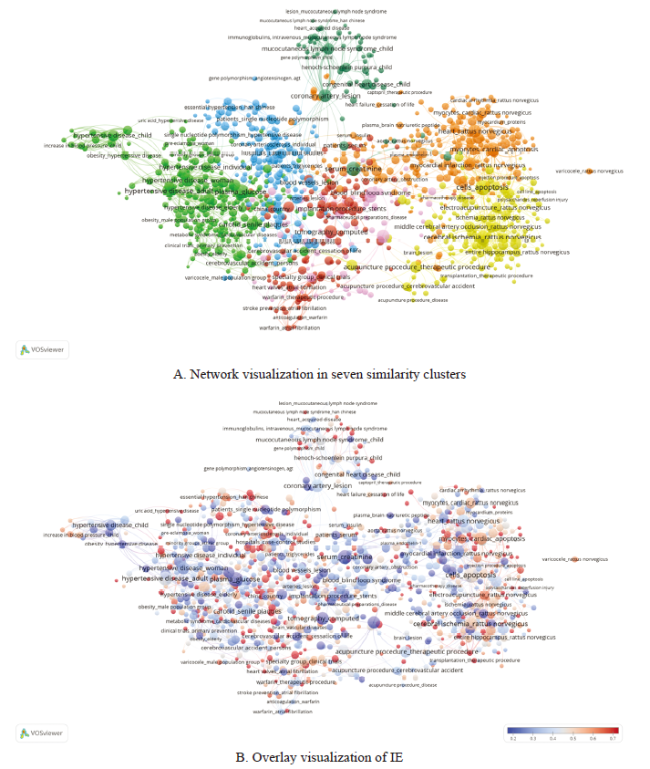
Figure 3. Network visualization of co-occurrence of SO pairs. |
Biological knowledge with uncertainty value is presented in Figure 3B . Cool-warm colors representing IE were overlayed on each node. The configuration of the parameters for this network is shown in the bottom right corner. Redder nodes reflect more uncertainty types, implying hotter research topics. In clinical research, cerebrovascular accident, atrial fibrillation, and congenital heart diseases were active research points. In population research, co-existing risk factors related to metabolic syndrome, such as hypertensive disease, diabetes, obesity, and hyperuricemia, were prominent. Research on genetic polymorphism was considered an emerging field in the past decade, presenting the highest uncertainty in seven clusters. Basic research was another active area with high IE; it included cardiac myocytes apoptosis in reperfusion injury and electroacupuncture against cerebral ischemia.
5 Discussion and conclusion
5.1 Identification of uncertain biomedical knowledge from scientific statements in cardiovascular literature
We introduced the concept of knowledge unit, defined as one identical SPO triple derived from multiple source sentences. The SPO triple is a structured representation for knowledge assertions, and is less abundant than the unstructured text. We observed a less steep development of novel SPO triples compared with scientific publications and total SPO triples, which suggests that new knowledge or research fields are not growing as fast as the number of scientific publications. This outcome is in accordance with the results of “overall growth of science” within all publications in Web of Science. Although the number of publications grows exponentially, the conceptual territory of science, measured by the newly appeared phases in the title, expands linearly (Fortunato et al., 2018).
We also added contextual uncertainty to SPO triples since they were often extracted from hypothetical, speculative, or even conflicting and contradictory assertions. Here, we considered a transparent methodology that used a set of cue words to measure the level of contextual uncertainty rather than a machine-learning approach. It is also consistent with a recent related work (Kilicoglu, Rosemblat, & Rindflesch, 2017), which investigated the feasibility of assessing the factuality level of SemRep predications. These authors annotated semantic predications extracted from 500 PubMed abstracts with seven factuality values (fact, probable, possible, doubtful, counterfact, uncommitted, and conditional). They proposed a rule-based, compositional approach that used lexical and syntactic information. This method was compared with a supervised machine-learning method that used a rich feature set based on the annotated corpus. The results indicated that the compositional approach was more effective than machine learning in predicting factuality levels. This transparent approach allows us to easily scale our analysis to millions of scientific articles while also being transparent and reproducible, and ensuring interpretability of the results.
Uncertainty cue words were applied to identify and measure the uncertainties in this study. The uncertainties of the context can be identified independent of the scientific assertions; however, it is more valuable to combine the explicit information from rhetorical cue words and tacit knowledge mined from SPO triples. In our current research, terms such as “action potential” and “as soon as possible” do not indicate epistemic status of knowledge. We will optimize the method and improve the specificity of uncertainty cue words. We may assign probabilities to cue words (i.e., the probability for “likely” is less than “very likely”). Future research could refine the method for measuring uncertainty by creating metrics for the uncertain degree of cue words.
5.2 Distribution characteristics of uncertainty types in different types of scientific statements
Scientific knowledge is a complex adaptive system of facts, beliefs, hypotheses, speculations, and opinions. Uncertainty cue words are used as a rhetorical device or a communicative technique to convey the degree of uncertainty associated with a statement or an assertion (Chen & Song, 2017).
Generally, the structured abstract of a given biomedical article includes background, objectives, methods, results, and conclusions, reflecting the process and elements of knowledge production. The information in background is usually the premise and basics of the scientific issues to be investigated; objectives tend to be unconfirmed hypotheses; results convey evidence to support the objectives; and conclusions are the knowledge claims, arguments, and assertions concluded through the investigation. We determined different parts of the scientific statements by machine identification combined with manual interpretation.
We analyzed the textual distribution in the abstract of three uncertain knowledge types. According to the typical structure of an abstract and the process of knowledge generation, we annotated 7,530 sentences randomly with four types: background, objectives, results, and conclusions. The frequency of uncertainty cue words in different parts of scientific statements (Figure 4 ) presented the different distribution of hedging and conflicting knowledge. Authors tended to use hedging lexicons in conclusive and purposeful sentences, whereas conflicting lexicons applied in background would act as premises of the investigated work.
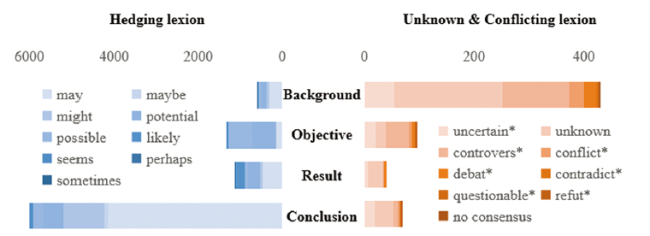
Figure 4. Distribution of Unknown/Hedging/Conflicting cue words in different parts of scientific statements. |
Examples of uncertain sentences and triples from different parts of scientific statements are listed in Table 5 . Based on the results we observed, authors put forward existing knowledge in the background, presumption intention in objectives, evidence supporting the views of paper in results, and scientific claims and presupposition in conclusions. This suggests that uncertain knowledge, especially conflicting knowledge, is usually the premise and the starting point of scientific research, which can be considered as cognitive uncertainty. Moreover, authors generally describe objects and conclusions with hedging lexicons, probably due to cautious and modest attitudes toward presupposition and scientific claims.
Table 5. Examples of uncertain sentences and triples from different parts of scientific statements. |
| Statement Location | Supporting Sentences | SPO Triples |
|---|---|---|
| Premise (Background) | Liver X receptors (LXRs) play a central role in atherosclerosis; however, LXR activity of organic pollutants and associated potential risk of atherosclerosis have not yet been characterized. | liver X receptor _AFFECTS_ Atherosclerosis |
| Lipoprotein-associated phospholipase A2 (Lp-PLA2) is considered to be a risk factor for acute coronary syndrome (ACS), but this remains controversial. | Phospholipase A2 _PREDISPOSES_ Acute coronary syndrome | |
| Hypothesis (Objective) | We therefore performed a case-control study investigating the possible relation between ACE gene polymorphisms and MVPS in Taiwan Chinese. | Mitral Valve Prolapse _ASSOCIATED_WITH_ gene polymorphism |
| Given the uncertainty regarding the relationship of C-reactive protein (CRP) and homocysteine (Hcy) to atherosclerotic burden, our aim was to determine whether CRP and Hcy are related to the presence of subclinical coronary plaque and stenosis. | Stenosis _ASSOCIATED_WITH_ C-reactive protein Stenosis _ASSOCIATED_WITH_ homocysteine | |
| Evidence (Results) | Ischemic heart disease was identified as the possible etiology of HF in a greater proportion of non-Chinese patients (47.7% vs. 35.3%; p < 0.001) whereas hypertension (26.1% vs. 16.1%; p < 0.001) and valvular heart disease (11.6% vs. 7.2%; p < 0.001) were relatively more common in Chinese patients. | Myocardial Ischemia _CAUSES_ Heart failure |
| Genetic polymorphisms of four genes, methylenetetrahydrofolate reductase (MTHFR) and apolipoprotein E (ApoE) have been demonstrated to associate with the increased risk for both MDD and stroke, while the association between identified polymorphisms in angiotensin-converting enzyme (ACE) and serum paraoxonase (PON1) with depression is still under debate, for the existing studies are insufficient in sample size. | Peptidyl-Dipeptidase A _PREDISPOSES_ Cerebrovascular accident Peptidyl-Dipeptidase A _PREDISPOSES_ Major Depressive Disorder Arylesterase _PREDISPOSES_ Cerebrovascular accident Arylesterase _PREDISPOSES_ Major Depressive Disorder | |
| Claims (Conclusions) | This study shows a significant association of hypertension susceptibility loci only in obese Chinese children, suggesting a likely influence of childhood obesity on the risk of hypertension. | Hypertensive disease _AFFECTS_ Obesity |
| Our data demonstrate that TrkB protects endothelial integrity during atherogenesis by promoting Ets1-mediated VE-cadherin expression and plays a previously unknown protective role in the development of CAD | ETS1 gene, ETS1 _INTERACTS_WITH_ cadherin 5 |
We demonstrated three major sources of uncertainty in scientific literature, namely, unknown, hedging and contradictory information. Different types of uncertainty and positions of uncertainty can indicate distinct information. Three types of uncertainty, i.e., unknown, hedging, and conflicting, as well as a set of cue words were proposed for classifying the level of uncertainty. Previous research has distinguished between two kinds of uncertainty, epistemic uncertainty about the past and present vs. uncertainty about the unknown future (van der Bles et al., 2019). This implies that hedging lexicons are associated with assumptions about the future and conflicting lexicons are associated with epistemic uncertainty. The distribution of hedging and conflicting lexicons in different parts of scientific statements provides potential quantitative evidence of uncertain knowledge classification.
5.3 Metrics to measure uncertainty of biomedical knowledge
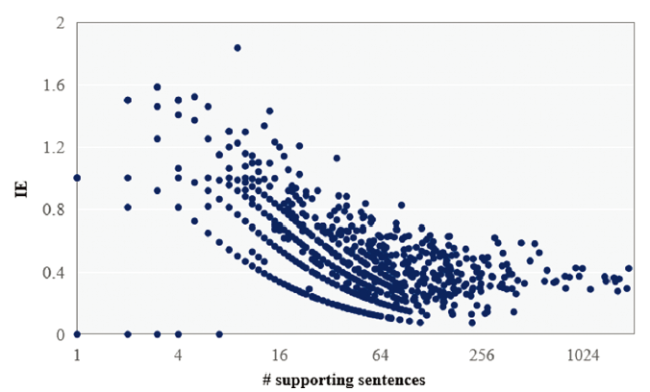
In this study, we found that IE was related to the scale of the knowledge units. With the increase of the supporting sentences, IE decreased and approached a certain value, which is also the IE value (0.38) of total biological knowledge in our triple store. We speculate that with the increase of the number of supporting sentences, the probability distribution of uncertainty types will trend to be the total corpus (Figure 5 ). This is also the limitation of the measurement method in this paper. Considering that small-scale samples are prone to small probability events, the number of the supporting sentences of the top 10 SO pairs with the highest IE is less than 15. In the future, we will consider the factor of scale and revise the uncertainty value.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 5. Trends in IE of SO pairs as the number of the supporting sentences. |
The current approach to measure uncertainty by introducing IE essentially reflected pluralistically epistemic status of scientific knowledge. The more types, the more average the type distribution, and the greater the IE. With the expansion of knowledge boundary, there are more unknowns. The significance of knowledge uncertainty may be different at different scales. For the specific scientific assertion, the uncertainty of knowledge decreases with the increase of credibility. For a topic or research area, knowledge may not be from uncertain to certain; actually, the discovery of a scientific problem, which attracts more attention, assumptions, and verification, drives the increase of contends in relevant research fields. At the meso or macro level, uncertainty may be a sign of prosperity in a given field of science. We plan to apply our model to a broader range of data sets of medical knowledge, such as RCT registry information provided by clinicaltrials.gov, to further explore the feasibility of uncertain knowledge computation using this model. We plan to leverage uncertainty-centric approaches to detect research fronts, evaluate academic contributions, and improve the efficacy of computable knowledge-driven decision support.
In conclusion, we provided a novel approach by combining natural language processing and computational linguistics with informetric methods to extract and measure uncertain knowledge from scientific statements. IE is a potential metric
to quantify the uncertainty of epistemic status of scientific knowledge represented at different levels, such as SPO triples (micro level) and semantic type pairs (macro level).
to quantify the uncertainty of epistemic status of scientific knowledge represented at different levels, such as SPO triples (micro level) and semantic type pairs (macro level).
Conflict of interest
The authors declare that they have no conflicts of interest.
Funding information
This work was funded by the National Natural Science Foundation of China (nos. 71603280, 72074006, and 82070235), the Beijing Municipal Natural Science Foundation (7191013), Research Unit of Medical Science Research Management/Basic and Clinical Research of Metabolic Cardiovascular Diseases, Chinese Academy of Medical Sciences (2021RU003), and Peking University Health Science Center and the Young Elite Scientists Sponsorship Program by China Association for Science and Technology (2017QNRC001).
Author contributions
Xin Guo (cynthiaguo@bjmu.edu.cn), Jian Du (dujian@bjmu.edu.cn), and Erdan Dong (donged@bjmu.edu.cn) designed the conceptual framework; Xin Guo and Yuming Chen (cain@pku.edu.cn) performed research and analyzed the data; and Xin Guo, Yuming Chen, and Jian Du wrote the paper.