

1 Introduction
Scientific research starts with problems, which drive and guide research (Li et al., 2023). Identifying major scientific and technological problems has become a practical need for countries and industries in innovation activities, which plays a positive role in leading researchers to better grasp the direction of innovation breakthroughs, overcome core technologies, and promote technological innovation (Yi et al., 2023). With the continuous exploration and cognition of science by human beings, the problems of scientific research have become more and more complex, and it is difficult for a single discipline to solve them, so it is necessary to cross and integrate multiple disciplines to find better solutions. Therefore, multidisciplinary research has emerged as a significant and new paradigm in academic research, serving as a catalyst for scientific innovation. It is vital for governments and research institutions to identify key multidisciplinary problems and formulate appropriate policies to fund projects with complex multidisciplinary problems. It is also necessary for researchers to borrow ideas from multiple disciplines. However, the current identification of multidisciplinary problems mainly relies on experts, which is inefficient, time-consuming, costly, and subjective and is not conducive to a comprehensive understanding of the research dynamics of certain multidisciplinary problems.
Multidisciplinary research is essentially a collaborative process that integrates knowledge from multiple disciplines around research problems (National Academy of Sciences et al., 2005). Multidisciplinary and interdisciplinary seem to be interchangeable because their definitions are vague and similar. However, these approaches have subtle differences. Generally, multidisciplinary studies, which may include non-academic participants, involve several different academic disciplines researching one theme or problem without integration, while interdisciplinary studies involve several unrelated academic disciplines that cross the subject boundaries to create new knowledge and theory (Durgun, 2017). The main differences between the approach concepts are the intensity of cooperation and integration of disciplines and the involvement of non-academic fields. Therefore, in this study, interdisciplinary is considered similar to multidisciplinary at the problem level.
For multidisciplinary researchers and research management authorities, modern literature databases bring convenience to their multidisciplinary research. To find solutions to multidisciplinary problems, researchers need to understand the knowledge of relevant disciplines, and research management needs to select key multidisciplinary problems and gather experts from different disciplines. However, current literature services and intelligence research cannot meet this demand well. One reason is that existing literature databases typically only allow the retrieval of papers based on topics or keywords, without displaying specific research problems. Another reason is that existing multidisciplinary/interdisciplinary intelligence research is still at the document level (Huang et al., 2023) or topic level (Zeng et al., 2023), without paying attention to problem granularity, and cannot establish a connection between disciplines and research problems.
Information extraction is the mainstream method exploited to extract problems from the abstract text of papers. This technique first employs persons to create a training set of sequence annotations and then establishes an information extraction model based on machine learning algorithms such as HMM (Lee & Mao, 2004) and CRF+BiLSTM (Chang et al., 2023). Afterwards, the model is used to extract problems from unstructured text. Although the method has achieved good performance, it relies on heavy manual work and time consumption, and models trained in one field are difficult to apply to another domain. In addition, when encountering rules that do not involve sequence annotation or when the problem phrases do not explicitly appear in the text, this method cannot correctly identify the problems.
The emerging generative language models in recent years, such as T5, Bart, Bert, and GPT, provide new feasible solutions for identifying problems as alternative information extraction techniques. This method refers to problem identification as the process of generating text, that is, using unstructured text data to generate text that represents the research problem in the paper. However, this method has not yet been thoroughly studied. A related study utilized the format of “A based on B” in paper titles, extracting A as the problem and B as the method (Cheng et al., 2021). Inspired by the ideas in these studies, a method for identifying multidisciplinary research problems based on text generation is presented, where the problem identification task is transformed into an abstractive title generation task, and then the identified problems are determined whether they are multidisciplinary according to the disciplinary labels of the papers.
2 Related works
Multidisciplinary research problems involve multiple disciplinary fields and require the application of knowledge, methods, and skills from different disciplines. Different disciplines tend to study an aspect of it from their own disciplinary perspectives. Currently, multidisciplinary research is primarily conducted at the level of documents (He et al., 2022) or topics (Wang et al., 2023), with only a limited amount of research delving into the granularity of research problems. However, even in these limited studies, identifying research problems is not considered the final research objective. Instead, it is viewed as a crucial step in the process of multidisciplinary knowledge discovery (Dong et al., 2018). How to realize the identification of multidisciplinary research problems has yet to be thoroughly explored by researchers.
The current methods for identifying research problems can be classified into two categories: information extraction based method and text generation based method. The information extraction based method is the current mainstream approach, which extracts phrases, words, or sentences from the original text of papers that represent research problems. These can be divided into four types: manual annotation, rule matching, machine learning, and hybrid methods. The manual annotation method typically involves professionals in the relevant field pre-defining labeling rules and then manually applying those rules to label the data (Chu & Ke, 2017; Howison & Bullard, 2015). The rule matching method also requires manual definition of rules beforehand, and then uses the machine to match the problems and methods in papers according to the rule template (Gupta & Manning, 2011). Machine learning is the mainstream method at present, which employs deep learning or traditional machine learning technology to extract problems. It can use the existing network model (Gabor et al., 2018), joint training optimized model (Luan et al., 2018), improved embedding layer (Färber et al., 2021), feature learning layer (Luan et al., 2017), sequence labeling method (Tateisi et al., 2013), or text classification method (Heffernan & Teufel, 2018) to extract research problems. The hybrid method combines rule matching methods and neural network methods to construct a recognition model for identifying research problems (Tuarob et al., 2016). Some studies have also introduced features such as part-of-speech, word shape, and noun-bigrams to optimize recognition performance (Houncbo & Mercer, 2012).
The text generation based method has emerged in recent years. Text generation is based on technologies such as natural language processing, machine learning, and deep learning, which enable the learning of language rules through training models to automatically generate text that meets grammatical and semantic requirements (Čeović et al., 2023; Li et al., 2024). Core text generation applications include text summarization, question-answer generation, story generation, machine translation, dialogue response generation, paraphrase generation, and image/video captioning (Goyal et al., 2023). Unlike the information extraction based methods that extract research problems from the original text of papers, the text generation based methods generate an abstractive representation of research problems based on their understanding of the meaning of the paper text, transforming the complex task of problem identification into a text generation task (Cheng et al., 2021). This approach argues that the research problem of a paper is contained within the textual content of the paper. By establishing a mapping relationship between the original text and research problems, language generation models can automatically generate the research problem of a paper. Some studies consider that the title of a paper is, to some extent, a generalized and concise expression of the research problem of a paper. Researchers can be assisted in selecting the required papers (Carey et al., 2022) or formulating article titles (Putra & Khodra, 2017) by generating titles based on text content. For example, many papers have titles with the same pattern as “Study of research problem based on certain method.” These papers are easily accessible and abundant in literature databases, making them suitable for training a model to generate abstractive titles. Any given scientific paper can use this model to generate an abstractive title, so that its research problems can be easily obtained. When using this method, to improve performance, it is necessary to find a suitable abstractive title to represent the research problem of the paper. How to generate high qualified abstractive representations of research problems for different types of papers is an urgent problem that needs to be addressed.
3 Methods
The proposed method first identifies the research objective types and disciplinary labels of papers using a text classification technique; second, it generates abstractive titles for each paper based on abstract and research objective types using a generative pre-trained language model; third, it extracts problem phrases from generated titles according to regular expression rules; fourth, it creates problem relation networks and identifies the same problems by exploiting a weighted community detection algorithm; and finally, it identifies multidisciplinary problems based on the disciplinary labels of papers.
3.1 Basic principles for identifying multidisciplinary problems
In this study, when a problem involved multiple disciplines, it was considered a multidisciplinary problem. Therefore, identifying multidisciplinary problems can be simply divided into two stages: identifying problems in papers and determining the disciplinary labels of problems.
Regarding identifying problems in papers, a study has found that the pattern of “A based on B” in titles indicates problem (A) and method (B) (Cheng et al., 2021). This is not the only pattern that explicitly states the research problem. Therefore, if we find patterns that can indicate problems, identifying problems becomes easier.
Suo and Lai (2021) conducted research on a large number of papers and found that scientific papers can be divided into three types based on the research objectives of the problem: understanding problem (US), solving problem (SO), and exploring problem (EXP). The US type aims to answer the question “what is it?” by understanding the concept of the research object, including its nature, state, and definition. The SO type aims to answer the question “how to do it?” by exploring the application of technology or methods in specific practical problems. The EXP type aims to answer the question “why?” by investigating the rules and reasons for phenomenon. Depending on the phenomenon being investigated, it can be subdivided into five types: causal exploration (EXP-C), current state exploration (EXP-S), regularity exploration (EXP-RG), relationship exploration (EXP-RL), and similarity and difference exploration (EXP-SD).
By analyzing a large number of papers in the database, the typical patterns in abstracts and titles of each type of research objective were found, as shown in Table 1. In the experimental data, only four research objectives (US, SO, EXP-S, and EXP-RG) were found, but we believe that there may be typical patterns of abstracts and titles for other types of research objectives in other fields. Each type of research objective has a corresponding patterned title, which helps identify the research problem as “A based on B.” For example, the title pattern of “Research / analysis of the problem” in US papers clearly indicates a research problem. Patterns in titles provide signals for identifying problems. However, there are still a large number of papers without these patterns in their titles. If the titles of these papers can be rewritten as text with relative patterns, the puzzle of identifying problems will be easily solved. The good news is that the ability has been possessed by recently emerged text generation techniques based on foundational language models, such as Bert, T5, BART, ChatGLM, GPT, etc.
Table 1. Text pattern of abstracts and titles of scientific papers. |
| Research objective | Abstract features | Abstractive title |
|---|---|---|
| US | Study/investigate/test + individual object + structure/state/performance | Research/analysis of the performance/characteristics of problem |
| SO | To address/tackle + problem + based on/utilizing + method + construct/propose/build | Study of problem based on method |
| EXP-S | Summarize/review/introduce + individual object + current status/progress | The current status/overview of research on problem |
| EXP-RG | Investigate/explore/analyze/discuss + the relationship/interaction mechanism/influence + multiple objects | The impact /mechanism of the problem |
Determining the disciplinary labels of problems is the basis for judging the multidisciplinary nature of the problems. If a problem is studied in multiple disciplines, it is multidisciplinary. Generally, a paper discusses a solution to a research problem; therefore, the disciplinary classification code of a paper can be used as the disciplinary label for its problem. Owing to the division of labor in scientific research, a paper is usually considered to be from a certain discipline, which is a common situation for scientists. Of course, many multidisciplinary papers are considered to belong to multiple disciplines. In this case, we assign the primary disciplinary code (usually the first code) of the paper to the problem rather than the entire code, as the multidisciplinary nature of the paper may be reflected in the technical methods rather than the problem.
The metadata of some databases, such as Web of Science (WOS) and Scopus, provide a disciplinary classification code for each paper. In this situation, disciplinary codes can be easily used to determine the multidisciplinary nature of problems. However, such classification systems are known to have some fundamental problems and several practical limitations that may affect the results of such studies (Milojević, 2020). First, the assignment to subject categories is done at the journal level (Jesenko & Schlögl, 2021); therefore, many articles may not be mapped to relevant disciplinary codes. For example, a study on the mapping and classification of agriculture in the Web of Science found that, on average, 50% of relevant articles are published outside the scope of journals mapped to WOS agricultural categories, and the other half are mapped mostly to natural sciences, medical and health sciences, and engineering and technology fields (Bartol et al., 2016). Second, because the provided disciplinary codes may not meet practical requirements, mapping such subject categories into other classification systems is often necessary; however, the many-to-many mapping between two classification systems and multiple assignments of subject categories in Web of Science may lead to massive changes in the results (Jesenko & Schlögl, 2021). In addition, not all databases provide this service. For example, the two main Chinese literature service providers, Wanfang Data and China National Knowledge Infrastructure (CNKI), did not provide Chinese disciplinary codes but only provided CLC (Chinese Library Codes) codes. Therefore, it is usually necessary to use text classification technology to assign the required disciplinary classification codes to papers.
3.2 Overall framework
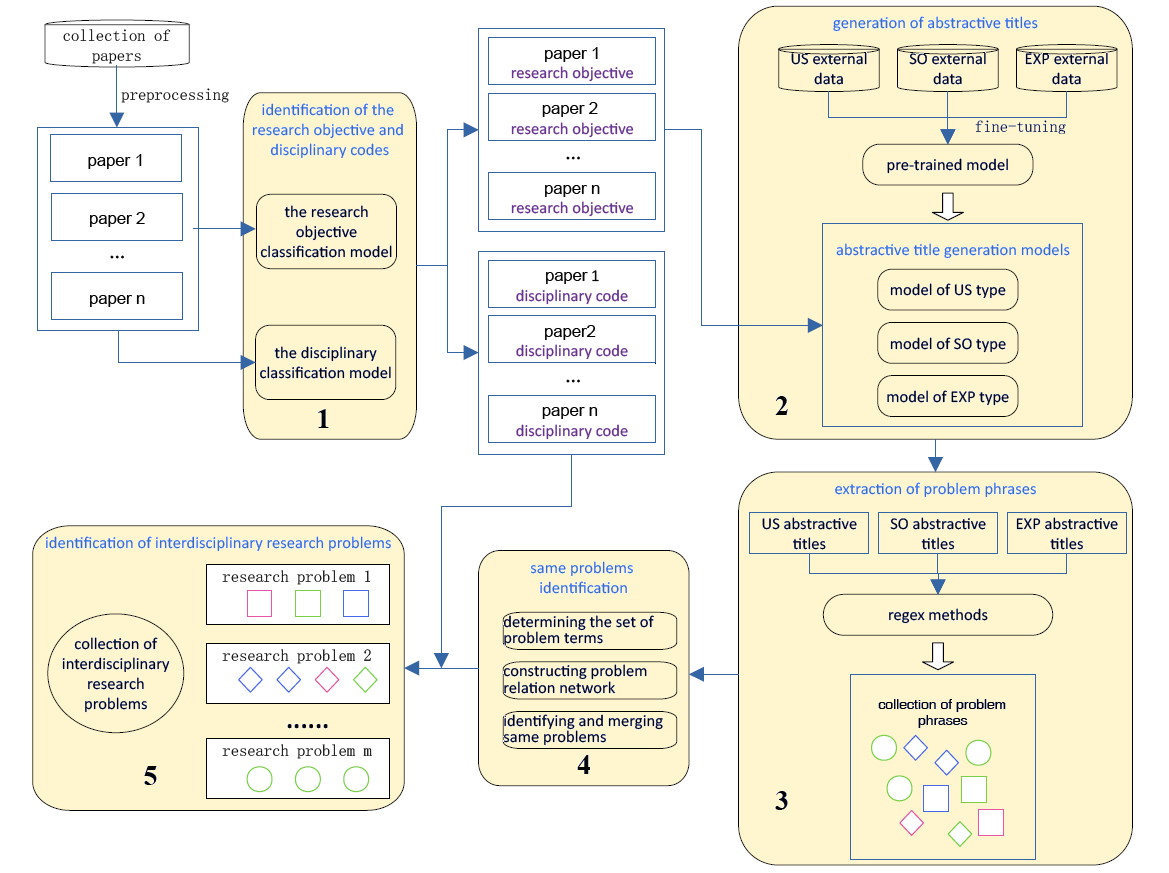
The proposed method comprises five consecutive functional modules, as shown in the overall framework in Figure 1. The first module is designed to identify the research objective types and disciplinary labels of papers using a text classification technique. Each paper is assigned a research objective label and a disciplinary code after being processed by the module. The second module was devised to generate abstractive titles for each paper based on abstract and research objective types using a generative pre-trained language model. The corresponding text generation model is selected based on the research objective type of the paper, and an abstractive title with a pattern is generated using the abstract text of the paper. The third module is designed to extract problem phrases from the generated titles according to regular expression rules. The terms in the problem phrases are extracted, and a problem relation network is created with problem phrases as nodes and the relation of common terms as edges. The fourth module is designed to identify the same problems by exploiting a weighted community detection algorithm based on a problem-relation network. The problem phrases in the same community are merged as a problem. The fifth and last modules aim to determine multidisciplinary problems based on the disciplinary label of the paper to which the problem belongs.
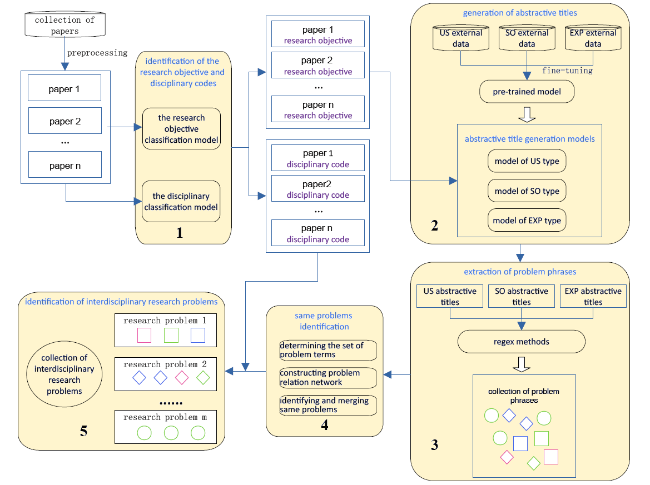
Figure 1. Flowchart of the entire process. |
3.2.1 Identifying the research objectives and disciplinary codes of papers
The module employs a text classification technique to assign a research objective label and a disciplinary code for each paper. The research objective classification model and the disciplinary classification model were created to implement the annotation of research objective types and disciplinary codes.
Research objective classification model. Because none of the databases provide the field for the research objective type for papers, this study has designed a specialized text classification model to annotate the research objectives of papers. As mentioned earlier, a paper will be classified into one of three types of research objectives: SO, US, and EXP. The research objective classification model consists of three binary classifiers, each corresponding to a type of research objective classification. Manually annotated small-scale training data were used to train binary classifiers. Many classification algorithms can be selected, such as SVM, NB, and neural networks. It is usually appropriate to select the algorithm with the best performance. These classifiers take textual data as input by combining titles, abstracts, and keywords of papers and output the probability belonging to the corresponding research objectives. The type with the highest probability is then considered as the final classification result.
Disciplinary classification model. Establishing a disciplinary classification model was optional in this study. As stated in Section 3.1, if the metadata of papers already have disciplinary classification codes that are appropriate for determining the disciplinary labels for identified problems, for example, the SCC of papers in the WOS database, then these labels can be directly utilized in the subsequent processes without the need to establish a disciplinary classification model. However, this is not always effective. In practice, different disciplinary classification systems are required. Although some studies have been conducted to convert SCC into the required classification codes (Du, 2020), they have to expend considerable manual work and face difficult choices when mapping categories between two classification systems using many-to-many mapping relationships. Therefore, it is necessary to establish an automated classification model to annotate disciplinary labels for papers. Many present text classification algorithms, such as SVM, NB, and LSTM, can be selected to create a disciplinary classification model after the training dataset is prepared. When the required classification system is simple and there are few labels, these ordinary classification algorithms can be employed to achieve the classification model; however, in reality, the situation may be more complex, and we may have to implement a slightly more complex classification model. For example, in the study, the used Chinese disciplinary classification system is hierarchical and there are 12 main disciplinary category codes, 88 first-level disciplinary codes, and 375 second-level disciplinary codes. Under a hierarchical classification system, sample data from different categories often exhibit an imbalance, which affects the effectiveness of the classification. Therefore, we adopted a text hierarchical classification method based on stacking ensemble learning (Ran et al., 2020). This method first uses a multi-label classification to determine the main disciplinary category of a paper, and then a fusion classifier corresponding to the main category is employed to determine the final classification codes based on the output of basic classifiers corresponding to the first-level disciplines.
3.2.2 Generating abstractive titles
The abstract text of a paper is usually regarded as a summary description of the paper, whereas the title is a more condensed summary description than the abstract. Therefore, generating titles based on abstract texts will be effective. There are many effective technical methods for generating abstractive text, taking the content of an article as input based on pre-trained language models, such as Bert, T5, and Bart. These techniques generate a short and concise summary that captures the salient ideas of the source text and can be employed to generate abstractive titles. A recent study used text generation technology to generate special formatted titles using abstracts known as “A based on B” (Cheng et al., 2021). From some examples provided in the study, the method could produce good results when generating text, but there were still some poor results. The reason for the poor results is likely that the study considered only one type of research objective. Owing to significant differences in the abstractive titles corresponding to the three types of research objectives (US, SO, and EXP), specialized text generation models are constructed for each type to ensure optimal output. During the process of generation, the corresponding generation models are selected based on the labels annotated by the research objective classification model.
When creating abstractive title text generation models, the pre-trained models selected must be fine-tuned to achieve good results. During the fine-tuning process, some parameters were transferred from the pre-trained models, and external paper data were used to retrain the models. The abstracts in the external data are fed into pre-trained models, and titles in the external data are expected to be generated. To obtain external data, research paper data are first retrieved from a database that matches the format of the title for each type of research objective (see Table 1 ), and then the research objective classification model is used to assign labels to all papers. Finally, papers that match the title pattern in Table 1 are selected to form the training and testing datasets. A certain number of papers are required for each research object type in the external data. For example, in the experimental dataset, there were 11,000 external data points for each type of research objective, of which 10,000 were used for model training and 1,000 were used for model testing.
3.2.3 Extracting problem phrases from abstractive titles
The abstractive titles generated by the text generation model may contain irrelevant content unrelated to the research problem. For example, in the generated abstractive title “Research on Low-Carbon Coal Blending Optimization of Thermal Power Units Based on Chaotic Particle Swarm Optimization”, “low-carbon coal blending optimization of thermal power units” is the phrase to be extracted as the research problem, which is only a part of the title. The remaining parts may include modifiers, research methods, or other words. Using the abstractive title generation models trained in the previous step, text with title patterns in Table 1 will be generated after taking the abstract as input. The purpose of this study is to extract problems; therefore, it is necessary to extract problem phrases solely based on the features analyzed in the titles.
The regular expression (regex) method was used to extract problem phrases. A regular expression is a special text string for describing a search pattern, mainly for use in pattern matching with strings or string matching. By analyzing the title features in Table 1 , it can easily be seen that the position of problem phrases in the abstractive titles of each type of research objective is relatively fixed. For example, in the title of an US type paper “Research/Analysis of the Performance/Characteristics of A”, the content following words like “performance” or “characteristics” serves as the clues of occurring problems. Based on the results of these feature analyses, it is easy to compose regex rules to extract problem phrases from the generated abstractive titles.
3.2.4 Determining same problems
The different forms of problem phrases extracted from the abstractive titles are likely to represent the same problems; therefore, using the same string as a criterion to determine the same problem will output a large number of incorrect problems. Therefore, it is essential to determine the same problem. Through an analysis of problem phrases, we found that these phrases typically contain nouns, verbs, prepositions, conjunctions, and other elements. However, nouns and verbs are often core elements that truly reflect the research problem. For example, in the problem phrase “preparation and catalytic oxidation of porous nanocatalysts for carbon monoxide,” the elements that truly reflect the research problem are the noun “preparation,” “oxidation,” “porous,” “nano,” “oxidation,” and “carbon monoxide.” These elements are called problem terms in this study. The combination of these terms can concisely describe the research problem in a paper. Generally, if the two problem phrases have the same terms, even if their textual descriptions are slightly different, they are likely the same problem. In another case, the two problem phrases share some common terms; although they are not exactly the same, they may be the same problem or different aspects of a problem, which is common in multidisciplinary research problems. Therefore, a process with three stages (Figure 2 ) is proposed to determine and merge the same problems. The first stage is to determine which terms can become problem terms, the second stage is to construct problem relation network based on common terms relationships between problems phrases, and the third stage is to identify same problems by using community detection algorithm.
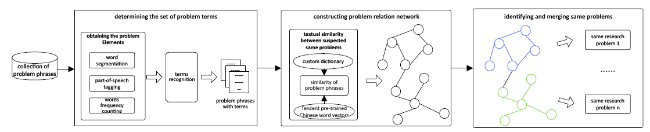
Figure 2. Process of identifying the same problems. |
(1) Determining the set of problem terms
In addition to the requirements for nouns and verbs, we hope to select important terms as problem terms rather than all nouns and verbs. First, all problem phrases are processed through word segmentation, part-of-speech tagging, and word frequency counting. Terms with a word frequency greater than five are selected as problem terms, where threshold five is an empirical parameter. The threshold can vary depending on the actual situation. The main methods for determining thresholds include statistical analysis based on historical data, subjective judgments based on expert opinions, goal setting based on experiments or business needs, and dynamic adjustments based on monitoring and feedback. In research, it is difficult to determine the threshold using quantitative analysis; therefore, we determined the threshold through discussion based on exploratory analysis. Terms with frequency below the threshold are removed because they are considered unimportant to research problems, and terms which do not contribute to the description of research problems, such as “performance,” “technology,” “application” and other generic terms are also removed even if their word frequency exceeds the threshold. Subsequently, all problem phrases are rewritten using the selected problem terms to facilitate the creation of the problem relation network. For example, “preparation and catalytic oxidation of porous nano catalysts for carbon monoxide” would be represented as “oxidation, porous, nano, catalysts, carbon monoxide.”
(2) Constructing problem relation network
In this step, the problem relation network is constructed with the identified problem phrases as nodes, the relationships of sharing common terms between problem phrases as edges, and the text similarity between problem phrases as edge weights. When there are two or more common terms between two problem phrases, an edge is added between them. The text similarity between two problem phrases can be calculated based on pre-trained word vectors, such as Word2Vec, Glove, and Bert. In this study, Tecent pretrained Chinese word vectors were used. To obtain the vector of a problem phrase, a simple Avg2Vec algorithm is used to compute the average vector of every word in the phrase. Then, the cosine similarity between two problem phrases is calculated as the weight between them. If the experimental dataset is a Chinese corpus, it is necessary to segment the problem phrases before vectorizing them.
(3) Identifying and merging same problems
Weighted community detection is exploited to identify the same problems in the problem relation network. Problem phrases in the same community are considered the same problem. By analyzing the occurrence frequencies of problem terms within the same community, the top three problem terms are selected and combined to represent the name of a problem. This process facilitates the identification of the relationship between problem phrases. For example, the research problems “Preparation and catalytic oxidation of porous nano catalysts for carbon monoxide” and “Preparation of nitrogen-doped graphene porous carbon composites and their redox catalysis” have been identified and merged into the same problem. By conducting a statistical analysis of the problem terms involved, it is found that “catalysis,” “porous,” and “oxidation” are the top three terms. Therefore, the name of the research problem is represented as “catalysis, porous, oxidation.”
3.2.5 Identifying multidisciplinary research problems
After merging the problem phrases into problems, non-duplicated research problems were obtained. Integrating the disciplinary classification codes of papers corresponding to problem phrases in the problem community can provide information for determining whether a problem involves multiple disciplines. For example, “catalysis, porous, oxidation” is a research problem that results from merging the research problems “Preparation of Porous Nano Catalysts and Catalytic Oxidation of Carbon Monoxide” from “0703 Chemistry” and “Preparation of Nitrogen-Doped Graphene Porous Carbon Composite Materials and Their Redox Catalysis” from “0805 Materials Science and Engineering.” As it involves two disciplinary fields, it is identified as a multidisciplinary research problem.
4 Experiments and discussions
4.1 Data
This study selected the typical multidisciplinary research field of “Carbon Peaking and Carbon Neutrality Goals (CPCN)” to validate the proposed method. Through manual investigation and expert consultation, relevant CPCN disciplines were selected, and the core journals of these disciplines with high influencing factors and clear disciplinary boundaries were selected as data sources. The metadata of the papers published in these selected journals from 2010 to 2019 were collected, including the title, keywords, abstract, and Chinese library classification codes. After data cleaning, 176,895 paper records were obtained. Because not all papers are about CPCN, we adopted a simple strategy to select CPCN papers. First, we conducted statistical counts of the keywords in each paper. We selected the top 1,000 keywords and determined a preliminary CPCN vocabulary in each discipline through a web search. The results were then sent to experts from various disciplines to further confirm the final CPCN vocabulary. Finally, papers with keywords in the CPCN vocabulary were selected as the CPCN experimental dataset. The CPCN dataset consists of 17,239 paper records across two main disciplinary category codes and 11 first-level disciplinary codes, with 13,342 records in the training set and 3,897 records in the test set. The disciplinary distribution of the number of papers in the CPCN dataset is shown in Table 2.
Table 2. Discipline distribution of the number of papers in the CPCN dataset. |
| Main category | Data volume of main category | First-level category | Data volume of first-level category |
|---|---|---|---|
| 07 Science | 1,917 | 0703 Chemistry | 1,334 |
| 0706 Atmospheric Sciences | 583 | ||
| 08 Engineering | 15,322 | 0805 Materials Science and Engineering | 736 |
| 0807 Power Engineering and Engineering Thermophysics | 1,008 | ||
| 0813 Architecture | 638 | ||
| 0817 Chemical Engineering and Technology | 5,309 | ||
| 0819 Mining Engineering | 767 | ||
| 0820 Oil and Gas Engineering | 1,008 | ||
| 0823 Transportation Engineering | 750 | ||
| 0828 Agricultural engineering | 2,055 | ||
| 0830 Environmental Science and Engineering | 3,051 |
Based on the analysis of text patterns in abstracts and titles for three types of papers: US, SO, and EXP, papers that met the patterns of each type were collected from the literature database. Further analysis of the collected papers revealed that the most frequently observed types of EXP were EXP-S and EXP-RG, with very few others. Therefore, we retained only EXP-S and EXP-RG data and removed other types of EXP data. Therefore, in the research objective classification experiment, the EXP types were further divided into EXP-S and EXP-RG, and four labels (US, SO, EXP-S, and EXP-RG) were used. The dataset constructed for the research objective classification model was manually annotated, with each category containing 500 samples, of which 400 samples were used for model training, and 100 samples were used to test the performance of the model. That is, the training set contained 1,600 samples, and the test set contained 400 samples.
4.2 Experimental results on text classification of research objectives and disciplinary codes
4.2.1 The research objective classification
In the construction of the research objective classification model, five classical algorithms were employed to find the best model for annotating papers. The comparative experimental results are shown in Table 3. Precision, recall, and F1 score were used as evaluation metrics, and the overall performance of the classification model was assessed using macro-average metrics. It can be observed that the SVM algorithm achieved the best performance across all evaluation metrics. Therefore, the research objective classification model based on the SVM algorithm was selected for this labeling task. Using the trained model, all papers in the CPCN dataset were assigned one of four labels: US, SO, EXP-S, and EXP-RG.
Table 3. Comparison of different methods for research objective classification. |
| Algorithm | Macro-Precisio n | Macro-Recall | Macro-F1 |
|---|---|---|---|
| SVM | 0.85 | 0.84 | 0.84 |
| NB | 0.81 | 0.81 | 0.81 |
| Random forest | 0.77 | 0.75 | 0.75 |
| LSTM | 0.69 | 0.62 | 0.65 |
| FastText | 0.71 | 0.67 | 0.68 |
4.2.2 The disciplinary classification
In the experiment, because the metadata of the literature database did not provide disciplinary codes, it was necessary to establish a disciplinary classification model. As described in Section 3.2.1, a hierarchical text classification method based on stacking ensemble learning (Ran et al., 2020) was selected to assign a label of disciplinary code to each paper in the CPCN dataset. Similar to the construction of the research objective classification model, precision and recall were used to evaluate the three other algorithms. The goal was to determine whether the stacking algorithm was the most effective. Additionally, macro-precision, macro-recall, and macro-F1 score were selected as the evaluation metrics. The experimental results are listed in Table 4. The stacking method is optimal for all metrics, with F1 values increased by 0.06, 0.12, and 0.14, respectively, compared to the SVM, NB, and LSTM methods. Therefore, the disciplinary classification model based on the stacking algorithm was selected for this labeling task. Using the trained model, each paper in the CPCN dataset was assigned a first-level disciplinary code.
Table 4. Comparison of stacking method and other methods in disciplinary classification. |
| Algorithm | Macro-Precision | Macro-Recall | Macro-F1 |
|---|---|---|---|
| SVM | 0.81 | 0.69 | 0.74 |
| NB | 0.64 | 0.77 | 0.68 |
| LSTM | 0.67 | 0.65 | 0.66 |
| Stacking | 0.81 | 0.79 | 0.80 |
4.3 Experimental results on multidisciplinary research problems identification
4.3.1 Abstractive title generation
The pre-trained BART model (Lewis et al., 2020) and ChatGLM model (Du et al., 2022; Zeng et al., 2022) were used to create a text generation model for generating abstractive titles for papers. BART, a denoising autoencoder for pretraining sequence-to-sequence models, learns to map corrupted documents to the original documents and achieves state-of-the-art results on a number of text generation tasks. The ChatGLM model is based on the General Language Model (GLM) architecture with an autoregressive blank infilling method, specifically designed for generating natural language dialogues. Through unsupervised pre-training on a large-scale text corpus, the two models demonstrated good performance and versatility for various downstream tasks. Therefore, they can be used as a basis for fine-tuning a target task. Fine-tuning allows us to adapt the model to the target domain and task. As described in Section 3.2.2, 11,000 papers were retrieved as external data from the literature database according to the title pattern for each research objective in Table 1 , of which 10,000 were used as fine-tuning data and 1,000 were used as testing data. The size of the data may have different effects on the results of fine-tuning the models, but this study focuses on the introduction of the presented method and did not compare the effects of fine-tuning the two models with different data volumes. These external fine-tuning data were fed into pre-trained models with abstracts as the input and titles as the expected generated text output. After all fine-tuning data were fed, the trained models generated an abstractive title with a specific text pattern when inputting the abstract of the paper.
To evaluate the performance of BART and ChatGLM in generating abstractive titles, the BLEU metric (Papineni et al. 2002) was chosen as the criterion. In machine translation technology, BLEU is a measurement of the difference between automatic translations and human-created reference translations of the same source sentence. Therefore, BLEU can also be used to determine the effectiveness of the generated text if the generated abstractive title is considered an automatic translation and the original title as the reference translation. The BLEU score was calculated by comparing the n-grams of the machine-translated sentences to the n-gram of the reference sentences. In general, 1-Gram is used to assess fidelity to the original text, while 2-Gram and 3-Gram reflect the fluency and readability of the sentence, respectively. To better evaluate the effectiveness of problem phrases, the unigram metric is employed to measure the matching degree between the generated problem phrase and the actual problem phrase at the character level, while the Exact Match metric is employed to evaluate the model’s ability to restore problem phrases from the original title at the vocabulary level by calculating the proportion of generated problem phrases that match exactly with those in the original problem phrases.
Table 5. Comparison of abstractive title generation between BART and ChatGLM. |
| Research Objective | Model | 1-Gram | 2-Gram | 3-Gram | BLEU | Exact Match | Unigram |
|---|---|---|---|---|---|---|---|
| US | ChatGLM | 0.560 | 0.462 | 0.371 | 0.402 | 0.182 | 0.417 |
| BART | 0.582 | 0.474 | 0.376 | 0.411 | 0.145 | 0.369 | |
| SO | ChatGLM | 0.612 | 0.494 | 0.387 | 0.440 | 0.299 | 0.441 |
| BART | 0.631 | 0.498 | 0.374 | 0.437 | 0.356 | 0.438 | |
| EXP-S | ChatGLM | 0.501 | 0.436 | 0.359 | 0.351 | 0.186 | 0.346 |
| BART | 0.597 | 0.502 | 0.413 | 0.436 | 0.233 | 0.422 | |
| EXP-RG | ChatGLM | 0.588 | 0.487 | 0.401 | 0.422 | 0.197 | 0.441 |
| BART | 0.610 | 0.509 | 0.422 | 0.428 | 0.201 | 0.434 | |
| ALL | BART | 0.577 | 0.463 | 0.372 | 0.408 | 0.203 | 0.367 |
A current similar method based on text generation did not distinguish the research objectives of the study (Cheng et al., 2021). Although the study demonstrated through manual evaluation that the proposed method can generate high-quality titles describing problems and methods, the provided Turing test examples reveal that the generation model effect is not ideal and needs improvement. For example, the original title of a sample paper is “Network Intrusion Detection Based on the Fusion of Mean Clustering Analysis and Multilayer Core Set Aggregation Algorithm,” while the generated title is “Network Intrusion Detection Based on K-Means Algorithm.” Unlike existing methods, the method proposed in this article classifies papers based on research objectives and constructs text generation models separately. The All-Bart model in Table 5 did not distinguish research objectives like the current method, and its indicators were significantly lower than the models that distinguish research objectives, fully demonstrating the necessity of constructing a text-generation model to identify problems by distinguishing research objectives in papers.
4.3.2 Multidisciplinary research problems identification
To validate the effectiveness of the proposed method in identifying multidisciplinary research problems, experiments were conducted on the test set of the CPCN dataset. A total of 264 multidisciplinary research problems were identified in 3,879 papers. Table 6 presents a partial list of recognized multidisciplinary research problems and the first-level disciplines involved.
Table 6. Examples of multidisciplinary research problems. |
| Multidisciplinary research problems | The first-level disciplines involved |
|---|---|
| Catalytic, Cracking, Hydrogenation | 0703 Chemistry, 0817 Chemical Engineering and Technology, 0820 Oil and Gas Engineering |
| Oxidation, Desulfurization, Catalytic | 0817 Chemical Engineering and Technology, 0820 Oil and Gas Engineering, 0830 Environmental Science and Engineering |
| Rare earths, Catalysts, Environmentally friendly | 0805 Materials Science and Engineering, 0820 Oil and Gas Engineering |
| Coal Combustion, Flue Gas, Distribution | 0817 Chemical Engineering and Technology, 0823 Transportation Engineering |
| Communities, Microorganisms, Carbon Sources | 0828 Agricultural Engineering, 0830 Environmental Science and Engineering |
Fifty identified multidisciplinary research problems were randomly sampled and evaluated by three experts with backgrounds in materials science, energy and power, and information science. For each problem, all problem phrases and corresponding papers were used as evaluation materials, and only the unanimous agreement of three experts was considered an evaluation outcome. That is, only multidisciplinary problems identified by three experts simultaneously were considered as preliminary evaluation results. If they have different opinions on a certain problem, a search for dissertations containing all three terms of the problem will be conducted in the dissertation database of CNKI. The obtained theses were used to evaluate the multidisciplinary nature of the problem. The basic idea is that the metadata of theses contain information about the authors’ colleges or schools, and the division of colleges in universities is generally based on disciplines; therefore, if a problem is studied in multiple colleges or schools, it is likely to be multidisciplinary. Several studies have found that identifying multidisciplinary papers based on co-authors from different colleges or schools performed well (Li & Yu, 2018; Wang, et al., 2015), which provides support to the idea. The retrieved theses will then be ranked and sorted based on relevance, and the discipline or school department information from the top five theses will be checked. If there are two or more different colleges or school departments involved, we provide the retrieval results to three experts, and if they further reach a consensus, the evaluated problem is considered a multidisciplinary problem; otherwise, it is considered a single disciplinary problem. For example, the research problem “heat transfer, melt, calculation” showed significant discrepancies in manual classification. However, upon searching the CNKI database, the top five relevant master’s theses were affiliated with the following school department information: “School of Mechanical Engineering with a focus on energetic materials processing,” “Power Engineering and Engineering Thermophysics,” “Architecture and Civil Engineering,” “Energy Power and Mechanical Engineering,” “Power Engineering and Engineering Thermophysics.” The search results were sent to experts who agreed that the problem was multidisciplinary. Therefore, it was ultimately considered that this research problem would fall into a multidisciplinary field.
The results of the manual evaluation are shown in Table 7 , and the accuracy of the identified multidisciplinary research problems was found to be approximately 68%. However, manual analysis is affected by the scope of individual knowledge, and some of the problems that are judged to be single discipline may be multidisciplinary problems. For example, the research problem “community, microorganism, carbon source” which may seem like a singular research problem in the field of Environmental Science and Engineering, is closely related to Agricultural Engineering as well.
Table 7. Manual Evaluation Results. |
| Research problem | Quantities |
|---|---|
| Multidisciplinary research problems | 34 |
| Single-discipline research problems | 16 |
4.3.3 Analysis of multidisciplinary research problems identification results
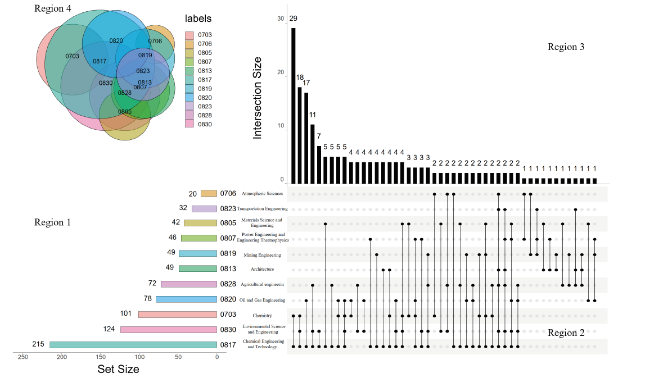
An analysis of the disciplines involved in multidisciplinary research problems was conducted, and a disciplinary distribution chart for multidisciplinary problems was created, as shown in Figure 3. Region 1 of the figures displays the number of multidisciplinary research problems under each first-level discipline. Regions 2 and 3 together illustrate the intersection of multidisciplinary research problems across different disciplines. Region 2 represents the distribution of first-level disciplines within the intersection, whereas Region 3 represents the distribution of the number of problems within the intersection. The Venn diagram in Region 4 clearly illustrates the intersection of research problems across different first-level disciplines.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 3. Discipline distribution chart of multidisciplinary research problems. |
It was found that disciplines “0817 Chemical Engineering and Technology” and “0830 Environmental Science and Engineering” have the highest number of multidisciplinary research problems. This indicates that in the field of CPCN research, these two disciplines have broad research scopes, or their research results are widely applied in other disciplines. It can be observed that there are three multidisciplinary communities in the field of CPCN. The first community consisted of “0703 Chemistry”, “0817 Chemical Engineering and Technology”, and “0820 Oil and Gas Engineering”. The second community includes “0805 Materials Science and Engineering”, “0813 Architecture”, “0828 Agricultural Engineering”, and “0830 Environmental Science and Engineering”. The third community comprises “0807 Power Engineering and Engineering Thermophysics”, “0819 Mining Engineering”, and “0823 Transportation Engineering”.
5 Conclusion
A method for identifying multidisciplinary research problems is proposed based on pre-trained language generation models. It achieves document-level multidisciplinary research problem identification using text classification and abstractive title generation strategies. Given a batch of abstract texts from papers that may have multidisciplinary implications, the proposed method can identify multidisciplinary problems. The identified multidisciplinary problems can support relevant management authorities in selecting important multidisciplinary problems, organizing multidisciplinary teams for innovative research, and helping multidisciplinary researchers understand the research status of related problems. The proposed method first identifies the research objective types and disciplinary labels of papers using a text classification technique. Second, it creates a text generation model for each research objective type to generate abstractive title for each paper based on the abstract. Third, it extracts problem phrases from the generated titles using a regular expression technique. Fourth, it creates problem-relation networks and identifies the same problems by employing a weighted community detection algorithm. Finally, it identifies multidisciplinary problems based on the disciplinary classification labels of the papers.
The experimental results on the constructed CPCN dataset show that the method of establishing multiple text generation models based on the categories of research objectives can improve the performance of various metrics, which confirms the necessity of separately identifying problems in papers based on their research objectives. Through manual evaluation, it was found that the majority of multidisciplinary research problems were indeed identified across multiple disciplinary fields. An analysis of the distribution of multidisciplinary research problems in the field of CPCN was conducted, and the results were consistent with the current understanding of multidisciplinary cooperation in this field. In summary, the use of text-generation technology to identify multidisciplinary research problems is feasible.
In subsequent research, we aim to incorporate additional information such as keywords, citation networks, and authors’ writing preferences to achieve more precise and robust multidisciplinary problem recognition. We will attempt to use the proposed method in other multidisciplinary fields to further validate its effectiveness. We also plan to compare the proposed method with multidisciplinary problem recognition methods based on information extraction technology, although obtaining a large number of labeled datasets for information extraction-based technology is expensive, time-consuming, and challenging, and we also have to find appropriate metrics to evaluate the performance of these two different methods.
Funding information
This work is mainly supported by the General Projects of ISTIC Innovation Foundation “Problem innovation solution mining based on text generation model” (MS2024-03).
Acknowledgment
The authors are grateful to the Ministry of Science and Technology of China for the financial support to carry out this work.
Author contributions
Ziyan Xu (xuzy2021@istic.ac.cn): Methodology (Equal), Writing - original draft (Supporting); Hongqi Han (bithhq@163.com): Methodology (Lead), Project administration (Lead), Resources (Lead), Supervision (Lead); Linna Li (Liln@istic. ac.cn): Supervision (Supporting); Junsheng Zhang (zhangjs@istic.ac.cn): Resources (Supporting); Zexu Zhou (zhouzx2022@istic.ac.cn): Data curation (Supporting).