

1 Introduction
There has been an ongoing debate on whether econometrics is scientific. Leamer (1983) stated that “the art of econometrics is that the researcher fits many (even thousands) of statistical models in a computer terminal, from which one or a few estimates that meet the author's expectations are reported in the paper.” Since the credibility revolution, scholars have increasingly emphasized research design, using randomized experiments as the basis for research design. That is, allowing data to automatically show causal effects through scientific design (Zhao, 2017).
Regression is the most common method used in econometrics to estimate the relationship between two variables (Colin, 2015; Frölich & Sperlich, 2019). Many causal inference methods, such as instrumental variable methods using two-stage least squares estimation, are also based on regression (Huntington-Klein, 2021). This paper is concerned with the regression-based statistical control approach to causal inference (hereafter referred to as regression), that is, assessing causation between variables by adding control variables.
Regression is widely used, but also widely misunderstood. In econometrics, estimating causal effects using regression depends on selecting a core set of control variables to eliminate selection bias from the invisible things. In most cases, however, it is not clear what “core variables” and “invisible bias” mean. Conceptual confusion has also led to a methodological confusion. The perception of most researchers remains that “the more control variables are included, the more satisfactory the regression model results will be” (Cinelli et al., 2021). Bertomeu (2016) called it the “kitchen sink approach,” i.e., everything in the kitchen can be put inside. A rule of thumb, suggested by Angrist and Pischke (2009), is that good controls are those that are fixed at the time the treatment variables we are interested in are decided, and bad controls are the outcome variables in our experiments. Additionally, scholars have defined “good controls” as ones that are unaffected by treatment and, correspondingly, “bad controls” as those that are affected (Rosenbaum, 2002; Rubin, 2009). Although these arguments have contributed to the literature, the conditions mentioned in them are neither necessary nor sufficient for determining whether a variable is a good control (Cinelli et al., 2021). Furthermore, traditional methods test the robustness of regression estimates by observing whether they are sensitive when specific variables are added or removed (Angrist & Pischke, 2014). However, we believe that doing so does not help to improve our confidence in the robustness of the results, when it is not clear how the variables we add or remove relate to other variables. These issues are clarified in this study from the perspective of causal models.
Q1: What is implied by the assumption of causal inference using regression in observational studies?
Q2: How should the core control variables be selected to satisfy this assumption?
Q3: How should robustness tests be conducted on regression estimates of causal effects?
Our aim is to clarify and explain the ambiguities in the descriptions using concepts from causal models to dispel the common misconceptions of scholars in related fields. This paper offers a better conceptual understanding of the assumption underlying the use of regression for causal inference in econometrics and combines it with concepts from causal models. In addition, this paper can guide scholars in using regression to make reliable causal inferences, correctly selecting core variables to eliminate confounding and avoid introducing selection bias.
The remainder of the paper is structured as follows. First, within the framework of the causal model, we explain the assumption of using regression for causal inference. Second, we discuss how the core control variables were selected to satisfy this assumption. Further, we discuss how robustness tests are conducted. Finally, we conclude with a summary of our views.
2 Assumption for causal inference using regression in observational studies
Causal inference based on regression in econometrics assumes that selection bias due to unobservable factors is almost eliminated when the treatment and control groups are the same on the key observed variables (Angrist & Pischke, 2014). Two types of selection bias were mentioned, as explained below.
In addition, bad controls can sometimes lead to another type of selection bias. Angrist and Pischke (2014) addressed this issue in their book, stating that “There is a second, more subtle force of confounding here: bad control can produce selection bias....” For example, revisiting the above example, we might consider the variable of occupation, a good predictor of education and income levels, which should be controlled for, following the logic of omitted variable bias; however, this would lead to a new selection bias (Angrist & Pischke, 2014). On the other hand, sometimes we can inadvertently lead to bad controls; for example, when estimating the effect of folic acid supplements given to pregnant women shortly after conception on the fetus's risk of developing a cardiac malformation during the first two months of pregnancy. What we do know is that cardiac malformation increases mortality, and that folic acid supplementation reduces mortality by reducing the risk of malformations other than cardiac ones. However, we were only able to observe survived fetuses. That is, we inadvertently controlled the variable of whether the infant died, under which condition there must be a correlation between folic acid supplementation and the risk of cardiac malformations, even if, in actual fact, there is no causation between the two (Hernán & Robins, 2020).
Therefore, it is important to clearly define the biases and their sources to help identify them, especially those that we may not be aware of. In the above formulation of bias, the concepts of confounding, omitted variable, and selection bias are all tangled. This leads to ambiguities in defining the various biases, making it difficult to understand the assumption. Hence, in order to better understand this assumption, within the framework of the potential outcome and structural causal models, we redefine what omitted variable and selection bias are as follows: Omitted variable bias is confounding owing to the omission of the common cause variable of the treatment and outcome from the equation, such as the individual attributes, while selection bias due to bad control results from conditioning on the common effect of the treatment and outcome, such as the occupation and whether the infant died.
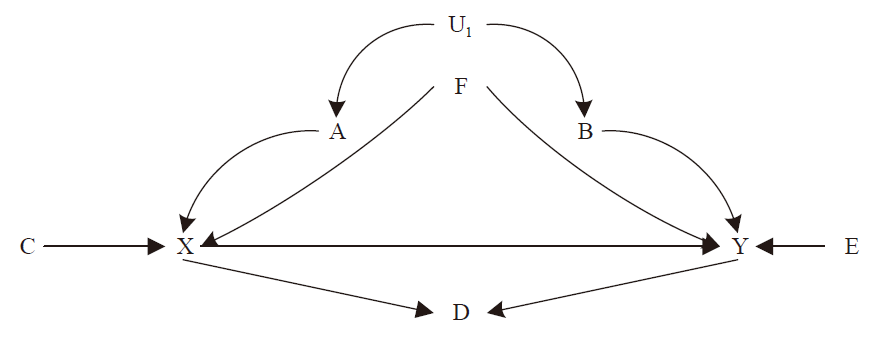
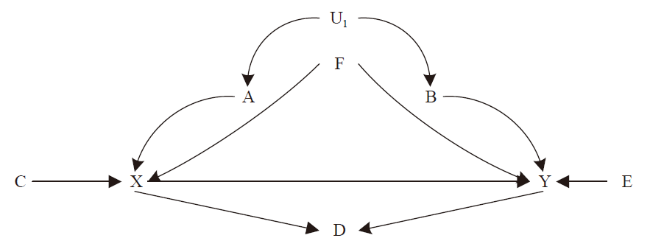
A crucial assumption of causal inference is that (conditional on a set of variables) the treatment and control groups are (conditionally) exchangeable (Hernán & Robins, 2020). Confounding and selection bias (different from selection bias in econometrics) lead to a lack of exchangeability between the treatment and control groups (Hernán & Robins, 2020). Of these, confounding bias occurs from the presence of common causes of treatment and outcome, and is often considered a typical shortcoming of observational studies, whereas selection bias results from conditioning on the common effects (referred to as a collision variable) of treatment (or treatment-related) and outcome (or outcome-related), and can occur in both observational studies and randomized experiments (Hernán & Robins, 2020). As shown in Figure 1 , U1 (unobservable)and F are confounding variables, and D is a collision variable.
{kind=link}
{kind=link}
Figure 1. Causal diagram |
Exchangeability implies that bias due to unobservable factors is almost eliminated. The correlations obtained using the regression analysis can then be interpreted as causation. Thus, we reconceptualize the assumption of regression-based causal inference in econometrics as follows. When our list of control variables contains a set of core variables, we control for (almost) all confounding factors, but no selection bias.
3 Selection of core control variables and robustness tests of the regression estimates
How do we meet this assumption to obtain reliable regression estimates of causal effects? According to Angrist and Pischke (2014), greater confidence in the regression estimates of causal effects is based on the requirement that the model contains a core set of control variables, and the estimates obtained are insensitive to whether certain specific variables are added to or excluded from the model. However, the source of this confidence remains ambiguous. First, which variables should be included in the core set of control variables? Second, which specific variables should be added or removed to ensure that the results are robust? The above statement does not provide a precise answer, which leads to confusion in making regression adjustments and impacts the effectiveness of the study. Researchers find it hard to choose control variables rationally and predictably to avoid bias based on the research questions and research hypotheses. According to the omitted variable bias formula, people are confused about which variables they should control for; therefore, the default practice is to control for everything they can measure. Although this is a simple procedure, it is both a waste of resources and riddled with errors (Bareinboim et al., 2022; Pearl & Mackenzie, 2018). We often see articles with the formulation “To mitigate omitted variable bias in the model, we also control for....” followed by a long list of control variables (Morgan & Winship, 2015; Pearl & Mackenzie, 2018). However, adding a series of control variables to a regression model may not help assess causal effects and amplify biases; some control variables may be colliders, and conditioning on the collider opens new backdoors, which are otherwise blocked (Cinelli et al., 2021). For example, to evaluate the causal effect of X to Y in Figure 1 , we should control for U1 (since U1 is unobservable, we can block this backdoor path X←A←U1→B→Y by controlling for A or B, or A and B) and F (X←F→Y), while avoiding controlling for D (X→D←Y, controlling for D will open this backdoor path). On the other hand, this confusion also creates problems for robustness tests of the regression estimates. Studies often perform robustness tests by trying different combinations of control variables, that is, adding or removing some specific variables and checking whether the estimates are sensitive to this. However, this approach is self-defeating and can be manipulated. For example, if the variable added or removed is causing y and is independent of the treatment variable (e.g., E in Figure 1 ), such tests are meaningless, because the addition or removal of such control variables only affects the precision of the estimates.
Based on the previous discussion, when selecting core control variables, the priority is to select a set of variables that constitute a sufficiently de-confounded variable, based on a reliable causal diagram, to block all backdoor paths, while avoiding blocking causal paths or opening new backdoor paths (see Pearl's (1995) backdoor path rule for details). As shown in Figure 1 , {A, F} or {B, F} or {A, B, F} are reliable sets of de-confounding variables, and a obtained by the regression model Y = a0 + a*X + b*A + c*F, is the average causal effect of X on Y. In this case, as Pearl and Mackenzie (2018) stated, “correlation does not imply causation should give way to some correlation do imply causation.” Second, it does not make sense to conduct robustness tests of the existing regression estimates of causal effects by adding or removing specific variables. Robustness tests on regression estimates should be conducted on the basis of a reliable causal diagram, similar to a placebo test, where the remaining two variables on the causal diagram are selected, except for treatment and outcome, all paths between them are identified, and all open paths are blocked by the control variable. If the two variables are still correlated with each other, there must be a path that we have not considered, and our causal diagram is flawed, implying that the regression estimates obtained for the causal effect between treatment and outcome may be wrong (Huntington-Klein, 2021).
4 Conclusions
In summary, this paper argues that regression is not always unreliable in causal inference, but it requires us to be more rigorous in our approach. First, the data generation process is depicted as accurately as possible, based on existing theory. We identify variables based on theory and assumptions, and analyze possible relationships between variables based on existing knowledge. Second, a causal diagram is drawn to identify all backdoor paths between the treatment and outcome and select a sufficiently de-confounded set of variables to block them. At the same time, it is important to avoid blocking causal paths or opening new backdoor paths. At this stage, we need to increase the transparency of our research and show the reader what assumptions our results are based on, and the extent to which these assumptions are reliable. Accordingly, estimates of causal effects between treatments and outcomes can be obtained through regression analysis, and tested for robustness using a placebo-like test based on a causal diagram. Indeed, regardless of how much effort we put into demonstrating that our causal conclusions are reliable, there remains an inevitable threat of unobservable confounding in studies based on observational data. Regression can only address observable confounding factors (e.g., if F is unobservable, there is no way to block the backdoor path X←F→Y by controlling it). However, one cannot deny a study without clearly identifying the origins of these threats. As argued by Hernán & Robins (2020), such criticism does not make a scientific statement but a logical one.
Author contributions
Fan Chao (20B910019@stu.hit.edu.cn): Conceptualization (Equal) and Writing - original draft (Lead); Guang Yu (yughit@126.com): Conceptualization (Equal) and Writing - original draft (Supporting).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding information
This research was funded by the National Natural Science Foundation of China (Grant No. 72074060).