

1 Introduction
Social media platforms (SMPs) have become one of the most common sharing places where online users usually express their opinions and feelings, boosting the flow and broadcast of information (Stieglitz & Dang-Xuan, 2013). When public emergencies occur, the SMPs are becoming the main sharing tools of online users to spread information and opinions (Martínez-Rojas et al., 2018). Due to the fast diffusivity and transmissibility of the SMPs, public emergencies spread more quickly and widely on the Internet. Also, online users are subjected to emergencies, whose behaviors and emotions can influence the development and evolution of public emergencies (Zhou & Moy, 2007). In a case where the emotions of online users are mostly negative, the impact triggered by public sentiment, on society and national security will be fatal. Thus, it is important to apply the sentiment analysis on social media contents during public emergencies.
However, it is still a challenging task to analyze the sentiment of the opinion content, generated by users on SMPs, during public emergencies. Firstly, because of the casualty and irregularity of text contents on SMPs, the sentimental polarities of such contents are ambiguous and hard to be distinguished accurately. Additionally, users’ opinions are sometimes ironic, and the polarities are more difficult to be recognized during public emergencies. Moreover, they prefer to choose texts including some attachments such as images or short videos, in the form of multimodal content rather than only plain texts (Poria et al., 2017). An example of SMPs during public emergencies is shown in Table 1 . Hence, it is necessary to consider the texts and images together for analyzing the sentiment of multimodal contents from SMPs during public emergencies.
Table 1. An example of multimodal posts on SMPs during public emergencies |
| Image | Text |
|---|---|
 | On the day of the “Bus Crash”, I also took on a bus in the urban area of Chongqing. As long as one passenger on the bus came out to stop that, it wouldn’t happen today. Rest in peace. |
Recently, sentiment analysis during public emergencies has become rapidly growing and received more attention. However, most of the state-of-the-art sentiment analysis methods are based on textual contents and linguistic structures. For example, Zhang et al. (2018) used an extended sentiment dictionary to classify the sentiments into positive, negative, and neutral. Also, Wu et al. (2020) employed a Convolutional Neural Network (CNN) combined with the Ortongy-Clore-Collins (OCC) model to analyze the sentiments of the public. Nevertheless, these studies utilize machine learning algorithms for analyzing the text-oriented data and face the situation that the accuracy of proposed models is difficult to improve.
Essentially, texts and images are heterogeneous, but they are correlated in contents and semantics. The existing methods of multimodal sentiment analysis can be classified into three main groups, namely: feature-level fusion, intermediate fusion and decision-level fusion based on the multimodal fusion strategy (Pérez Rosas et al., 2013; Poria et al., 2017). Such strategies can have a tremendous impact on the performance of the whole model. In deep neural networks (DNN), deep intermediate fusion provides unique advantages and is more popular. Moreover, the extracted information from different modalities, via DNN, is unified in an interacted mode. Then, it produces more complementary and valuable features, which is the aspect that the other fusion strategies cannot provide. Additionally, it still can capture the correlation between different modalities and the whole training process is in a manner of end-to-end. For example, Hu & Flaxman (2018) proposed a multimodal sentiment analysis model combining texts and images. Long Short-Term Memory (LSTM) (Hochreiter & Schmidhuber, 1997) and pretrained Inception network are employed to generate unimodal features. Then, different modal features were integrated into fully-connected layers. Zhao et al. (2019) proposed an image-text consistency analysis framework, fusing general pretrained textual features and image basic and tag features. Cai & Xia (2015) presented a CNN framework for multimodal sentiment analysis. The textual and visual features were produced by 1d CNN and 2d CNN architectures respectively and then fused in the intermediate layer. Though these methods have achieved the state-of-the-art performances, they do not utilize the semantic information in texts and complementary information in images.
In this study, we propose a Deep Multimodal Fusion Model (DMFM) to deeply excavate sentimental information from texts and images for social media multimodal contents during public emergencies, using multimodal fusion methods. In textual sentiment analysis, a large-scale public emergency textual dataset is employed to train word2vec model for obtaining word vectors, which is passed to textual sentiment analysis network with BiLSTM to derive dense encoded textual embeddings. To fully exploit visual information from images, fine-tuning strategies are explored in a modified VGG16-based network to boost the performance of visual sentiment analysis. The best-performed fine-tuning strategy is adopted to generate rich visual embeddings. Lastly, a multimodal fusion technique is proposed to fuse textual and visual embeddings, as well as produce the predicted labels. The main contributions of our work can be summarized as follows:
We design a novel method to analyze the sentiment of social media content during public emergencies by excavating the features both from texts and images deeply.
We propose a Deep Multimodal Fusion Model (DMFM) to conduct multimodal sentiment analysis in public emergencies. The DMFM can capture the semantic information from texts and exploit the complementary information of images.
We evaluate the proposed model by examining it on Weibo and Twitter public emergency datasets. Also, we compare the experimental results with baseline models. Results show the advantage of DMFM.
The rest of the paper is organized as follows: Section 2 covers related work on sentiment analysis; Section 3 describes the proposed method; Section 4 reports experimental results; Section 5 summarizes the paper and outlines the future work.
2 Related work
2.1 Sentiment analysis during public emergencies
Sentiment analysis, also known as opinion mining, is used to analyze people’s views, emotions, attitudes, etc., on a certain entity, e.g., products, services, and topics (T. Chen et al., 2017). During public emergencies, the sentiments of online users are the most direct performances of their attitudes about events. They usually express their opinions via social platforms, and have a great impact on the evolution of events (S. Zhang et al., 2018). Sentiment analysis techniques are increasingly used to grasp reactions from social media users to the unexpected and stressful social events (Gaspar et al., 2016). There have been some researches about the sentiment analysis in public emergencies. For example, to address the lack of the sentiment annotation rule, Wu et al. (2020) designed an annotation rule based on OCC model for enhancing the sentiment classification of social crisis texts. Smith et al. (2018) performed network and content analysis for recognizing the emotional changes in public emergencies. W. Zhang et al. (2020) built a domain emotion lexicon for public emergencies to detect the evolution of negative public opinions. However, these studies are all based on the text contents in social media to analyze the sentiments, and ignore the other attachments (e.g., image, video) to text contents related to users’ sentiments.
With the development of SMPs, the expression form has changed greatly, from plain textual contents to ones including other modalities, such as images (Zhu et al., 2022). Technically, it is difficult to classify the sentiment using the unimodal-based methods when the meaning of textual contents is ambiguous. Thus, we consider combining the texts and images attached with texts during public emergencies, to analyze the sentiments of users.
2.2 Unimodal sentiment analysis
(1) Textual sentiment analysis
In general, the text-based sentiment analysis methods can be divided into three types, namely: emotion lexicon-based, statistics-based, and deep learning-based (Young et al., 2018). However, emotion lexicon-based algorithms depend on the quality and size of the lexicon, which can restrict the performance of sentiment analysis extremely due to the poor scalability and migration. When dealing with the textual contents in different domains, the emotion lexicon usually needs to be upgraded or reconstructed, and is not suitable for the constantly changing network content. The statistical methods usually employ supervised machine learning algorithms to train a model with the dataset. Moreover, when the trained corpus is large-scale, the traditional machine learning models cannot classify the sentiments efficiently because of the high computational complexity and dependency on the quality of annotated data (Moraes et al., 2013).
Deep learning techniques have made great success in NLP (Abdi et al., 2019; C. Chen et al., 2023). The quality of word representation has a vital influence on the performance of the model in sentiment analysis. There are some successful word representation models, such as Glove (Pennington et al., 2014), Word2vec (Mikolov et al., 2013), Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2019). Rezaeinia et al. (2019) proposed an improved word2vec to train word vectors for sentiment analysis. Zhao et al. (2019) employed the BERT to obtain pretrained word embeddings to perform document-level sentiment analysis. Remarkably, the use of word embeddings in the aforementioned methods is all pretrained on a large-scale general corpus, rather than domain corpus.
In the aspect of learning the contextual information, the sequential models, such as Recurrent Neural Network (RNN) and its extension LSTM, are popular and effective. For example, Socher et al. (2013) applied the RNN to recognize the sentiments of movie review text contents, and experiments showed that the RNN had promising results in sequential data. However, with the gap of contextual content becoming large, distant information cannot be learned by RNN and LSTM overcomes that well. Liu & Guo (2019) combined the Bi-LSTM and a CNN layer to analyze the six emotions in textual contents. Wang et al. (2018) proposed a stacked residual LSTM method for sentiment analysis.
(2) Visual sentiment analysis
The visual sentiment is the human’s emotional response to images. CNN has made breakthroughs in many Computer Vision (CV) tasks, such as image classification (Kim et al., 2022), visual question answering (Ruwa et al., 2019; Yusuf et al., 2022), image retrieval (Lu et al., 2019). Recently, there has been some research about the visual sentiment using CNN. For example, T. Chen et al. (2014) proposed a visual sentiment recognition model, named SentiBank2.0, containing five convolutional layers and three fully-connected layers. They employed over one million Adjectives-Noun-Pairs (ANPs) with annotation to train the model. Their experiments showed the proposed model achieved better performance than traditional machine learning methods. In practice, training a deep neural network needs large-scale datasets with accurate annotation. However, collecting large-scale datasets with accurate annotation is difficult and time-consuming. A proper way to solve that is transfer learning. Campos et al. (2017) proposed a model constructed by a pretrained AlexNet-styled network and fine-tuned the model on the DeepSent dataset to perform the validation of visual sentiment analysis. Song et al. (2018) presented a deep CNN model with attention mechanism, recognizing the visual sentiment through detecting the emotional area with the strongest polarity. Yang et al. (2018) presented a visual sentiment analysis model, considering the overall and regional information of the image.
The aforementioned unimodal methods have gained great achievements over the latest few years. However, facing the expression changes of users on social platforms, in a form of multimodal content, unimodal sentiment analysis is not sufficient to realize the accurate recognition.
2.3 Multimodal sentiment analysis
The combination of different unimodalities, e.g., images, texts, and audios, is seen as multimodalities (Zhao et al., 2019). The progress of technology changes the expression in social platforms, transforming from unimodal contents to multimodal contents. Currently, multimodal sentiment analysis has become the hotspot in sentiment analysis (Cambria, 2016; C. Chen et al., 2023) and a series of related tools have been developed, e.g., MuSe-Toolbox (Stappen et al., 2021).
The studies about multimodal sentiment analysis can be divided into the following categories, which mainly are feature-level fusion, intermediate fusion, and decision-level fusion. In the aspect of feature-level fusion, Poria et al. (2016) concatenated the textual features extracted from CNN, facial features extracted from tools, and audio features extracted from OpenSMILE into a long vector, and then the fused vector was fed into the classifier to perform sentiment analysis. Cambria et al. (2013) proposed the model Sentic Blending to analyze the sentiment based on the affective knowledge fusing multiple unimodal features. Pérez Rosas et al. (2013) analyzed the sentiment in videos through fusing the textual features, facial features, and audio features. Intermediate fusion usually happens in neural networks. To analyze the sentiment in videos, Zadeh et al. (2017) proposed a novel intermediate fusion technique in a way of tensor fusion. The embeddings extracted from different modality subnetworks were fused in a form of vector outer product. Majumder et al. (2018) proposed a hierarchical fusion strategy. In the strategy, unimodal features are fused two in two and the fused bimodal features are fused again to generate trimodal features. Besides, K. Zhang et al. (2022) construct the model based on reinforcement learning and domain knowledge to recognize emotions from the real-time videos, and obtained satisfying results in the public datasets. In decision-level fusion, Song et al. (2018) employed different classifiers to recognize the sentiment of different modalities, and then used an Artificial Neural Network or k-Nearest Neighbor to classify the outputs, producing the final labels.
Though great success has been achieved in multimodal sentiment analysis, these methods still have some limits. The textual representation needs to be enhanced for a specific task and the information in the corresponding images is not utilized completely. Thus, we propose a deep multimodal fusion model to exploit the semantics correlation and complementary emotional information in texts and images.
3 The proposed model
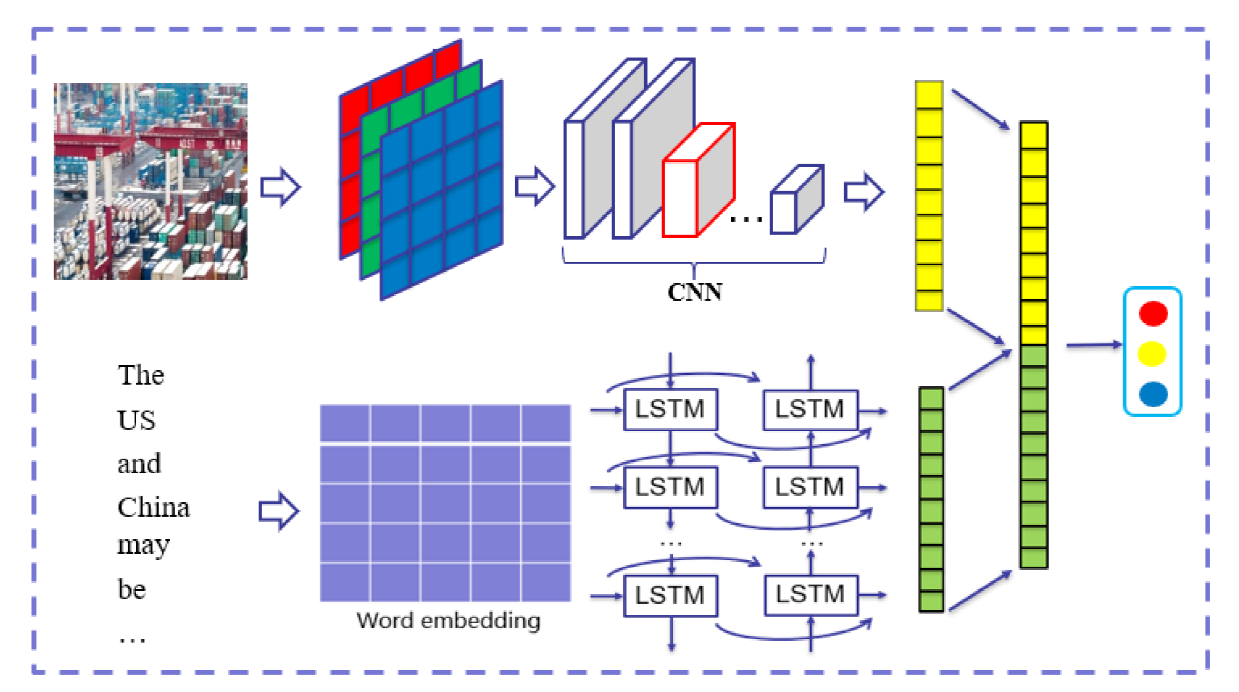
In this section, we explain the Deep Multimodal Fusion Model (DMFM) in detail presented in Figure 1 . Firstly, we employ the Word2vec model, pretrained on a large-scale public emergency text corpus, to represent texts. Secondly, we utilize the BiLSTM to generate dense encoded textual features for textual sentiment analysis. Thirdly, we apply a deep visual sentiment analysis network, which is a modified VGG16 model (Simonyan & Zisserman, 2015) pretrained on ImageNet dataset (Deng et al., 2009) to extract the complementary features from images for deep visual sentiment analysis. In this stage, to dig sentimental information of images deeply, different fine-tuning strategies are explored and the best-performed fine-tuning strategy is adopted. Lastly, we adopt a deep intermediate fusion technique by combining rich textual and visual features, for passing into fully connected layers, and generating the final predicted label.

Figure 1. The structure of the DMFM. |
3.1 Textual sentiment analysis
Text representation has an important effect on the performance of the whole model. Distributed representation can embed texts into space, from high-dimension to low-dimension. Word2vec is one of the typical representatives of distributed representation. Words can be mapped to a low-dimensional space, and the semantically related words can be closer in space. Zadeh et al. (2017) employed the general word vector with 300 dimensions (300-d) to perform textual sentiment analysis. Different from their work, we train the word2vec model on a large-scale domain corpus, from public emergencies in social platforms, and the domain-representative embeddings rich in context semantics can be produced.
Word2vec model contains Continuous Bag of Words (CBOW) model and Skip-Gram model. Given the context semantic units, the CBOW model can predict the conditional probability of middle words through unsupervised learning. Skip-gram is a kind of word2vec model and wildly used. Basically, given the center word vc, Skip-Gram model can predict the probability of context words vo through optimizing the object function J(θ) constantly, where θ represents the parameters needed to be optimized. In this study, we employ the Skip-Gram model to train word embeddings on a large public emergency corpus, obtaining word vectors rich of syntax and semantics information.
The choice of classification model also counts. LSTM, as an extension of Recurrent Neural Network (RNN), can effectively overcome the flaws of RNN such as the gradient explosion and vanishment through controlling the unique gate structure, combining long and short memory in the training process. LSTM contains 3 gates and a cell state. The gates are the forgetting gate, input gate and output gate. Forgetting gate control historical cell state. The output gate determines the output ht of the next state. The equations are as follows. wf, wi, wc represent weight matrices, ht-1 is cell state, bf, bi, bc are bias matrices and σ is sigmoid function. ⊙ is vector dot product
ft=σ(wf∙[ht-1, xt]+bf)
it=σ(wi∙[ht-1, xt]+bi)
$\tilde{C}_t=tanh(w_c\cdot[h_{t-1},x_t]+b_c)t$
$C_t=f_t\odot f_{t-1}+i_t\odot\tilde{C}_t$
$o_t=\sigma(w_o\cdot[h_{t-1},x_t]+b_0)$
$h_t=o_t\odot tanh(C_t)$
BiLSTMs are composed of forward LSTM and backward LSTM, capturing and considering the contextual information more effectively, and suitable for text classification tasks. Forward LSTM can convey sequential information by time and the backward can transfer sequential information reversely. Due to the advantages, the BiLSTM is chosen as the subject of textual sentiment analysis network. The structure of proposed network is illustrated in Figure 2 . A layer activated by Relu function with 256 units is added to the BiLSTM to obtain the encoded dense representation of texts.

Figure 2. The structure of textual sentiment analysis network |
To formally define our proposed textual sentiment analysis network (ut), $\mathrm{~let}\mathit{\leftarrow}\{t_1, \\ t_2,\ldots,t_m,\ldots,t_n;t_m\in\mathbb{R}^{100}\}$, where tm is the word in the public emergency text represented by word2vec. The length of text is set to 50. Then, t is used as the input of network ut to generate the textual sentiment embedding Vt in equation (7). Wt is the set of all weights in network ut.
$V^t=u_t(t;W_t)\in\mathbb{R}^{256}$
3.2 Visual sentiment analysis
CNN has achieved great success in computer vision and is applied to visual sentiment analysis tasks. The network can learn the distinguished and complex features after several epochs of training.
Usually, a deep CNN model contains a large number of parameters to be learned. To train these parameters, large-scale image datasets are needed. However, it’s difficult to collect large-scale datasets with accurate annotations in image sentiment classification (Campos et al., 2017). Additionally, it costs too much time and resources to train a deep neural network from scratch. Employing transfer learning techniques is a way to solve problems. Transfer learning applies the learned knowledge to the actual dataset (Pan & Yang, 2010) through performing representation learning on different but related large-scale datasets. In deep learning, transferring the parameters and weights in a pretrained deep neural network is feasible, and fine-tuning strategy can improve the performance of target domain models. Take the pretrained weights on different large-scale datasets as initial weights of the network, and then modify the output of the last fully-connected layer based on the specific task. To take advantage of complementary information in images, we explore fine-tuning strategies, starting from the convolutional neural network layers in the bottom to make the model reach the optimal and avoid overfitting.
VGG-16 pretrained on ImageNet is used as the base model. Then we modify the base model as the visual sentiment analysis network, shown in Figure 3 . The last fully-connected layers of VGG16 are removed. A fully-connected layer with 256 neurons, activated by Relu, is added. The weights of newly added layers are all initialized randomly.

Figure 3. The structure of Visual sentiment analysis network |
To formally define our proposed visual sentiment analysis network uv, let v represent the image attached to the text, and the shape is 224×224×3 read and resized by CV2. v is employed as input of network uv to generate the dense visual sentiment embedding Vi in equation (8). Wv is the set of all weights in network uv.
$V^i=u_\nu(\nu;W_\nu)\in\mathbb{R}^{256}$
3.3 Multimodal sentiment analysis
One of the keys in multimodal sentiment analysis is the fusion of features extracted from different modalities (Brousmiche et al., 2022; Ghorbanali et al., 2022). After employing different unimodal sentiment analysis networks to generate corresponding modal embeddings, an intermediate fusion technique is adopted to combine public emergency textual and visual sentimental embeddings, shown in Figure 4 .
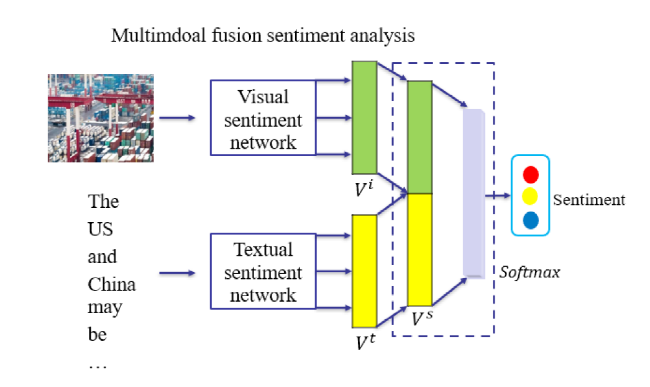
Figure 4. The structure of multimodal sentiment analysis |
Vt and Vi, textual and visual sentimental embeddings, are fused in a form a concatenation to generate multimodal features Vs in equation (9). ⊕ represents the concatenation of unimodal embeddings. Though this method is trivial, it still performs well.
Vs= Vt ⊕ Vi
Finally, Vs is the fused multimodal features and fed into a softmax layer to obtain the sentiment probability P in equation (3.10). The parameters of the fully-connected layer are represented by Ws.
P=fs(Vs; Ws)
4 Experiments and results analysis
In this section, a set of experiments are conducted to analyze the effectiveness of DMFM. The proposed model is tested on real-world datasets from Sina and Twitter microblog platforms, and the detailed performances are presented.
4.1 Datasets
4.1.1 Weibo dataset (Chinese)
(1) Acquisition of the dataset
Due to the lack of public multimodal datasets about public emergencies, we collected the text-image pairs from Sina Weibo in the past two years. The dataset includes recent public emergencies such as “Xiangshui Chemical Plant Explosion”, “Chongqing Bus Falling River”, and “Typhoon Mangosteen”. In Table 2 , we give a sample of the Chinese dataset. The collected dataset contains 2,128 texts and images respectively. Additionally, we still crawled the texts of the past few years’ public emergencies texts for training word vectors. The filtered number of texts for training word vectors is 2,911,235.
Table 2. An instance of Weibo dataset |
| Images | Texts (translated) |
|---|---|
 | Bauhinia in front of the window: “Typhoon Mangosteen” violently cracked its spine, but still couldn’t hide its charm |
(2) Weibo dataset preprocessing
Before the experiments, we conducted the preprocessing on the dataset. Weibo texts often contain emojis, rich of emotions and the distinguished emotional features. We also removed some meaningless symbols such as “@”, “#”, etc. Additionally, we used the jieba package in python to conduct word segmentation operation and then HIT stop words dictionary to remove the stop words in texts. For images, we employed CV2 package to read the images and resize them into 224×224×3.
(3) Sentiment annotation of Weibo dataset
We conducted a 3-person annotation strategy. The dataset was labeled by three third-year undergraduates majoring in information management and information system. They had more than three years of experience in using social media. The process of annotation followed the emotional model Plutchnik’s Wheel of Emotions (Plutchnik, 1983). We performed two rounds of consistency of assessment. The labeled sentiments are positive, neutral and negative. The first round of annotation was used to evaluate the quality of annotation. The results of 3-person consistency and 2-person consistency are shown in Table 3 . It can be found that there are still 125 data that fail to reach a consistent result in the annotation.
Table 3. The first-round annotation results of Weibo dataset |
| 2-person consistency | 3-person consistency |
|---|---|
| 2003 | 1905 |
In the second-round annotation, the annotated students exchanged their views and opinions and unified their views. For inconsistent labeling results, the emotional labels were determined by voting. The final sentiment annotation consequences are presented in Table 4 .
Table 4. The final annotation results of Weibo dataset |
| Positive | Neutral | Negative |
|---|---|---|
| 712 | 768 | 649 |
4.1.2 Twitter dataset (English)
(1) Acquisition of the dataset
We use “tradewar”, “Brexit” and “yellowvest” as query keywords with twitterscraper crawling related online public opinion data, producing json documents. The language was set to English. However, twitterscraper can only crawl the texts (2019 version). We modify the code to make it crawl corresponding images. In all, we crawled 9,586 texts and images respectively. The number of “brexit” is 3,173, that of “tradewar” is 3,200 and that of “yellowvest” is 3,213. Additionally, we crawl the public emergency texts, happening in the latest years such as “Boston bombings”, “Starbucks racism incidents” etc. The total number is 4,728,723.
(2) Twitter dataset preprocessing
Firstly, we performed a preliminary screening of the crawled dataset. Meaningless texts, only containing URLs or links, are removed. After filtration, 3,744 texts and corresponding images were reserved. In preprocessing of texts, we used the word_tokenize method in NLTK to segment the texts, and then removed the stop words in the sentence and restore the morphology. We used CV2 to read the images and resized the images to 224×224×3 to adjust the input of the proposed model. Table 5 presents a sample of the dataset.
Table 5. An example of Twitter dataset |
| Images | Texts |
|---|---|
 | The US and China may be nearing a trade deal. That won’t stop the global economic slowdown |
(3) Sentiment annotation of Twitter dataset
The annotation process of the Twitter dataset is consistent with that of the Weibo dataset, with two rounds of 3-person annotation. The results of the first-round annotation are shown in Table 6 .
Table 6. The first-round annotation results of Twitter dataset |
| 2-person consistency | 3-person consistency |
|---|---|
| 2,961 | 2,703 |
In the second round of annotation, 3 annotators decided on the final sentiment labels after discussion and voting. The final annotation results are shown in Table 7 .
Table 7. The final annotation results of Twitter dataset |
| Positive | Neutral | Negative |
|---|---|---|
| 1,406 | 1,148 | 1,190 |
To exclude the impact of any other elements on the experiments, the training dataset and testing dataset employed by each model are the same in experiments. The training dataset is 80% of the dataset and the remaining 20% is the testing dataset.
4.2 Model settings
(1) Textual sentiment analysis model (TSAM) setting
A softmax layer is added to textual sentiment analysis network, constructed as TSAM. The word2vec model is trained on 2,911,235 crawled public emergency texts. The key parameters of the Skip-Gram model include window, min_count and size. Window represents the longest distance between current word and predicted word and is set to 5; min_count, filtering the words whose occurring frequency is less than that, set to 3; size is the dimension of the word vector and set to 100. The length of is single text is set to 50. If the length exceeds the threshold, it will be truncated. If the length is less than the threshold, 0 will be added.
The number of units in BiLSTMs is set to 256. The dropout technique is employed to avoid overfitting and set to 0.5. The loss function is cross-entropy. The optimizer is adam and the learning rate is set to 0.001. The batch-size is set to 128 and training epochs are set to 100. Earlystoppping technique is employed for model training. When the loss does not decrease for 10 consecutive epochs, the training process stops.
(2) Visual sentiment analysis model (VSAM) setting
A softmax layer is added to visual sentiment analysis network, constructed as VSAM. The optimizer of the model is Stochastic Gradient Descent (SGD). The learning rate is 0.001 and the momentum is 0.9. The batch size is 128 and the training epochs is 100. The earlystoppping is employed, the same with the afore-mentioned. In the process of fine-tuning, we explore to release the convolutional layers at the back of VGG16, fully excavating the sentimental information in images.
(3) Deep multimodal fusion model setting
Deep multimodal fusion model consists of textual sentiment analysis network ul, visual sentiment analysis network uv and multimodal fusion technique. The extracted features from different modalities are concatenated to produce a 512-d long vector, fed into fully-connected layers to perform sentiment analysis. The whole training process is in a manner of end to end. The optimizer is adam and the learning rate is 0.001. The parameters of training epoch, cross-entropy, early-stopping and batch-size are the same as afore-mentioned.
(4) Experimental environment and evaluated metrics
The coding language for experiments is Python 3.6. The framework of deep learning is keras 2.2.5, the version of tensorflow is 1.11.0 and the package for SVM is scikit-learn 0.20.0. All experiments are conducted on a server with 16G memory and processors of Intel E5-2609. The evaluated metrics of experiments are macro precision (P), macro recall (R) and macro F1-score (F1).
4.3 Baseline models
TSAM. This method integrates a softmax layer and the proposed textual sentiment analysis network. The softmax layer is employed to perform classification.
VSAM. This method unifies a softmax layer and the proposed visual sentiment analysis network. In the process of fine-tuning, we try releasing the layer after conv11, conv12 and conv13 layers respectively in Figure 3 . The different fine-tuning models are named Conv11, Conv12 and Conv13 respectively.
SVM-T (Moraes et al., 2013). The input of SVM is the same as BiLSTMs. The kernel function used is a linear function, and C value is set to 1.0.
BERT-T (Devlin et al., 2019). BERT is a superior pretrained language model. We employ Google’s open-source pretrained BERT Chinese model to obtain textual representation. [CLS] feature in the extracted textual features is used as the representation of the text. The dimension is 768. The parameter setting of the BiLSTMs is the same as the textual sentiment analysis model.
Un-finetuned CNNs (Simonyan & Zisserman, 2015). The newly added softmax layer of visual sentiment analysis model is engaged in the training and other layers are frozen, termed UFT. The parameter setting of UFT is the same with visual sentiment analysis model.
Feature-level fusion model (Pérez Rosas et al., 2013). A SVM model is performed to classify the sentiment of the vectors combining of textual and visual features.
Decision-level fusion model (Poria et al., 2016). The proposed textual and visual sentiment analysis models are employed to extract the features from softmax layer respectively, fused by the rule to produce the predicted label.
4.4 Experimental results analysis and discussion
In this section, we will examine the performance of DMFM and compare it with the baseline models based on the Sina Weibo public emergency dataset. In this process, we will validate the superiority of multimodal fusion and contrast the influence different modal fusion techniques bring. In Twitter public emergency dataset, we will test the superiority of multimodal fusion again.
4.4.1 Results analysis and discussion (Weibo)
(1) Textual modality
The results of different textual sentiment analysis models are shown in Table 8 . We can find that the performance of TSAM is superior to SVM-T, which means that with the same textual representation, TSAM is more suitable for public emergency texts analysis than SVM-T in the aspect of classifying the sentiments of online users. It also validates the merit of BiLSTMs in handling sequential data. Furthermore, with the same classification model BiLSTMs, the performance of BERT-T is inferior to word2vec trained in large-scale domain public emergency texts.
Table 8. The results of different textual sentiment analysis models |
| Model | P(%) | R(%) | F1(%) |
|---|---|---|---|
| SVM-T | 78.107 | 77.494 | 77.465 |
| TSAM | 82.760 | 82.864 | 82.750 |
| BERT-T | 81.333 | 81.153 | 81.227 |
In summary, we can conclude some findings from the results. Firstly, deep sequential model TSAM obtains better performance than the traditional machine learning model SVM-T in textual sentiment analysis. This proves the suitability of TSAM in handling public emergency texts and the superiority of proposed textual sentiment analysis network. Secondly, though BERT dominates several NLP tasks, the word2vec model pretrained on the large-scale public emergency corpus performs well containing more contextual semantics.
(2) Visual modality
The results of visual sentiment analysis are shown in Table 9 . It can be discovered that models employing fine-tuning strategy are significantly better than the model without a fine-tuning strategy, which means the performance of the model is influenced by the fine-tuning technique. When releasing the layer after conv12 (including conv12) engaging in the training of the model, F1 value is increased by 3.601% compared to Conv13. When releasing the layer after Conv11 (including conv11), Conv11 is inferior to Conv12 but superior to Conv13. Overall, when more convolutional layers are engaged in the model training, compared to the un-finetuning model, the performances of fine-tuning models are better and Conv12 performs best. Therefore, we choose releasing the layer after conv12 (including conv12) as our fine-tuning strategy, which is applied to VSM model and visual sentiment network uv.
Table 9. The results of different visual sentiment analysis models |
| Model | P(%) | R(%) | F1(%) |
|---|---|---|---|
| UFT | 57.051 | 57.042 | 56.357 |
| Conv11 | 58.906 | 58.227 | 58.228 |
| Conv12 | 61.507 | 61.502 | 61.226 |
| Conv13 | 57.861 | 57.512 | 57.625 |
According to the results of visual sentiment analysis, when different fine-tuning strategies are employed, the performances of models are different. Usually, the learned features of the front convolutional layers in the deep CNN model are low-level and the features extracted from the convolutional layers at the back of the model are more of visual semantics. However, we find that only releasing the layers after conv13 (including conv13) can’t achieve a good result, but evaluation metrics are significantly improved when releasing the layers after conv11 (including conv11) and conv12 (including conv12). The fine-tuning technique can boost the performance of pretrained model but it is an experimental and empirical method that needs to be verified. In our experiments, releasing the conv12 layer (including conv12) is the best choice. In order to explore the learning process of the model, we visualize the outputs of Conv12, as shown in Figure 5 . It can be seen that after layer-by-layer learning, the regions of interest in the model have also changed, from the root of the tree to the overall outline of the tree.

Figure 5. Visualization of outputs of the Conv12 model |
(3) Multimodal fusion
The results of multimodal fusion are shown in Table 10 . It can be found that the F1 value of DMFM is higher than feature-level fusion and decision-level fusion by 6.385% and 1.945%, showing intermediate fusion is superior and our proposed model performs the best.
Table 10. The results of different multimodal sentiment analysis models |
| Model | P(%) | R(%) | F1(%) |
|---|---|---|---|
| Feature-level fusion | 79.903 | 79.288 | 79.496 |
| DMFM | 85.865 | 85.915 | 85.881 |
| Decision-level fusion | 84.010 | 83.960 | 83.936 |
Combining the results of textual and visual sentiment analysis, it can be seen that the performance of textual modality is better than visual modality. It shows that during public emergencies, textual modality expressed by online users is rich of more sentiment and easily to be recognized by the model. Furthermore, due to the semantic gap between the visual modality and human emotions, the visual sentiment analysis models are unable to perform as well as textual sentiment analysis. Especially, during public emergencies, the sentiments of images expressed by online users sometimes are ambiguous and need to be determined by corresponding texts, which is also the reason why they perform badly. Although the performance of visual sentiment analysis is unsatisfactory, it can be seen in Figure 6 that after fusing the visual modality, the performances of multimodal fusion are superior to unimodality. It shows that during public emergencies, combining the texts and images posted by online users can boost the overall performance of the model and our proposed model performs best compared with baseline models.
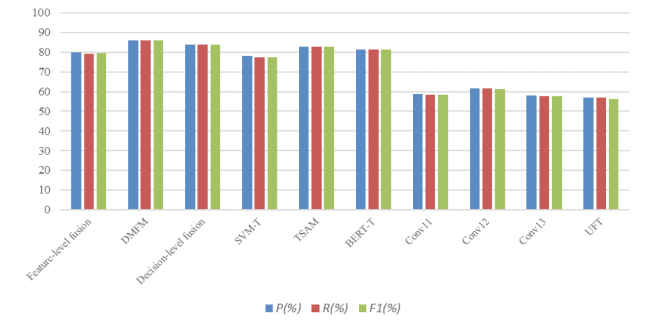
Figure 6. The overall results |
(4) Further analysis
Here, we analyze performances of applying different fine-tuning networks in multimodal fusion model. We name the combination of Conv11 and TSAM as DMFM_Conv11, and the combination of Conv13 and TSAM as DMFM_Conv13. The parameter settings are the same as DMFM. The sentiment analysis results of DMFM_Conv11 and DMFM_Conv13 are shown in Table 11 . We can discover that DMFM still performs best and DMFM_Conv11 is superior to DMFM_Conv13, the trend of which is consistent with the results of visual sentiment analysis. It shows that the improvement of unimodal sentiment analysis can boost the overall performance of multimodal fusion sentiment analysis, which also points the way for further enhancement of the proposed model. Additionally, it indicates that the better fine-tuning strategy can deeply excavate the sentimental and visual semantics information in images.
Table 11. The results of DMFM_conv11, DMFM and DMFM_conv13 |
| Model | P(%) | R(%) | F1(%) |
|---|---|---|---|
| DMFM_conv11 | 84.701 | 84.742 | 84.695 |
| DMFM | 85.865 | 85.915 | 85.881 |
| DMFM_conv13 | 84.266 | 84.272 | 84.118 |
In decision-level fusion, the fusion rule (Poria et al., 2016) is adopted, shown in equation (13).
l’=argmax(q1ot+q2oi)
ot, oi are the outputs of softmax layers in textual and visual sentiment analysis models respectively. q1 and q2 represent the weight of textual and visual modality respectively and l’ is the final label. In that rule, the weights of textual modality and visual modality are the same, which means the sentimental information they bring is equivalent. However, in our experiments, the performance of textual modality is superior to the visual modality, showing the clue that the weights may not be equivalent. Based on that, we modify the fusion rule, and make the following constraints: q1+q2=1, q1∈{0.1,0.2,0.3,…,0.9}, q2∈{0.1,0.2,0.3,…,0.9}. We use the new dynamic fusion rule to conduct decision-level fusion. The results are illustrated in Figure 7 . When q1=0.6 and q2=0.4, the decision level fusion can reach the best performance and the F1 value is 85.431%. It shows that in decision-level fusion, the sentimental information contributed by different modalities is not the same. In our experiments, the weight of textual modality is higher than that of visual modality, which means during public emergencies, texts posted by online users contain more sentimental information than images attached to texts. The finding echoes with the result that the performance of textual sentiment analysis is superior to that of visual sentiment analysis (Poria et al., 2017). However, the optimal decision-level fusion result is still inferior to our proposed model.
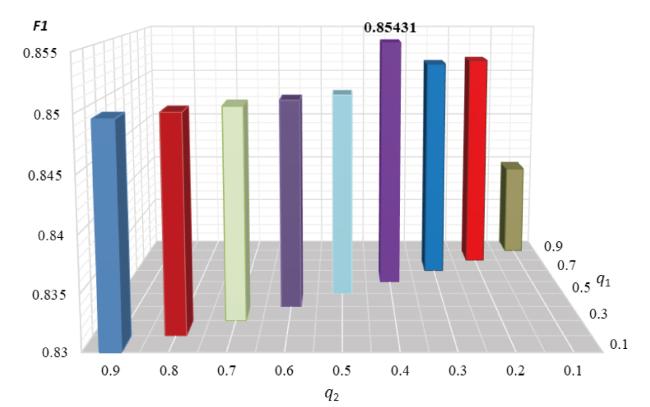
Figure 7. The results of employing different weights in decision-level fusion rule |
In summary, we compare the proposed Deep Multimodal Fusion Model (DMFM) with the baseline models and contrast the performances of different fusion techniques. We obtain the best-performed fine-tuning strategy through experiments and visualize the outputs of Conv12 to explore the learning process of the visual model. In addition, we analyze the problem of whether the improvement of the unimodal model can boost the overall performance of the multimodal fusion model, and give our findings through experiments. Also, we modify the fusion rule and allocate the weights for textual and visual modality dynamically and experiments show that the weight of textual modality is higher than, not equal to, that of visual modality.
4.4.2 Validation analysis of Twitter dataset
In order to test the performance of DMFM furtherly and verify the superiority of multimodal fusion during public emergencies, the Twitter public emergency dataset is employed. The results are shown in Table 12 . It can be seen that DMFM still performs well, showing that DMFM is robust in Twitter dataset. In comparison with the unimodality, the results of multimodal fusion are still better than unimodality, which exhibits that the fusion of textual and visual information can bring the boost of the performance of the sentiment analysis model during public emergencies.
Table 12. The results of Twitter public emergency dataset, where T represents text and V represents image. |
| Model | P(%) | R(%) | F1(%) |
|---|---|---|---|
| T | 83.407 | 83.482 | 83.386 |
| V | 62.336 | 61.867 | 60.934 |
| T+V | 86.463 | 86.400 | 86.401 |
At the same time, we visualize the training process, shown in Figure 8 . It can be found that with the increase of training epochs, the loss value is decreasing gradually and becomes stable and fitting.
Figure 8. The loss curve of model training |
Furthermore, in a specific public emergency, whether the performance of multimodal fusion is still superior to unimodality? Based on that, we conduct the analysis. It can be seen from Figure 9 that no matter in “Brexit”, “Tradewar” and “Yellowvest” public emergencies, the performance of multimodal fusion is still better than unimodality, showing in public emergencies multimodal fusion sentiment analysis can bring better results and adapt the current sentiment analysis changes.
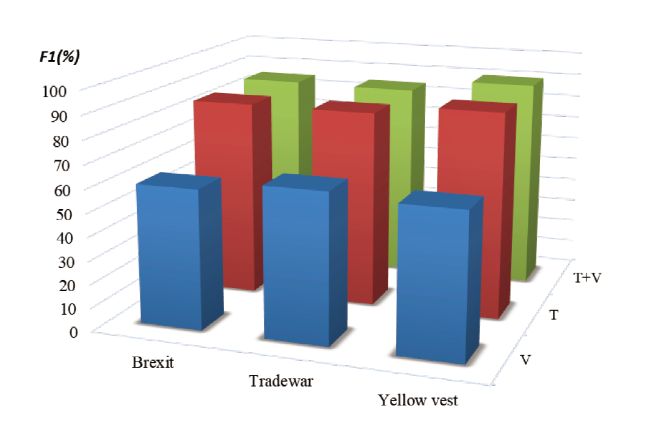
Figure 9. The results of different modalities in Twitter dataset. T is the text and V is the image. |
To explore the performance of DMFM in different public emergencies, we perform the test. The results are shown in Figure 10 . It can be found that in different public emergencies, DMFM still performs well and F1 value is higher than 90% in “Yellowvest”.
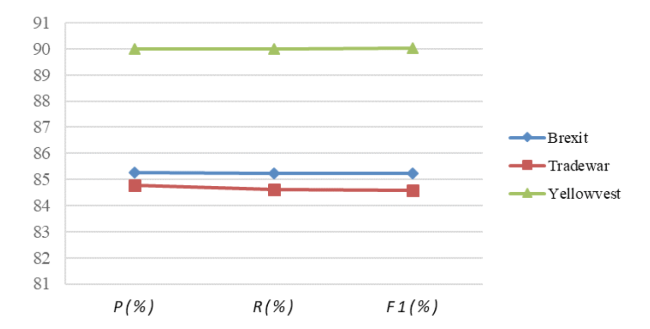
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 10. The results in different Twitter public emergencies |
4.5 Theoretical and practical implication
4.5.1 Theoretical implication
In a long term, the research about sentiment analysis in public emergencies is text-centric (Smith et al., 2018; Wu et al., 2020). However, the performance can not satisfy the need for high accuracy and need to be boosted desperately. The multimodal content generated by online users on SMPs brings the opportunity. Thus, we consider the sentiment analysis during public emergencies from the angle of multimodal fusion through combining the information in texts and images.
4.5.2 Practical implication
In this paper, for the limits of sentiment analysis during public emergencies, we propose a novel multimodal fusion sentiment analysis model, unifying texts and images, to excavate the sentiment in texts and images. Different from their work (Campos et al., 2017; Poria et al., 2016), we enhance the word representation for the specific task and utilize the information in images deeply. Our practical implication can be summarized as follows. Firstly, we design a novel deep multimodal sentiment analysis model for social media text-image contents during public emergencies, providing support for government decisions. Secondly, we conduct the detailed analysis of the proposed model and find the ways to boost the performance. Lastly, the proposed model is not only tested in Sina Weibo public emergency dataset, but also tested in Twitter public emergency dataset.
5 Conclusions and future work
In this paper, we aim to address the lack of multimodal sentiment analysis for social media content during public emergencies. Therefore, we propose the DMFM to analyze the sentiment of online users by combining the texts and images on the SMPs from a novel perspective. In textual sentiment analysis, we compare the TSAM with baseline models and find the suitability of BiLSTM in handling public emergency texts and the merit of Word2vec trained on a large-scale public emergency corpus. In visual sentiment analysis, we find the advantage of fine-tuning techniques and explore the best-performed fine-tuning strategy empirically. In multimodal fusion, we compare the proposed model with baseline models, including textual and visual sentiment analysis models. Experimental results show that our model is effective. Also, in the further analysis, we find that the improvement of unimodal sentiment analysis can boost the overall performance of the multimodal fusion sentiment analysis, which exhibits the way for further enhancement of the proposed model. In decision-level fusion, we modify the fusion rule and discover that the weight of textual modality is higher than that of visual modality. Lastly, we employ the DMFM on the Twitter public emergency dataset. Experiments show that our proposed model still has higher accuracy results. This model also can provide more comprehensive support for the government decision-making systems when the public emergency occurs.
However, our paper contains the following limitations and needs further improvement in future works. Technically, when online users post some images during public emergencies, there are multiple images. Therefore, all images attached to the text should be considered to build a more complete model during the sentiment analysis. In future visual sentiment analysis work, deeper pretrained models could be proposed for achieving higher accuracy. Moreover, the attention mechanism between unimodality and multimodality can be added for further improvement. In multimodal fusion, the DMFM employs the concatenation fusion of the textual and visual features, which may ignore the correlation between different modalities. It needs to be improved in future work. More latest baseline models in sentiment analysis need to be added to make the comparison. In addition, constructing a model with multi-task learning has been a trend, which is expected to recognize the sentiment and emotion from the multimodal contents simultaneously (Majumder et al., 2019). This will be also one of our research directions.
Funding information
This paper is supported by the National Natural Science Foundation of China under contract No. 71774084, 72274096 and the National Social Science Fund of China under contract No. 16ZDA224, 17ZDA291.
Author contributions
Tao Fan (fantao@smail.nju.edu.cn): Conceptualization (Lead), Formal analysis (Lead), Methodology (Lead), Writing - original draft (Lead), Writing - review & editing (Lead); Hao Wang (ywhaowang@nju.edu.cn): Writing - review & editing (Equal); Peng Wu (wupeng@njust.edu.cn): Conceptualization (Supporting), Funding acquisition (Lead), Methodology (Supporting), Supervision (Supporting), Writing - review & editing (Equal); Chen Ling (lingchen@njust.edu.cn): Writing - review & editing (Supporting); Milad Taleby Ahvanooey (M.taleby@nju.edu.cn): Writing - review & editing (Supporting).