

1 Introduction
Science can be considered a dynamic system in which scholars and their research activities play a dominant role to contribute their discoveries for the advancement of science (Winnink et al., 2019). And major advances in science depend to a large extent on groundbreaking scientific discoveries. This phenomenon is in line with the structure of scientific revolutions proposed by (Kuhn, 1997), who viewed the development of science as an alternative process between “normal science” and “scientific revolution”. During normal science, researchers uphold established paradigms to incrementally advance scientific knowledge. In contrast, scientific revolutions occur when new paradigms emerge to address “anomalies” unsolvable within established paradigms, often leading to profound shifts in scientific understanding. Scientific breakthroughs are typically associated with discoveries that have the potential to catalyze a scientific revolution.
Numerous phenomena accompany breakthroughs, manifesting in research articles, which include shifts in research topics, changes in reference distributions, and the introduction of novel definitions and terminology (Kuhn, 1997). The assessment of scientific breakthroughs plays a crucial role in tracking emerging areas in science, garnering significant interest across various methods. Currently, the predominant approach to identifying scientific breakthroughs centres on citation analysis, examining citation patterns related to these breakthroughs from a dynamic citation process perspective. However, relying solely on citations for early breakthrough identification can be less timely due to inherent delays. Moreover, existing methods primarily rely on metadata from research articles, such as keywords and reference information, often remaining surface-level without delving into the content for early breakthrough signals.
In this paper, we introduce the concept of outliers for early scientific breakthrough identification. Outlier is an observation which appears to be inconsistent with the remainder of that set of data (Bansal et al., 2016). In data mining, outlier detection involves identifying data points that do not conform to the expected patterns or behaviours within a dataset. Outliers often coincide with abrupt shifts in normal scientific trajectories. Therefore, our aim is to identify breakthrough innovations in academic papers by detecting outliers when research topics undergo substantial changes. Specifically, we utilize academic papers as carriers to identify research entities within paper titles and abstracts, employing semantic technology to represent them as high-dimensional vectors and then carry out the dimensionality reduction process. Based on which, we employ an outlier detection method to identify the early emergence of breakthrough papers and track their evolution trends by considering the publication timestamps. The method proposed in this paper can offer valuable insights for experts in assessing scientific breakthroughs, enabling researchers to pinpoint highly relevant academic papers promptly, understand evolving research subjects, and enhance the efficiency of scientific inquiry.
2 Related work
Currently, a universally accepted definition of scientific breakthroughs remains elusive, as diverse interpretations and conceptualizations abound. Various scholars proposed different frameworks and principles to characterize this elusive phenomenon. Thomas Kuhn, for instance, posited that the progression of science entails a gradual accumulation of “normal” conditions until the emergence of an anomaly that defined explanation within the confines of the existing theory. This triggers a state of “revolution”, prompting the formulation of a new paradigm to accommodate the evolving scientific landscape. Hollingsworth (2008) defined a breakthrough as “a finding or process, often preceded by numerous small advances, which leads to a new way of think about a problem…”. Winnink et al. (2019) considered science breakthroughs to be events that have a major impact on future scientific research and are transformative points in science. Ponomarev et al. (2014), in addition to describing the significant impact of breakthrough research on science, defined breakthrough research literature in terms of citations as literature that receives a high number of citations and that leads to a change in the direction of research. Building upon the articulated definition and features characterizing scientific breakthroughs, we posit that the developmental trajectories diverge between normal science and breakthrough scenarios. In the initial stages of scientific breakthroughs, anomalies exhibit a tendency to possess a low degree of similarity and relevance to the prevailing scientific paradigm, effectively assuming a status akin to “outliers.” Consequently, this study endeavors to identify potential scientific breakthroughs by scrutinizing anomalous semantic features, such as new theories, innovative approaches, and novel research questions within specific fields. This analytical perspective is framed within the context of outlier identification.
Substantial progress has been achieved in the realm of identifying scientific breakthroughs. Currently, there are three primary approaches dominating the landscape of breakthrough identification research: expert qualitative evaluation, bibliometrics-based identification utilizing idiosyncratic indicators, and textual feature-based identification methods.
The expert qualitative evaluating method relies extensively on the profound knowledge and experience of experts in science and technology, policy experts, and strategic intelligence experts. These experts discern scientific breakthroughs through a nuanced understanding of cutting-edge trends. Their approach involves the comprehensive examination and analysis of relevant data, allowing for a holistic perspective on breakthroughs. For instance, Science’s 2022 Breakthrough of the Year, Nature’s 10 remarkable discoveries from 2020, 10 Breakthrough Technologies 2023 of MIT Technology Review, 2022 Research Fronts from Chinese Academy of Sciences.
The bibliometrics-based identification method, centered around idiosyncratic indicators, primarily revolves around the analysis of citation data. Min et al. (2021) identified citation patterns of scientific breakthroughs through a perspective of dynamic citation process. Schneider and Costas (2017) utilized three related explorative approaches to identify potential “breakthrough” publications based on refined citation analyses. Savov et al. (2020) proposed a novel method that utilizes a classifier for predicting publication years based on latent topic distributions, and they calculated real-number innovation scores used to identify potential breakthrough papers and turnaround years. Wang et al. (2023) proposed a knowledge entity-based disruption indicator by quantifying the change of knowledge directly created and inspired by scientific breakthroughs to their evolutionary trajectories. Two groups of analytic units, including MeSH (Medical Subject Headings) terms and their co-occurrences, are employed independently by the indicator to measure the change of knowledge.
Nevertheless, relying solely on citation frequency to evaluate the influence of an academic article is a one-sided approach. This is because not every citation carries equal significance, and some citations may even be negative in nature. Recognizing this limitation, certain researchers have endeavored to identify scientific breakthroughs by delving into the textual features of academic articles. Small et al. (2017) described a procedure for identifying discoveries in the biomedical sciences that made use of citation context information, or more precisely citing sentences, drawn from the PubMed Central database, the procedure focused on the use of specific terms in the citing sentences and the joint appearance of cited references. Wang et al. (2021) presented a new method for identifying scientific breakthroughs from research papers based on cue words commonly associated with major advancements.
Despite advancements in the methods for identifying scientific breakthroughs, certain shortcomings persist. Firstly, the early stages of scientific breakthroughs often go unnoticed due to their inherently forward-looking nature, making it challenging to capture their early features. This limitation hinders the efficacy of identifying breakthroughs through citation analysis, as attention tends to be relatively low when these breakthroughs first emerge. Additionally, current identification methods primarily concentrate on metadata information like keywords and citations, remaining at the periphery of text analysis. Few methods delve into the semantic features within the literature itself, focusing on the initial signals accompanying the emergence of scientific breakthroughs.
Recent strides in natural language processing (NLP) technology have facilitated the application of text classification, sequence labeling, and other techniques in the domain of scientific and technological literature. The refinement of knowledge objects from “document level” to “sentence level” and “entity level” in intelligent research has been noteworthy. This paper defines research entities as the key insights revealed in the research question, research object, and research method of scientific and technological literature. The objective is to deepen the exploration of the focus and core content of individual academic papers based on research entities. This approach aims to achieve the early identification of scientific breakthroughs by analyzing outliers within the set of research entities associated with an academic paper within a specific research field. Dynamic monitoring techniques are then employed to analyze the subsequent evolution of the field. The effectiveness of the proposed method is ultimately validated through manual analysis and judgment.
3 Methodology
This section delineates the methodology for identifying scientific breakthroughs through outlier analysis based on research entities. The approach leverages semantic technology to mine research entities from the titles and abstracts of academic articles, representing them as vectors. Subsequently, early identification of scientific breakthroughs (breakthrough papers), is achieved through outlier detection.
3.1 Overall idea
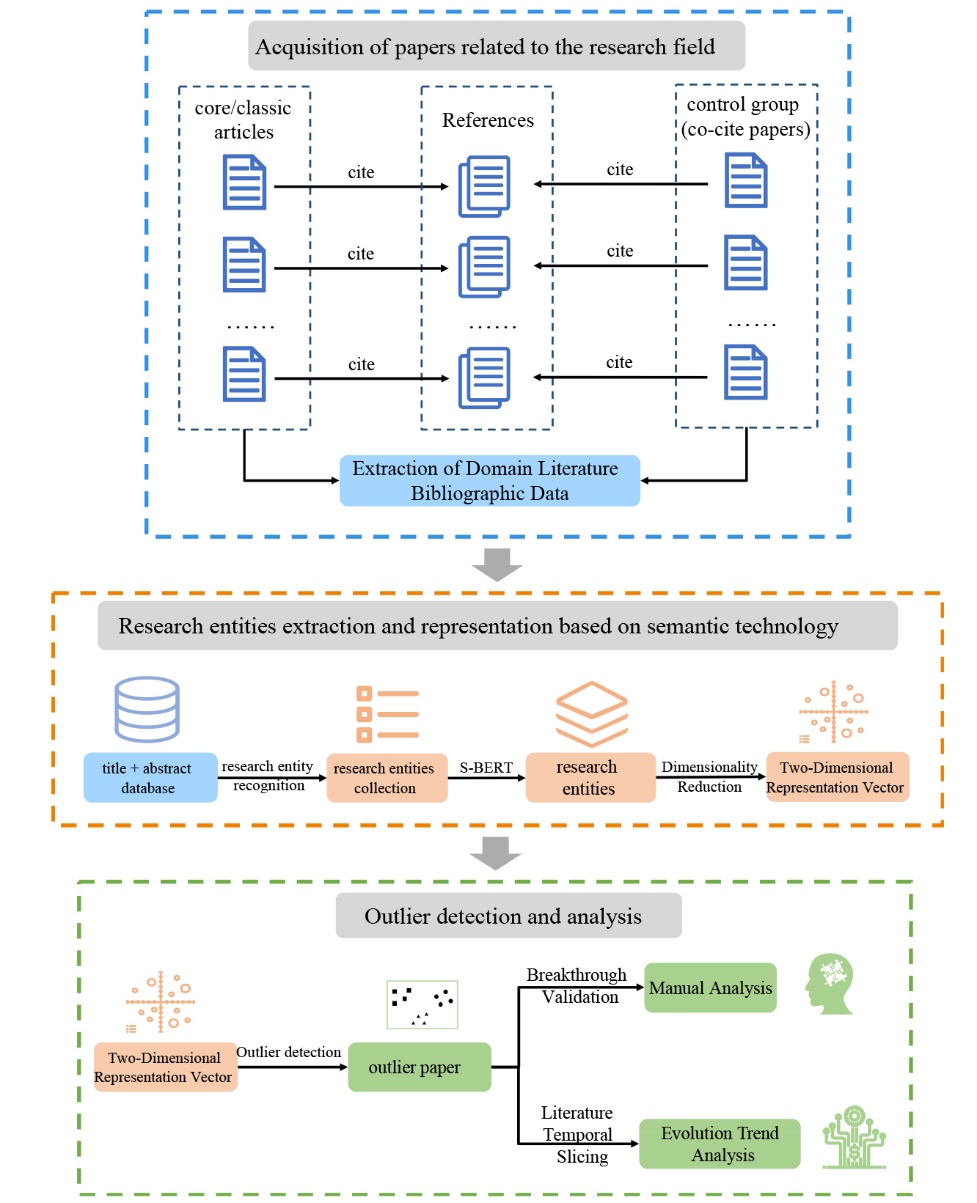
The primary focus is on discerning “abnormal” signals in academic papers that may indicate potential scientific breakthroughs during their early publication stages. The process involves selecting a specific research field and extracting research entities using semantic techniques. These entities are then transformed into high-dimensional vectors, mapped to a 2D plane through dimensionality reduction, and subjected to outlier detection. The method analyzes outlier phenomena based on different types of research entities, such as “research question outlier”, “research object outlier”, “research method outlier” etc., enabling a comprehensive determination of scientific breakthroughs. The trajectory of the identified outliers is tracked over time to observe whether they tend to gradually converge, indicating a shift towards becoming mainstream trends. Manual judgment is also applied to verify the efficacy of the proposed method. The overall idea is shown in Figure 1.
Figure 1. The overall idea for the identification of scientific breakthroughs through outlier analysis based on research entities. |
3.2 Method for identification of scientific breakthroughs
The outlier analysis method for identifying scientific breakthroughs based on research entities can be divided into three main components. (1) Delineating research scope: Define a suitable research scope for discovering scientific breakthroughs. (2) Extracting research entities: Employ semantic technology to extract research entities from the titles and abstracts of academic papers, represent them as vectors, and perform dimensionality reduction. (3) Computing outliers and analyzing evolutionary trends: Utilize outlier analysis to compute and analyze the outlier and integration phenomena of scientific breakthroughs on the temporal dimension, and validate the effectiveness of the method for early identification of scientific breakthroughs.
3.2.1 Acquisition of papers related to the research field (control group)
To identify academic papers within the same research field as potential breakthrough papers, this paper adopts the approach proposed by Chen and Han (2021). To be specific, we first need to identify core or classic articles as core collections in the research field, then collect articles that co-cite papers in core collections as the control group, we argue that common references between the control group (non-breakthrough papers) and core collections, both published within the same date range. Although this approach may not cover all articles in a research field, it provides a suitable solution for identifying a control group relative to breakthrough articles in a relatively narrow field of study.
3.2.2 Research entities extraction and representation based on semantic technology
After obtaining academic papers within the appropriate research scope, the English research entity recognition function①(① http://sciengine.las.ac.cn/NER_SCI_EN) developed by our research team is applied to identify research entities in the titles and abstracts of each paper. And the research entities identified are classified into nine distinct categories, namely methods/models, data resources, research questions, scientists, theories, equipment, software systems, locations, and metrics. In this study, we call the API interface of this function to identify the research entities in the texts and subsequently select research entities in proper categories to align with the specific tasks.
To vectorize the research entity set, which is comprised of the filtered research entities above mentioned, a textual representation method is in need. In this study, Sentence-BERT (SBERT) (Reimers & Gurevych, 2019) is utilized to represent research entities, capturing their latent semantic features. SBERT is primarily used for addressing unsupervised tasks such as clustering and sentence similarity calculations. It employs Siamese network structures to obtain vector representations of sentence pairs and then pre-trains similarity models to obtain semantically meaningful paragraph vectors, which aligns with the task scenario in this research. Additionally, for the purpose of thoroughly learning the features between entities, we concatenate all identified research entities in each paper into a single string, treating it as a textual representation unit and mapping it to Euclidean space $ \mathbb{R}^{n}$, that is
$ f_{1}: X=\left\{x_{1}, \ldots, x_{l}, \ldots, x_{L} \mid L \in N^{+}\right\} \rightarrow E=\left\{e_{1}, \ldots, e_{l}, \ldots, e_{L} \mid L \in N^{+}, e_{l} \in \mathbb{R}^{\mathrm{n}}\right\}$
where xl is the concatenated research entity string for each paper, such as “TRPV1-calmodulin interaction, pain receptor TRPV1, vanilloid agonists, vanilloids, cell-regulatory calmodulin-protein interactions”; X is a collection formed by all concatenated research entity strings, el represents the vector representation corresponding to xl, E is a collection comprised of all vector representations while L denotes the number of papers. In this study, ultimately, the research entity set for each paper will be transformed into a 768-dimensional vector, namely n=768.
In a high-dimensional document vector space, literature sharing similar research content will exhibit closely positioned semantic vectors, while those with differing research content will be positioned farther apart. In other words, variances in thematic characteristics embedded within the semantic vectors lead to the convergence or divergence of literature points in a high-dimensional semantic space. This study maps the high-dimensional knowledge structure characterized by the research entity set vectors el onto a two-dimensional semantic plane and visualizes it, that is
$ f_{2}: E \rightarrow E^{\prime}=\left\{e_{1}^{\prime}, \ldots, e_{l}^{\prime}, \ldots, e_{L}^{\prime} \mid L \in N^{+}, e_{l}^{\prime} \in \mathbb{R}^{2}\right\}$
where el′ is the corresponding vector of el in a two-dimensional Euclidean space, and E′is the collection of these el′. Subsequently, the Principal Component Analysis (PCA) method is employed to reduce the dimensionality of document embeddings. After PCA dimension reduction, the various principal components become mutually orthogonal, effectively eliminating mutual influence within the original data.
3.2.3 Outlier detection and analysis
After appropriately representing and processing each paper, this study employs outlier detection methods to assess whether a paper is an outlier. Besides, it observes the position and dispersion of the paper within the research scope as the number of related papers increases each year. More concretely, this study utilizes two common outlier detection algorithms (DBSCAN and Isolation Forest) to identify groundbreaking papers, thereby demonstrating the comprehensive robustness and universality of the proposed method.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a density-based spatial clustering algorithm that can identify clusters of arbitrary shapes in spatial data with noise. This algorithm primarily quantifies density by the neighborhood radius ε and the minimum number of data points m within the neighborhood. The density is defined as follows:
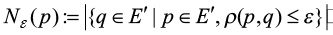
where ρ is a metric in the Euclidean space ℝ2, p and q are two-dimensional vector representations within the set E′, and Nε(p) represents the number of data points within the ε-neighborhood of p. In the DBSCAN algorithm, when Nε(p)≥m, p is considered a high-density point, i.e., a core point; when Nε(p)<m, p is considered an outlier. The algorithm also defines data points q within the ε-neighborhood of p as core objects, indicating direct density reachability to p. The collection of maximum density-connected objects constitutes a cluster.
Isolation Forest is a decision tree-based algorithm that randomly selects features from a given feature set and then identifies outliers by choosing a split value between the maximum and minimum values of the feature. This random partitioning of features results in shorter paths generated for anomalous data points within the tree, effectively separating them from the rest of the data.
This paper denotes the number of clusters obtained based on two outlier detection algorithms as K. Each cluster is required to meet the following conditions:
$\left\{\begin{array}{c} C=\left\{C_{1}, \ldots, C_{k}, \ldots, C_{K} \mid 1 \leq k \leq L\right\} \\ C_{k}=\left\{c_{k 1}, \ldots, c_{k n_{k}}\right\} \neq \varnothing ; k=1,2, \ldots, K, n_{k} \in N^{+} \\ \bigcap_{k=1}^{K} C_{k} \cup O=E^{\prime} \\ C_{i} \cap C_{j}=\varnothing ; i, j=1,2, \ldots, K, i \neq j \end{array}\right.$
where Ck represents a cluster, C is the set of all clusters, nk is the number of data points in the k-th cluster, and O is the set of outlier points. To measure the dissimilarity between outlier papers and other papers or paper clusters, this paper utilizes the Euclidean metric (Euclidean distance) for measurement. The formula for calculating the distance between two points in a two-dimensional plane is as follows:
$\rho(p, q)=p-q_{2}=\sqrt{\left(p_{1}-q_{1}\right)^{2}+\left(p_{2}-q_{2}\right)^{2}}$
where p=(p1, p2)∈E′, q=(q1, q2)∈E′. The formula for calculating the distance from the outlier point o to the cluster set Ck is as follows:
$\rho\left(o, C_{k}\right)=\inf _{p \in C_{k}} \rho(o, p)$
where o=(o1, o2)∈O⊂E′. The formula for calculating the distance from the outlier point o to the nearest cluster is as follows:
ρ0=min{ρ(o, Ck) | k=1,2,...,K}
The formula for calculating the distance from the outlier point o to the nearest cluster centroid is as follows:
$\rho_{c}=\min \left\{\rho\left(o, \hat{c}_{k}\right) \mid k=1,2, \ldots, K\right\}$
$\hat{c}_{k}=\frac{1}{n_{k}} \sum_{n=1}^{n_{k}} c_{b n}$
where $\hat{c}_{k}$ represents the centroid of the k-th cluster, and ckn represents the n-th data point in the k-th cluster. The formula for calculating the average distance from the outlier point o to the nearest cluster is as follows:
$\begin{array}{c} k_{0}=\underset{k}{\arg } \rho_{c} \\ \rho_{\text {avg }}=\frac{1}{n_{k_{0}}} \sum_{n=1}^{n_{k 0}} \rho\left(o, c_{k_{0^{n}}}\right) \end{array}$
Once outlier papers have been identified, it becomes crucial to track their subsequent evolutionary trajectory, analyzing the trend of their transition from outliers to mainstream over time. After obtaining two-dimensional document vectors for the dataset, historical cumulative research topic distribution graphs are constructed for various research entity categories based on the publication year. Each region on the research topic distribution graph conveys specific semantic information. Since the literature vectors are trained concurrently, the proximity of coordinates in the visual representation of annual research topics signifies semantic relevance. This implies that by comparing the changes in visual landscapes over the years, one can gain insights into phenomena such as the expansion of research scope, the early emergence of scientific breakthroughs, and their subsequent integration during the evolution of the field. Furthermore, this paper conducts manual verification on each identified outlier and monitors their subsequent citation status to determine whether they hold the potential for groundbreaking contributions. This validation process is performed from both quantitative and qualitative perspectives to affirm the effectiveness of the early scientific breakthrough identification method proposed in this paper.
4 Case study
This section presents a case study using the aforementioned outlier analysis method based on research entities to identify scientific breakthroughs. We took inspiration from a dataset of four types of scientific breakthrough papers compiled by Mugabushaka et al. (2020), which including the Science Top 10 Breakthrough of the Year, award-winning papers (Nobel Prize, Lasker Award), highly cited papers, and expert-reviewed papers (from the Faculty Opinions database, marked by at least three reviewers as expressing novelty and rated “very good” or “exceptional”). Specifically, we used the key publications of the 2021 Nobel Prize in Physiology or Medicine laureates as examples to validate the breakthroughs associated with the laureates’ scientific discoveries by dynamically observing the influence of their publications on the research field through outlier analysis.
4.1 Selection of empirical domain
Based on the methodology outlined for obtaining relevant papers within the research domain, this study uses the key publications listed on the Nobel Prize official website as the core collection and precisely locates related papers within the same field. We focus on the award-winning work of David Julius, the recipient of the 2021 Nobel Prize in Physiology or Medicine. In 1997, Julius’s team published a groundbreaking paper that identified a heat-sensitive receptor, the TRPV1 ion channel, using capsaicin to detect sensors in skin nerve endings responsive to heat. This receptor is activated at temperatures perceived as painful, providing critical insights into how temperature differences induce electrical signals in the nervous system. Subsequent papers in 1998 and 2000 further expanded on this research. Therefore, our related papers are centered on temperature sensation. Additionally, considering that both 2021 laureates’ discoveries relate to sensory receptors, we expanded the research domain to include the eight key publications listed on the Nobel Prize website. From these, 44,918 co-cited papers were collected from the Web of Science database, spanning from 1927 to 2022, after excluding review articles.
4.2 Selection and representation of research entities using semantic technology
Utilizing the research entity recognition model for English scientific literature developed by our team, we identified research entities in the titles and abstracts of the aforementioned 44,918 papers. Given that our case study focuses on the medical field and the model is designed for general purposes, we retained only the “research problem” entity type, considering the characteristics of medical abstracts and actual identification results. Manual sampling and validation revealed that while the identified entities could encapsulate the key issues and core content of the articles, some non-core entities unrelated to the main content might interfere with subsequent semantic representation, potentially causing deviations when mapped to a two-dimensional semantic plane. Therefore, a rule-based approach was employed to filter the initial research entities.
The filtering process primarily utilized move recognition and semantic similarity ranking methods. The move is defined as “a unit of text that serves a particular communicative purpose” (Swales, 2011), such as the structured sections in a scientific abstract like background, methods, objectives, results, and conclusions. For identifying moves in each abstract, we leveraged our group’s English scientific literature move recognition function②(② http://sciengine.las.ac.cn/Move_Refinded_Masked_Sentence_Model) to automatically classify each sentence into a certain type (Background, Objective, Methods, Results, Conclusions). Through preliminary experiments and practical analysis, it was determined that research problems typically appear in the title or background/objective sections of the abstract. Thus, only these sections were retained, and each paper’s research entity set was examined to ensure presence in these sections; otherwise, they were excluded from the initial list.
Additionally, to ensure that each research entity in the set is representative and aligns with the article’s main theme, we further refined the entity list using semantic similarity ranking. Specifically, we calculated the semantic similarity between each research entity and the paper, retaining the top five entities with the highest similarity for each paper. Given the medical focus of the empirical study, we employed the PubMed-SBERT, which is trained by the PubMedBERT model (Gu et al., 2021), pre-trained on 14 million medical abstracts by Microsoft (containing 3 billion words and full-text articles from PubMed Central), to represent the research entities and capture their underlying semantic features, it is more domain-adaptive than SBERT. The process of semantic similarity calculation using PubMed-SBERT also completes the high-dimensional semantic representation of research entities, and then we use the PCA method to perform the dimensionality reduction.
4.3 Outlier detection and result analysis
We applied DBSCAN and Isolation Forest algorithms to detect outliers after reducing the dimensionality of each paper’s research entity set, followed by an analysis of cumulative development trends. In a relatively narrow research field, scientific breakthroughs typically occur infrequently. Thus, this study employs these two common outlier detection methods, adjusting parameters iteratively to identify a small and reasonable number of outliers.
The DBSCAN clustering algorithm uses two parameters, ε (epsilon) and m, to determine outliers. Epsilon represents the neighborhood radius, and m is the minimum number of papers required within this radius to form a cluster. That is to say, a smaller ε and larger m result in fewer outliers in the set. Conversely, if a paper remains isolated even when its neighborhood radius is sufficiently large, it is likely an outlier. For the Isolation Forest algorithm, adjusting the proportion parameter of outliers directly influences the number of detected outliers. This study aims to find the optimal outlier state by continuously adjusting the parameters of both methods.
We observed changes in research themes within the related field by setting different clustering parameters. Table 1 lists the number of outliers (|O|), the number of clusters (K), the coordinates of cluster centers, the centroid distance between award-winning papers and the nearest cluster (ρc), the average distance (ρavg), and the minimum distance (ρ0) under each DBSCAN parameter setting. To clearly demonstrate the outlier status of award-winning papers, the distribution of David Julius’s seminal 1997 paper within the entire research field cluster is visualized (see Figure 2 ). It can be observed that this paper is consistently detected as an outlier across different parameter settings, which to some extent, confirms the breakthrough potential of this paper.
Table 1. Outlier detection of award-winning papers based on DBSCAN with different parameters. |
| (ɛ, m) | |O| | K | cluster center | ρc | ρavg | ρ0 |
|---|---|---|---|---|---|---|
| (0.2, 6) | 270 | 13 | (1.5761, 0.2596), (-0.2734, 1.0702), (-0.3131, 1.8162), (-1.2773, 1.1308), (-1.5171, -0.9898), (-0.8623, -1.2288), (1.9380, -0.0093), (-0.3877, 0.0042), (2.3369, -0.6248), (-0.2435, -0.9226), (2.2606 -1.4315), (-0.5289, 2.6845), (0.3600, 0.4823) | 1.3662 | 3.6926 | 1.1378 |
| (0.2, 8) | 366 | 9 | (0.1419, 1.4233), (-1.5061, -1.0087), (-0.3125, 1.9862), (-0.2656, 1.0839), (-0.3364, 0.0487), (0.3600, 0.4823), (2.3846, -0.5791), (-0.6100, 1.5679), (-0.5289, 2.6845) | 1.6182 | 3.9896 | 1.5222 |
| (0.2, 10) | 469 | 5 | (-1.5272, -1.1534), (-0.2656, 1.0839), (-1.9954, -0.7550), (-0.3919, 1.9875), (-1.0851, -0.6015) | 3.1773 | 4.4585 | 2.9030 |
| (0.3, 6) | 50 | 5 | (-0.7352, 0.2107), (1.8761, -0.6375), (2.9949, -1.2226), (0.2953, -1.6990), (1.9262, -1.9501) | 1.8954 | 3.4875 | 0.9506 |
| (0.3, 8) | 116 | 7 | (-1.3791, -1.0182), (1.7058, 0.0602), (-0.2563, 1.0866), (-1.2736, 1.0911), (2.0780, -0.9308), (-0.2736 2.8000), (0.5442, 1.9619) | 1.4976 | 3.5744 | 0.9769 |
| (0.3, 10) | 176 | 6 | (1.6912, 0.0958), (-0.3292, 1.5848), (-1.4142, -1.0364), (2.1113, -0.8963), (-0.0728, 0.2179), (-0.3291, 2.7854) | 1.4885 | 3.611 | 1.0082 |
| (0.4, 6) | 21 | 1 | (-0.0612, -0.0326) | 3.1290 | 3.4694 | 0.5825 |
| (0.4, 8) | 34 | 1 | (-0.0883, -0.0065) | 3.1468 | 3.4805 | 0.8204 |
| (0.4, 10) | 52 | 1 | (-0.1230, 0.0339) | 3.1678 | 3.4902 | 0.8204 |
*Note: The two-dimensional coordinates of the award-winning paper in 1997 are (2.9089, 0.9518). |
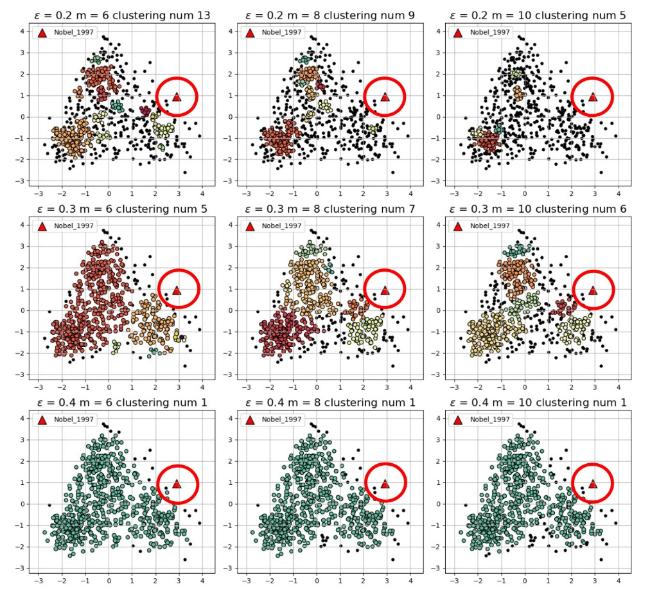
Figure 2. Visualization of outliers in award-winning papers based on DBSCAN with different parameter. |
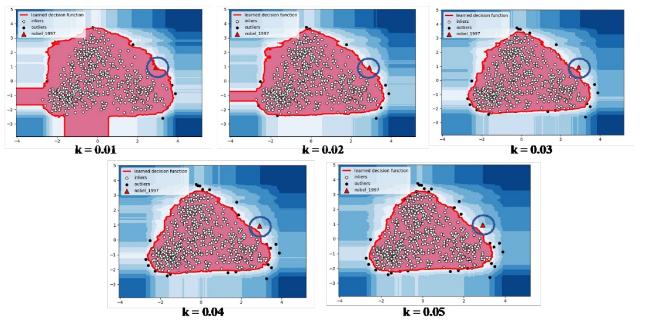
Figure 3. Visualization of outliers in award-winning papers based on Isolation Forest Algorithm with different parameter. |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 4. Evolution of Award-Winning Papers with Optimal Parameter. |
Table 2. Annual and cumulative paper growth in the research field. |
| Publish year | Number of Papers | Cumulative Number of Papers | Publish year | Number of Papers | Cumulative Number of Papers | Publish year | Number of Papers | Cumulative Number of Papers |
|---|---|---|---|---|---|---|---|---|
| 1997 | 582 | 582 | 2006 | 1,264 | 9,430 | 2015 | 1,680 | 23,063 |
| 1998 | 650 | 1,232 | 2007 | 1,390 | 10,820 | 2016 | 1,805 | 24,868 |
| 1999 | 682 | 1,914 | 2008 | 1,491 | 12,311 | 2017 | 1,788 | 26,656 |
| 2000 | 743 | 2,657 | 2009 | 1,399 | 13,710 | 2018 | 1,788 | 28,444 |
| 2001 | 908 | 3,565 | 2010 | 1,560 | 15,270 | 2019 | 1,819 | 30,263 |
| 2002 | 992 | 4,557 | 2011 | 1,519 | 16,789 | 2020 | 1,967 | 32,230 |
| 2003 | 1,182 | 5,739 | 2012 | 1,489 | 18,278 | 2021 | 2,323 | 34,553 |
| 2004 | 1,214 | 6,953 | 2013 | 1,527 | 19,805 | |||
| 2005 | 1,213 | 8,166 | 2014 | 1,578 | 21,383 |
It can be observed that the second paper published in 1998 is relatively close to the first paper when mapped to a two-dimensional plane and is located at the cluster’s edge. By this time, neither paper is an outlier, suggesting that the laureate’s breakthrough discovery may have attracted a small community’s attention. The third related paper published in 2000 shows a similar situation; it is somewhat distanced from the first two papers on the two-dimensional plane but not significantly. As time progresses and more related papers are published, the cluster expands, gradually integrating the three groundbreaking papers. The latter three panels in Figure 4 show the distribution of papers in the field from 2019 to 2021 (the award year), where the three papers have fully merged into the cluster. This phenomenon, as expected, indicates that these papers have become part of “normal science”. Further analysis of articles citing these groundbreaking papers reveals that the breakthrough research has been translated into applications, such as clinical treatments for cancer. This corroborates the observation that the papers eventually merge into the cluster.
4.4 Verification of results
To verify the effectiveness of the proposed method for early identification of scientific breakthroughs through outlier analysis, we analyzed and evaluated the 20 outlier papers from 1997 using the parameters of (0.4, 6), excluding the award-winning paper. By interpreting the abstracts of these papers, we found that the some of them are unrelated to the specific research field of the award-winning paper, such as “Calcium release from intracellular stores evoked by extracellular ATP in a Xenopus renal epithelial cell line”. This may be due to the expanded scope when selecting the control group papers. Additionally, some of these papers include case studies, comparative studies, and review articles that are outside the scope of this study. This indicates a need for more stringent screening of research field papers in future work.
Additionally, we analyzed the impact of outlier papers on subsequent papers published after the first award-winning paper. Specifically, we selected 10 papers from 1998, 1999, and 2000 that were closest to the award-winning paper in terms of distance and analyzed them. After excluding some case studies, comparative studies, and a few review articles, most of the closest 10 papers each year were related to the research content of the award-winning paper. Particularly, as the years progressed, the number of related papers increased. Upon reading these related papers individually, it was found that the research mainly focused on the mechanisms of capsaicin-stimulated sensory nerves (nociceptors), such as “Capsazepine, a vanilloid receptor antagonist, inhibits nicotinic acetylcholine receptors in rat trigeminal ganglia”, “ Similarities and differences between the responses of rat sensory neurons to noxious heat and capsaicin” and “ Capsaicin sensitivity and voltage-gated sodium currents in colon sensory neurons from rat dorsal root ganglia”.
Additionally, the references of these related papers were examined. Among the 10 papers closest to the award-winning paper in 1998, seven were similar in research content, and three cited the award-winning paper. In 1999, seven out of the 10 closest papers were related in content, and five cited the award-winning paper. In 2000, eight out of the 10 closest papers were related in content, and six cited the award-winning paper. It is evident that the number of related papers citing the award-winning paper increased year by year. The subsequent citation of the award-winning paper’s research further indirectly confirms the breakthrough potential of the “outlier” papers.
5 Conclusion
This study proposes a method for early identification of scientific breakthroughs through outlier analysis based on research entities, aiming to expand the current approaches for identifying scientific breakthroughs. Starting from the perspective of outliers, this method targets the “anomalies” that occur on the regular scientific track when breakthroughs appear. Using scientific papers as carriers, it employs semantic technology to extract and represent research entities within the papers. By conducting cluster analysis to observe outlier phenomena in research papers, this method aims to achieve early identification of scientific breakthroughs, and uses time series analysis to track their evolution from outliers to integration into the mainstream. The case study focused on the key publications of the 2021 Nobel Prize laureates in Physiology or Medicine, dynamically observing the impact of the publication of their award-winning papers on the research field through outlier analysis, thereby validating the breakthrough nature of their scientific discoveries. This method can provide a reference for experts to identify scientific breakthroughs promptly, helping to grasp subject dynamics and improve research efficiency. Additionally, it can be applied to the evaluation of innovative scientific literature, offering a more sensitive, precise, and fine-grained alternative to citation-based evaluations, thereby providing valuable supplementary evidence for traditional scientific assessment methods.
From this study, it can be concluded that appropriate methods for delineating the research scope, accurate feature representation, and reasonable experimental approaches are essential for implementing this method. Admittedly, there are some limitations. Theoretically, this method is applicable to all scientific fields, but it has only been empirically tested in the biomedical field. More field data is needed to validate the robustness and generalizability of the method. Furthermore, the research entity recognition model used in this study may extract a large number of entities when identifying key points in abstracts, some of which may not fully correspond to the core content of the papers. Future research, on the one hand, will need to optimize the research entity recognition model to identify key content in abstracts and even full texts. On the other hand, we have to improve the performance of outlier detection. The subsequent work of this study will focus on developing this method into a software to provide a new intelligence analysis tool for relevant personnel, thereby more efficiently supporting technological intelligence decision-making and intelligent intelligence services.
Funding information
This work is supported by the major project of the National Social Science Foundation of China “Big Data-driven Semantic Evaluation System of Science and Technology Literature” (Grant No. 21&ZD329)
Author contributions
Yang Zhao (zhaoyang@mail.las.ac.cn): Conceptualization, Data Curation, Methodology, Investigation, Formal Analysis, Writing - Original Draft, Writing - Review & Editing;
Mengting Zhang (zhangmengting@mail.las.ac.cn): Formal Analysis, Writing - Original Draft, Software, Validation, Visualization;
Xiaoli Chen (chenxl@mail.las.ac.cn): Methodology, Writing - Review & Editing;
Zhixiong Zhang (zhangzhx@mail.las.ac.cn): Conceptualization, Writing - Review & Editing.