

1 Introduction
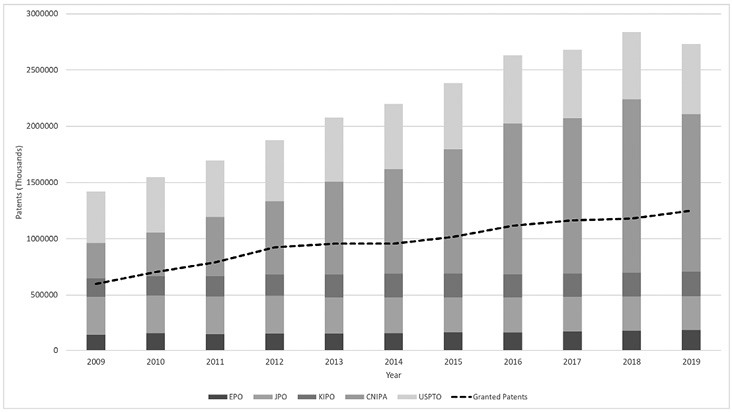
Intellectual Property (IP) is a category of property related to the “creations of the mind”, it means a vast range of activities from art to scientific works, trademarks, and inventions. It aims to promote the development of intellectual goods while giving the creators economic rights over their creations for a certain period. Intellectual Property Analytics (IPA) is a growing field that deals with the analysis of intellectual property databases to discover trends, relationships, patterns and leverage researches and innovations based on information that may not be available anywhere else (Aristodemou & Tietze, 2018). A patent is an intellectual property right granted to protect an invention such as “a product or a process that provides, in general, a new way of doing something, or offers a new technical solution to a problem”, as defined by WIPO①. Patent databases can be used to raise research and development activities, product innovations, or technology transfer. A patent is a territorial right; hence the process to obtain it is regulated by each country and conducted by a specific patent office. In general, to gain this protection, the inventor will need to file an application describing the invention and submit it to the analysis of utility, novelty, and inventiveness (World Intellectual Property Organization, 2008). The growth of applications through the years turns the patent analysis into one of the areas of IPA with significant relevance. In its preliminary statistic report from 2019, IP5② reported that 2.7 million patent applications were filed at its offices, and 1.25 million were granted, an increase of 6% compared to the previous year (Figure 1 ).
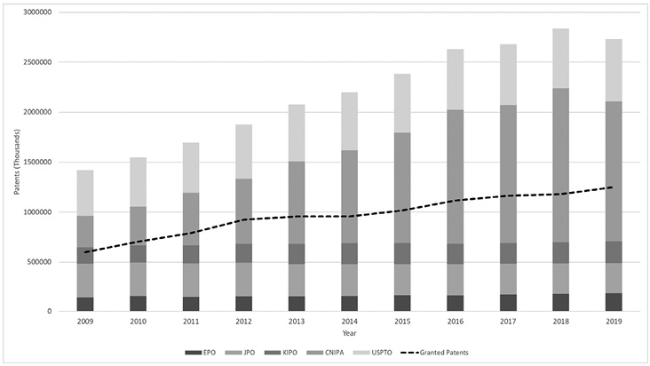
Figure 1. Evolution of patent applications and grants at IP5 offices from 2009 to 2019 (IP5, 2019). |
The patent application is a lengthy document with all the details about the invention. It contains the definition of the invention and its delimitations, structured in several sections, namely title, abstract, description, and claims. While the abstract summarises the patent, the description brings enough details to use the invention after the expiration of the patent's term. The claims, on the other hand, define the scope of a patent and help to determine the extent of protection to be granted by the patent (Instituto Nacional da Propriedade Intelectual, 2018). The process to obtain a patent granted takes several months and starts with its classification. The patent classification is a formal examination of the application document conducted by an expert who sets one or more categories to the patent request based on its content. This first step consumes a big part of the processing time and demands vast knowledge of the classification system. Meanwhile, it is crucial to analyse the invention's originality (Instituto Nacional da Propriedade Intelectual, 2018). One of the most frequent tasks of patent processing at a patent office is patent classification, which classifies patent texts into various predefined categories. The classification system is also fundamental for patent analysis by helping the navigation among the patents and performing more accurate searches. Furthermore, it facilitates retrieval tasks across different languages and patent offices since it is a multi-language code (Gomez & Moens, 2014).
Applying artificial intelligence technology to speed up the patent categorization process would promote a more efficient and accurate patent analysis. Several methods and models for patent categorization have been developed in recent years, including the use of Deep Learning and Tranfer Learning (REFS).
Our proposal in this paper is to model the patents classification, for Portuguese language patents, using several machine learning approaches, and in particular the use of Bidirectional Encoder Representations from Transformers (BERT).
To address the presented issues related to patent classification but applied to Portuguese language we trained some models to predict patent class on the second level of the International Patent Classification system (IPC). To achieve this goal, a set of pre-classified patent data made available by the INPI with documents dating back to 1995 was used and different approaches to represent the normalised text as vectors that are the input of the classification algorithms were applied and assessed.
Then, machine learning and deep learning classification algorithms were explored and their performances compared. Finally, pre-trained language models were tuned on this dataset to evaluate the transfer learning approach in this real-case scenario. We demonstrate that a transfer learning approach achieved the best result for this task. Although with a performance only 4% higher than a classic machine learning model. The remainder of this paper is structured as follows. In the next section, we present an analysis of the data used in this study. The methodology is introduced in the following section. Section 4 describes the results and discussions about it. Finally, we conclude the paper, highlighting the main contributions of this study.
2 Context and methods
2.1 Patent classification system
Administered by WIPO, International Patent Classification (IPC) is the most essential classification system and the primary reference for patent classification. The areas of technology are split across eight sections (Table 1 ).
Table 1. IPC Areas of Technology. |
| Section | Description |
|---|---|
| A | Human Necessities |
| B | Performing Operations; Transporting |
| C | Chemistry; Metallurgy |
| D | Textiles; Paper |
| E | Fixed Constructions |
| F | Mechanical Engineering; Lighting; Heating; Weapons; Blasting Engines or Pumps |
| G | Physics |
| H | Electricity |
Each section is subdivided into classes, subclasses, groups, and subgroups, counting in the last level approximately 72,000 sub-groups (Espacenet, 2021).
2.2 Patents in Portugal
In Portugal, Instituto Nacional de Propriedade Industrial (INPI) is the governmental agency responsible for protecting Industrial Property rights. Annually, INPI discloses statistical reports of Industrial Property in Portugal. After some decrease at the beginning of the decade, an increase of patents applications has been reported since 2016, with a growth of 40% from 2019 compared to the previous year (Figure 2 ).
Figure 2. Patents applications in Portugal since 2010. |
Regarding the Portuguese patents, and following a general trend, the distribution among the categories is highly unbalanced and tends to follow a Pareto-like distribution, where about 80% of the documents fall into about 20% of the categories.
2.3 Patents classification model
Text classification has been one of the most known text mining downstream tasks. Intelligent text classification methods provide superior facilities, save time and money while handling the increase of digital texts we are facing (Manning, Raghavan, & Schutze, 2008; Silva & Ribeiro, 2010). The success of text mining is highly dependent on the preprocessing phase that deals with the transformations of text into structured data sets. The challenge here is how to represent the complex characteristics of word uses and their variations across linguistics contexts in a structured way. It is not a trivial task since language by itself is complex, and its production and comprehension traverse many levels of linguistic analysis, like morphological, lexical, syntactical, semantical, and pragmatical (Feldman & Sanger, 2006; Liddy, 2001; Peters et al., 2018). Nevertheless, the lack of labelled training instances or the cost to train a model with a massive amount of data can be a limitation for specific real-world applications. To overcome these challenges, the strategy of transferring the knowledge across domains instead of training from scratch, which had a large impact on computer vision, has been revolutionising text mining. The transfer learning approach and pre-trained language models have been achieving the state-of-art in different tasks (Pan & Yang, 2010; Zhuang et al., 2021).
Several methods were proposed for addressing the patent classification task and a survey on automatic patent classification systems and traditional machine learning for text classification and clustering were proposed by Gomez and Moens (2014). Their analysis was done with a complete explanation of patents and the classification system. Furthermore, they compared studies with several algorithms, distinct feature processing methods and different levels of classification in IPC. They conclude that patent classification is a complex problem which there are still many alternatives to explore.
After defining “Intellectual Property Analytics (IPA) as the data science of analysing a large amount of Intellectual Property information to discover relationships, trends and patterns for decision”, Aristodemou and Tietze (2018) reviewed 57 articles. They promoted a discussion about AI, machine learning and deep learning approaches to analyse IPA data. They observed the growth of publications over the years, with most of them concentrated in computer science subjects. Moreover, they call attention to the high concentration of articles around artificial neural networks (ANN) and the use of backpropagation learning methods, followed by support vector machine (SVM) and conditional random fields (CRF), focused on classification tasks (Aristodemou & Tietze, 2018).
Zhang (2014) used SVM to build sub-classifiers for each class of the patents that are combined in a multi-classifier fusion where the final label is selected using an active learning method Wu et al. (2016) proposed a patent classification system based on a self-organising map (SOM), kernel principal component analysis (KPCA) and SVM, using quality indicators extracted from different parts of the document. Trappey et al. (2006) presented a patent document classification method based on neural network and critical phrases frequency that claimed to yield average accuracy above 90% in a specific test set. Further, the same authors used an ontology-based artificial neural network to automatically classify and search knowledge documents (Trappey et al., 2013).
DeepPatent is a deep learning algorithm proposed by Li et al. (2018) that combines word embedding pre-trained on the title and abstract sections using skip-gram and a Convolutional Neural Network (CNN) with multi-size filters. This approach aimed to overcome the main limitations of the traditional text encoding and machine learning algorithms, like data sparsity, the inability of capturing complex contents and poor performance on large datasets. Their model presented an F1 top 4 score of 55.09%. A recent study compares the performance of a hierarchical SVM and various neural network models. It applies state-of-the-art hyperparameter optimisation techniques on a CNN to understand the effects on the model accuracy. With this optimised neural network, they achieved 55.02% accuracy on the public Wipo-Alpha dataset③ (Abdelgawad et al., 2020).
Derieux et al. (2010) used different approaches to classify CLEF-IP dataset with English (68%), German (24%) and French (8%) patents. They found different results according to the language. Indeed, classification on German patents was not less than 10 points below English patent classification. Albeit the size of the training set has a significant impact on these results, they impute this difference to the specificities of each language as well.
Concerned about the specificity of the language used in patent applications, Risch and Krestel (2019) proposed domain-specific word embeddings. They trained a fastText model on a dataset of more than 5 million patents in English and evaluated it at the WIPO-alpha dataset through a bi-directional Gated Recurrent Units (GRUs). They concluded that domain-specific representations outperform those trained on Wikipedia, but the underrepresented classes still were a challenge in this problem.
Following the Australasian Language Technology Association Workshop, with the challenge of fine-tuning a pre-trained language model to classify Australian patents, Lee and Hsiang (2020) pre-trained BERT in a dataset of approximately 3 million documents from Google Patents Public Datasets, using the claims section only and compared their results with the DeepPatent ones. They achieve an F1 score of 63.74% in IPC subclass level (632 labels). Table 3 summarises the studies mentioned above.
Table 3. Patent classification related studies. |
| Authors | Feature Engineering | Algorithm | Section | Language | Dataset size | Number of classes |
|---|---|---|---|---|---|---|
| (Trappey et al., 2006) | Key phrases frequency based on TF-IDF | Neural Networks | full document | English | 300 training 124 test | 9 |
| (Derieux et al., 2010) | Terms extraction and semantic relation | SVM | full document | English, German, French | 985 training 2000 test | 630 |
| (Trappey et al., 2013) | Key phrases frequency based on TF-IDF | Ontology-Based Neural Network | full document | English | 333 training 160 test | 23 |
| (Zhang, 2014) | - | SVM | - | English | 5000 | 5 |
| (Wu et al., 2016) | SOM, KPCA | SVM | full document | English | 60.000 | 7 |
| (Li et al., 2018) | Skip-gram | CNN | title and abstract | English | 742.097 training 1350 test | 637 |
| (Risch & Krestel, 2019) | Domain-specific FastText word embeddings | Bi-directional GRU | title and abstract | English | ~1.7M training ~300.000 test | 637 |
| (Abdelgawad et al., 2020) | GloVe, Word2Vec, FastText | Hierarchical SVM and CNN with BOHB (Bayesian Optimization hyperband) | title, abstract, description, and claims | English | 75.000 training 28.926 test | 451 |
| (Lee & Hsiang, 2020) | - | BERT-Base | claims | English | 1,950,247 training 150,000 test | 632 |
More recently a survey focused on deep learning approaches for different patent analysis tasks was proposed (Krestel et al., 2021). The authors covered different tasks such as patent classification, technology forecasting (where patents are used to assess a technology landscape), patent text generation (where the structure and styles incorporated in published patent documents are used to automate the process of writing patent claims), and computer vision problems (considering figures and drawings from patent documents instead of text).
In particular, in their review the authors discussed advantages and disadvantages of different deep learning approaches for the considered tasks. Deep learning classification models have been widely used for automatic patent classification tasks for taking advantage of the more complex architectures. However, other approaches can also be considered, such as training representations to improve clustering, and classifying citations into applicant-provided or examiner-provided (Krestel et al., 2021). For this one, methods like PCA (principal components analysis) can be used to classify the text according to the co-citation relationship (Lay & Wu, 2005). The point of attention here is for the link between two patents. When it is negative, it can point to an inaccurate relationship (Trappey et al., 2006). In addition, the practice of citations differs between patent offices and may not be fully available in the text.
Regardless of not having found any study about patent classification in Portuguese, there are several studies about Portuguese text classification using machine learning algorithms (Gonçalves et al., 2006). In the same way, pre-trained word-embeddings have been used in other text mining use cases (De Castro et al., 2019; Rodrigues et al., 2020). To perform a Named entity recognition (NER) task, dos Santos and Guimarães (2015) pre-trained word-level embeddings using word2Vec in a corpus composed by Portuguese Wikipedia, CETENFolha④ and CETEMPublico⑤ documents. An ELMo Language Model trained using a corpus created from Portuguese Wikipedia and public documents from Brazil's Labor Courts were provided by Quinta de Castro et al. (2018). Souza, Nogueira, and Lotufo (2019) claim to present the first study where BERT models were applied to NER task in Portuguese. The models that they made publicly available can be used in many other NLP tasks in Portuguese.
3 Data
The dataset of pre-classified patent made available by the INPI contained patents since 1995, but the concentration of data became significant from 2005. The most representative years were 2007 and 2013. Each one of them contains about 11% of the data. All the eight sections of the IPC were present in the dataset but not equally. Sections A and C together counted more than 50% of the data, followed by section B (16% approximately). The distribution across the remaining sections was more similar, except for section D with only 646 instances (1,79%) (Figure 3 ).
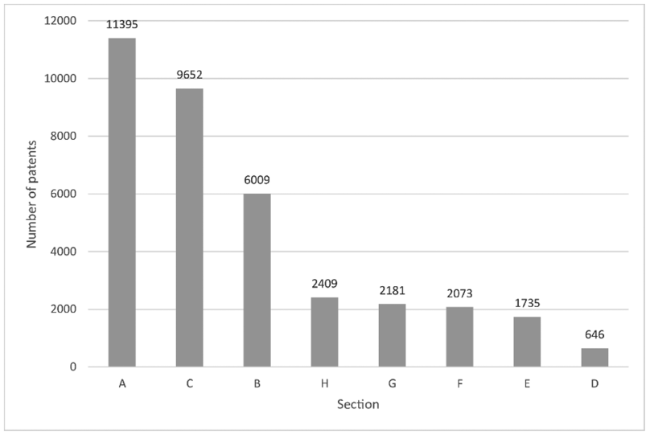
Figure 3. Number of patents by section. |
The imbalance kept on the class level as well, either by the number of classes on each section or by the number of patents in the classes. From the 124 classes (IPC 2nd level), about 18% had no more than 20 patents each. Most of the classes had between 51 and 500 instances each. Two classes had more than 2,000 patents and together they counted 36% of the training dataset, as we can see in Figure 4 .
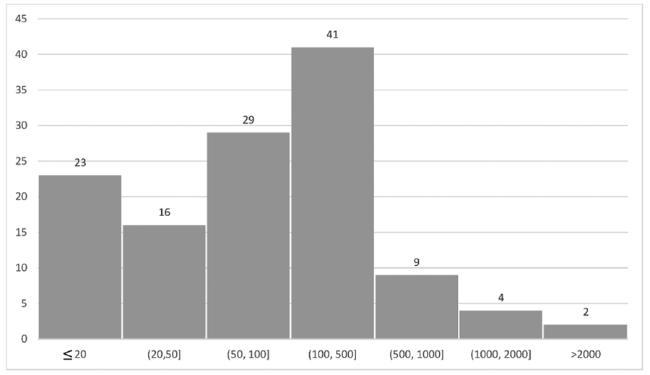
Figure 4. Frequency of classes by the number of patents. |
The size of the text that will be used as input to the classification model has some variation as well. After removing stopwords and tokenising the text, the shorter patent remained with two tokens, and the longer one with 30,515 tokens. The median text size was 310 tokens, and 96% of the patents had 1,200 tokens at most. Section C has the biggest text size standard deviation, followed by section H, as shown in the figure 5. In Figure 6 , we can observe the most representative words for each section.
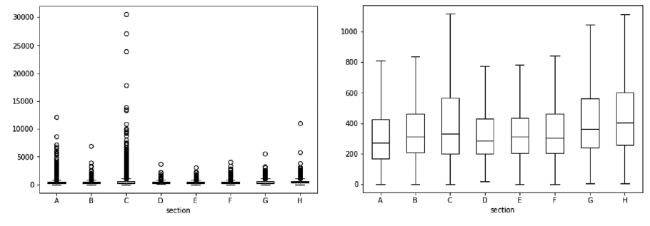
Figure 5. Boxplot of text size by section with a) outliers and b) without outliers. |

Figure 6. Wordcloud with the more frequent words by section. |
4 Methodology
To achieve the goals, we followed typical text classification methodologies (Kowsari et al., 2019). Firstly, the dataset was created based on the .xml files with granted patents made available by INPI. Then, some exploratory analysis was done to understand the dataset. Since the intention was to explore and compare different algorithms to solve the problem, the two subsequent phases, feature engineering and modelling, followed three distinct experiment paths:
1. Distinct methods to vectorise the patents used as input to machine learning models.
2. Deep learning models using an embedding layer and FastText pre-trained word-embedding.
3. A built-in language model is used to represent the words, and pre-trained models are fine-tuned.
At the final phase, the models' performance was evaluated and compared. Figure 7 brings the blueprint of the methodology used in this work study. The phases will be detailed in this section.
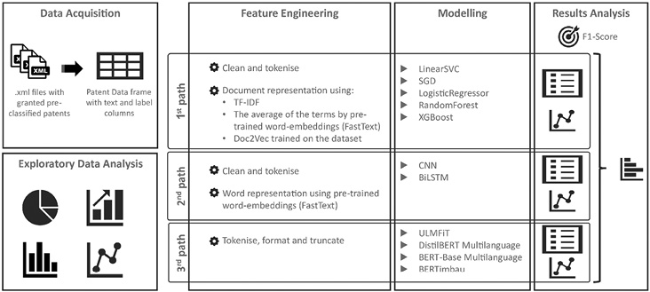
Figure 7. Applied methodology. |
4.1 Data acquisition
Two types of .xml files with general information of granted patents manually classified were made available to this study. The first one with bibliographic data (patent id, applicants, inventors), title, abstract, IPC codes and CPC codes. The second one with patent id, description and claims. After joining the data, it was counted approximately 40,000 instances and 124 different categories considering the IPC second level and only the main classification. The first step was to exclude those instances that have no abstract, claims and description data. Secondly, duplicated patents were identified. It was considered duplicated instances ones with identical id. In these cases, only the first instance was kept to preserve the main IPC classification code. Then, the IPC code was split into 5 columns according to its levels. Finally, a new feature was created by the concatenation of the title and claims or abstract features (Table 4 ).
Table 4. Features used in the analysis. |
| Feature | Description |
|---|---|
| id | Patent internal identification |
| Title | Descriptive name of the patent |
| Claims | The legal scope of the invention, including delimitations and application field |
| Abstract | A brief description of the invention presented in the patent |
| Section | IPC 1st level classification code |
| Class | IPC 2nd level classification code |
| Subclass | IPC 3rd level classification code |
| Main group | IPC 4th level classification code |
| Subgroup | IPC 5th level classification code |
Many related studies have used title and abstract as input to the classification model. However, more than 80% of the instances in this dataset had no value for abstract while claims and description features had about 0.3% of missing values and all the instances had title information. Therefore, claims were chosen to be used as the input to the classification model. Further, it brings important but more concise information about the patent application than description. For those instances without claims, abstract data was used.
The final dataset had 36,100 instances.
4.2 Feature engineering
Feature engineering is a critical step in text mining tasks. The goal is to choose the best way to represent the words of the text to be able to apply the algorithms (Kowsari et al., 2019). Different transformations were applied according to the experiment path. The first approach was to apply TF-IDF to represent the features. To do so, we started cleaning the text and deleting stopwords. Then the cleaned text was tokenised and vectorised. Even knowing that specific domain-language embeddings bring better performance (Risch & Krestel, 2019), as our dataset was not big enough to train a reasonable Language Model, we decided to validate pre-trained Portuguese word embeddings. We explored word vectors that have been trained in Portuguese corpus, using Word2Vec, Glove, and FastText architectures, on both CBOW and skip-gram strategies. Most of them were well succeeded in recognising the vocabulary used in the patent dataset. But FastText models can represent words that are not in the original dataset. For the others, in general, the worst performance occurred in section C and this can be explained by the section topic (Chemistry and Metallurgy) and the technical words used to describe these kinds of inventions.
So, as a second approach, we again cleaned and tokenised the text and applied FastText word embedding pre-trained on Common Crawl and Wikipedia using CBOW with position-weights, in dimension 300, with character n-grams of length five and window of size 5. For the pre-trained models, the feature engineering step must be performed using the methods available with the models and the dataset is transformed into the specific format that the model expected. In this case, the data was tokenised and the sentences prepared with the addition of special tokens. All the documents were truncated to the maximum length of 128 tokens.
4.3 Modelling
Following the paths described previously, traditional machine learning algorithms and ensemble methods were tested, namely Logistic Regression, Linear Support Vector Machine (SVM), Linear model with Stochastic Gradient Descent (SGD), RandomForest, and XGBoost. Starting with linear classifiers, Logistic Regression is one of the earliest and well-known classification algorithms and the SVM classifier method for many years has outstanding with its effectiveness in text classification. SGD learning allows minibatch and can be a good strategy for large-scale problems. Tree-based classification algorithms, especially voting classifiers like XGBoost, can be fast and accurate for document classification (Kowsari et al., 2019). To start training, after preparing the features by applying TF-IDF, the default algorithms parameters were applied, and the models were evaluated by cross-validation in 5 folds. Following, document embeddings were computed using two different strategies. Firstly, by the mean of the FastText word-embeddings. Secondly, by Doc2Vec, using the whole corpus. The same algorithms were run using the document vectors, and again, a cross-validation strategy was used. The best result was achieved with a LinearSVC model using TF-IDF. Then, a grid search was applied to it as a tuning strategy. In the second experiment path, two Neural Networks architectures were trained and optimised. A Convolutional Neural Network (CNN) and a bi-directional Long Short-Term Memory (BiLSTM). In both cases, FastText word-embeddings were applied. CNN can capture local correlations of spatial or temporal structures. In NLP tasks, it means extract n-gram features at different positions of text through a series of convolutional filters. These kinds of models have been achieving good performance in text classifications and also for some cases of patent classification (Hu et al., 2018; Li et al., 2018). LSTM was designed to handle sequence data and capture long-term dependence while controlling the ratio of information to forget and to store during the training. A BiLSTM is a combination of two LSTM in which the context is seen in both directions, from left to right (forward) and from right to left (backward). It means, for each word, capture previous and following information, with the ability to remember or forget it when necessary. In the end, the weights of the two networks are combined to compute the output. For this property of handle long-term dependencies, BiLSTM has been widely used in text classification (Bispo et al., 2019; Devlin et al., 2019; Hu et al., 2018).
In the last experiment path, pre-trained BERT, DistilBERT, and ULMFiT models were applied. We started with BERT-Base Multilingual Cased, a model made available by BERT authors which supports 104 languages. Next, BERTimbau which is a BERT model trained on the BrWaC (Wagner Filho et al., 2019), a large Portuguese corpus, for 1,000,000 steps, using the wholeword mask. Then, DistilBERT Base Multilingual Cased, this model is based on BERT architecture, supports the same 104 languages, and uses the BERT tokeniser, but it is built with only 6 layers, half of the BERT-Base model. It aims to be lighter and to run faster, since it has fewer parameters, while preserving a good performance. For BERT models several warmup values, text length, and hyperparameters were tried. Finally, a hyperparameter tuning and unfreeze strategy were applied to ULMFiT.
The dataset was high imbalanced, with the two most populated counting about 21% and 15% of the dataset, respectively, and the least populated ones having a single representative. Therefore, we randomly selected 2,000 patents for the two most populated classes, excluded those with just one patent, and kept the remaining untouched to create the final dataset. To handle the imbalance, the models' hyperparameter “classweight” was set to “balanced”. This parameter is used during the training phase to penalize the misclassification made by the minority classes and, at the same time, to reduce the weight of the majority classes' errors. For the models that did not have this option, we considered the metric F1 weighted that computes the average weighted by the number of true instances for each class.
4.4 Assessment
To check the performance of the models, the dataset was split into a training set with 25,267 patents and the test set with the remaining 30% of the documents. For each experiment path, after training the models, the unseen test set was prepared with the required transformations and submitted to the model to predict the patent class. We used the predicted and real labels to compute Precision, Recall, F1 and F1 weighted average as evaluation metrics.
Precision is the number of patents correctly classified as a percentage of all the patents classified in that class
Precision= $\frac{TP}{TP+FP}$.
Recall is the number of patents correctly classified as a percentage of all the patents belonging to that class
$Recall=\frac{TP}{TP+FN}.$
F1, also known as F-score or F, is the harmonic mean of precision and TP rate
$F1=\frac{2×Precision×Recall}{Prevision+Recall}$.
F1 weighted average is the average of F1 for each class weighted by the number of items of each label in the actual data.
5 Results and discussion
In this section we present and discuss the results obtained for the proposed approaches. Some discussion about the performance of the best model will be done at the end of the section. In Table 5 we can observe the results for each algorithm and feature engineering method applied in the first path. The best result was with LinearSVC using TF-IDF. Then, a grid search was applied to it as a tuning strategy. The tuned LinearSVC presented an F1-weighted score of 0.608 on the test set and was used as the baseline.
Table 5. Mean F1 score (cross-validation k=5) with different feature engineering methods. |
| Model | F1_weighted (%) |
|---|---|
| LinearSVC (baseline) | 60.8 |
| CNN | 50 |
| DistilBERT Multilingual | 50.1 |
| BiLSTM | 57 |
| ULMFiT | 57 |
| BERT-Base Multilingual | 59.5 |
| BERTimbau | 63.6 |
We can note that the performance of these models using document embeddings was in general worse than the same algorithms when TF-IDF was used. The strategy of aggregate the terms of the document by the mean did not result in a good tactic. The same word-embeddings were used as input to the Neural with a better result.
Networks with a better result. The best results for each model in the second and third paths can be seen in Table 6 . While CNN and DistilBERT got the lowest scores, BERT models achieved the best performance.
Table 6. F1 score on the test set. |
| Model | F1_weighted (%) |
|---|---|
| LinearSVC (baseline) | 60.8 |
| CNN | 50 |
| DistilBERT Multilingual | 50.1 |
| BiLSTM | 57 |
| ULMFiT | 57 |
| BERT-Base Multilingual | 59.5 |
| BERTimbau | 63.6 |
Regardless of they share the grammar, Brazilian Portuguese and European Portuguese present notable differences in vocabulary and sentence structure. Hence it is interesting to note that despite BERTimbau had been trained exclusively on a Brazilian Corpus, it was the model that presented the best performance to solve this problem, even than the multilingual BERT, trained on a corpus with both variants. However, the performance was only 4% superior to the baseline, despite the complexity of the model.
In the analyses of the results obtained using the pre-trained BERTimbau, when we observe the section level, sections A, C, and H have average F1 score higher than the general F1 score, 17%, 10% e 9% higher, respectively. On the other hand, sections D and G have the worst score by section (Table 7 ).
Table 7. Precision, Recall and F1 score by Section. |
| Section | Precision | Recall | F1 |
|---|---|---|---|
| A | 0.7923 | 0.7 | 0.7433 |
| H | 0.6805 | 0.7248 | 0.7019 |
| C | 0.6515 | 0.7427 | 0.6941 |
| E | 0.5981 | 0.5923 | 0.5952 |
| F | 0.5446 | 0.5393 | 0.5419 |
| B | 0.5291 | 0.5388 | 0.5339 |
| G | 0.4903 | 0.4633 | 0.4764 |
| D | 0.5098 | 0.4041 | 0.4509 |
The worst result in section D was not a surprise since it had the lowest amount of training samples. On the other hand, the more numerous classes—A61 e C07 (2,000 samples in training set each)—are in the top 10 best F1 scores, with 79.70% and 80%, respectively. However, the number of training samples was not a factor that decisively affected the results. In general, the classes with more than 500 training samples had F1 scores bigger than 0.680. But surprisingly, the best result (F1 score = 88.20%) was A24 that had had less than 100 samples on the training set. In the same way, A43 (F1 score = 81.60%) and B64 (F1 score = 77.40%) are presented in the top 10 scores; regardless, they have had only 78 and 41 samples in the training set, respectively. For those classes, good performance could be explained by their specific context. The more frequent words in class A24, like “cigarro”, “tabaco” and “filtro”, are highly representative of its context. The same happens in class A43 with “sola”, “calcądo” and “palmilha” or “aeronave”, “avião” and “aterragem” for class B64.
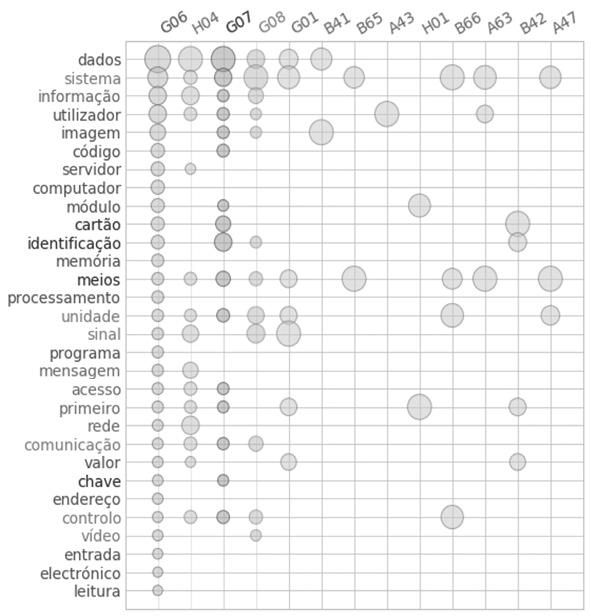
In contrast, classes like B01 (431 samples), F16 (407 samples), and G06 (316 samples) scored less than 50% on the test set, even with a considerable quantity of samples in the training phase. In some cases, the broader context of those classes, overlap with other classes or related terms could explain the misclassification. For instance, 60% of the misclassified instances on class B01 (Physical or Chemical Process or Apparatus in general) were predicted as some class of section C which also deals with the Chemistry subject. Besides, almost 30% of G06 (Computing; Calculating or Counting) instances were classified as H04 (Electric Communication Technique). Figure 8 shows the top frequent words for some classes and the similarity of terms when compared to the class G06 to which they were the most confounded.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 8. Classes G06 most frequent words in parallel to most similar classes. |
Despite the good result in some classes with a small number of samples, in general, BERT did not have a good performance when classes had less than 60 training samples. In this group, 44 classes had an F1 score equal to 0. Although it counts only for 4% of the test set, it represents about 36% of the classes.
The results obtained are consistent with the literature review, although the size of the dataset, the IPC level chosen for classification and the metric selected to evaluate the experiments do not allow a direct comparison between them. In this study, we obtained an F1 score of 63.60% at the second level of IPC (120 classes) by training the model on about 25,000 Portuguese patents. (Trappey et al., 2006) using about 300 patents to train and just over 100 patents to test, with the full text of the documents and 9 classes, obtained and accuracy over 90%. In a second study, training the model for 23 classes, they outperformed it by 4%. With much more data and classes, Abdelgawad et al. (2020) had an accuracy of 55.02% and outperformed their baseline with 65.43% accuracy using a CNN model. With a combined method which builds from 3 to 15 classifiers for each test document, Derieux et al. (2010) trained on less than 1,000 patents to predict 630 classes and had 84.7% accuracy for English documents, 74.1% for documents in German and 78% for documents in French. With a multi-label classification approach, Li et al. (2018) achieved top1 precision of 83.98% and top 4 F1 of 55.09%. Using the patent word embeddings trained by them, Risch and Krestel (2019) achieved 49% of precision for 637 classes. Using a BERT-Base algorithm and the claims sections, Lee and Hsiang (2020) obtained a F1 of 63.74% at the IPC subclass level (632 classes), training the model with almost 2,000,000 patents.
6 Conclusions
Patents are more than ever used by companies, not only as a financial protection instrument but also as a database for researches and innovation. Since a patent is a lengthy descriptive document, it has become an interesting dataset to be explored in text mining tasks, and patent analysis a growing area for task automation. In this article, we presented the first automatic patent classification study in Portuguese. We aimed to train machine learning models to classify Portuguese patents in the second level of IPC, one of the critical phases of the grant patent process, using a dataset with granted patents put available by INPI. Then, evaluate the results, compare them and identify the most relevant attributes in the classification process. After a fine-tuning phase, BERTTimbau—a BERT architecture model pre-trained on a large Portuguese corpus—presented the best results to solve this task with an F1 score of 63.60%. Although, the performance was not much superior to the LinearSVC model used as a baseline. Since the dataset was high imbalanced, as usual in patent applications, it was expected that the classes with the lowest quantity of samples presented the worst performance. It happened in some cases, especially in classes with less than 60 training samples. However, the number of training samples was not the decisive factor. For instance, the class with the best performance achieved an F1 score superior to 80% with only 117 training samples. The specificity of the context was a relevant factor here. The most frequent words in this class were good representants of its context, like “cigarro”, “tabaco”, and “filtro”. On the other hand, classes on which general words like, “dados”, “sistema” and “informacão” were broadly used to describe the patent were easily misclassified. Along with the unbalance, the high number of classes (124) brought a particular challenge to the model that did not classify correctly any patent of 44 classes, almost 36% of the total. Although they contributed only with 4% of the patents in the test set. Patent classification is a challenging task because of the hierarchical classification system, but also because of the way a patent is described, the overlap of the contexts, and also the underrepresentation of the classes. Even so, the final model presented an acceptable performance given the size of the dataset and the task complexity. In addition, it is an area of growing interest that can be leveraged by the new researches that are revolutionising text mining. For further research, the authors suggest to focus on building hierarchical models from the section to the subgroup level to deal with the challenge of overlapped contexts.
Author contributions
Roberto Henriques (roberto@novaims.unl.pt): Conceptualization (Equal); Methodology (Equal); Supervision (Equal); Writing—review & editing (Equal); Adria Ferreira (adria.ferreira@gmail.com): Conceptualization (Equal); Methodology (Equal); Project administration (Equal); Writing—original draft (Equal); Mauro Castelli (mcastelli@novaims.unl.pt): Formal analysis (Equal); Validation (Equal); Writing—review & editing (Equal).
Acknowledgement
This work was supported by national funds through FCT (Fundação para a Ciência e a Tecnologia), under the project - UIDB/04152/2020 - Centro de Investigação em Gestão de Informação (MagIC)/NOVA IMS.