

1 Introduction
Research in the domain of natural language processing (NLP), particularly related to text data has become the focus in our world today since the rise of large language models (LLMs) such as Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformer (BERT), Large Language Model Meta AI (Llama), Google Gemini, and others. Such language models have gained worldwide focus due to their widespread use as a conversational tool that helps laymen get a quick answer or generate any text output based on their queries or prompts. As a result, many individuals rely on these tools to complete daily tasks that require simple text generation and summarization. Based on the current performances of LLM as a text-generative tool, it is easy to imply that these models may also work for information extraction (IE) tasks.
Although LLMs are generally good at producing text outputs based on user prompts and inputs, the results are not always precise because the language model only predicts the next word in a sequential order. LLMs are generally used to predict the next word (or masked words) following the inputs and contexts provided using transformers trained with a self-attention mechanism (Hadi et al., 2023). Such language models are created by training massive amounts of general texts available in the public domain. In addition, LLMs are restricted to open-access and open-source texts/materials, which hinders them from crawling closed-source materials. As a result, LLMs are unable to determine whether the text they create contains correct information or may “hallucinate” and produce misleading information (Ji et al., 2023).
The issue of artificial intelligence (AI) and GPT hallucinations has been raised in many experimental studies (Alkaissi & McFarlane, 2023; C. A. Gao et al., 2023; McIntosh et al., 2023), where AI-based text generative tools have been observed to produce realistically coherent, yet misleading text from scattered information, similar to assembling a jigsaw puzzle (Alkaissi & McFarlane, 2023). This situation is referred to as “artificial hallucinations” (Ji et al., 2023), where the models may use ambiguous methods to produce text by combining and reshaping data in new ways to answer user prompts (Li, 2023). This raises concerns regarding the authenticity and trustworthiness of the generated output (Li, 2023). In addition, the proposition of the model faces ethical issues when the New York Times sues OpenAI and Microsoft for using copyrighted materials (Grynbaum & Mac, 2023; Metz & Robertson, 2024).
Besides, retraining deep learning (DL) networks to build LLMs is computationally expensive. It requires extensive computational power due to the exponential increase in the number of parameters as more input text is trained (Talpur et al., 2022). Therefore, such models may not perform very well compared with models that have been specially trained for IE tasks on domain-specific texts. Furthermore, J. Gao et al. (2023) revealed that LLMs are excellent for generating text output based on queries for general tasks; however, they do not perform well for complex tasks such as event extraction from text. The authors concluded that transformer-based models are not sufficiently robust for task-specific and complex scenarios. A series of experiments in this study revealed that ChatGPT could only achieve an average of 51.04% on task-specific models such as event extraction by question answering (EEQA).
According to J. Gao et al. (2023), the underperformance of the LLM can be caused by the model’s inability to interpret specific event definitions, thus resulting in the extraction of more event triggers than actual triggers present in the text. Their results show that GPT models perform significantly worse than baseline models in long-tail and complex scenarios, where more than one event exists in a sentence. Second, the GPT model may not be able to recognize the context of negative samples, leading to their perception as positive samples. This can be seen from the improved performance when “negative events” were removed from the prompts, which is consistent with the findings by Wang et al. (2022).
Therefore, the issue of IE from text documents, particularly in event extraction tasks, poses a critical challenge that needs to be addressed using a dedicated approach. The LLM-based model alone is insufficient to provide accurate event extraction from text due to poor generalization of domain-specific information (Abdullah, Aziz, Abdulkadir, Alhussian, et al., 2023; Adnan & Akbar, 2019b) and unable to fully understand complex extraction tasks (J. Gao et al., 2023). In addition, the lack of a carefully annotated corpus has caused a significant bottleneck in the implementation of NLP algorithms. This situation results in a critical need for a high-quality text corpus to fulfill this purpose. Annotated corpora have been largely applied in areas such as clinical texts (Pestian et al., 2007) and biomedical texts (Cohen et al., 2017; Deléger et al., 2016; Kim et al., 2003; Ohta et al., 2011; Ohta et al., 2013; Pyysalo & Ananiadou, 2013; Pyysalo et al., 2011b). Based on the status quo established above, this study aimed to address the following research questions:
● RQ1: Which corpora are currently accessible for event extraction tasks?
● RQ2: How to prepare a domain-specific annotated corpus?
● RQ3: Which tools are appropriate for annotating a corpus for event extraction tasks?
● RQ4: What information should be annotated in a corpus for event extraction tasks?
Aligned with the research questions above, this study examined the accessibility of data for event extraction tasks and strategies for creating manual annotations on text corpora. Corpus annotation involves using specialized software to annotate parts of the text based on the prepared annotation guidelines. It involves an extremely tedious process executed by domain experts to provide additional linguistic information to an IE algorithm or system. Thus, this study aimed to contribute to the existing knowledge in several ways, including:
● explored and presented an existing corpus for event extraction tasks.
● explored suitable tools for preparing annotated corpora.
● explained the general guidelines for annotating text corpora.
● defined the information that should be annotated.
● defined information that should not be annotated.
According to the authors’ best knowledge, there is no previous study that comprehensively compiled the existing annotated corpora for event extraction tasks and provided guidelines on the methods to prepare them. In terms of contributions, this study provides a thorough understanding and the necessary knowledge for creating an annotated corpus. Therefore, we hope that this study will provide clear guidance for both newcomers and experienced researchers to understand the proper approach to annotating a text corpus using widely accepted procedures.
The remainder of this paper is divided into several sections, each of which serves a specific purpose. Section 2 provides the fundamental concepts and definitions required to understand the event extraction tasks. It draws insights from the existing literature while introducing the currently available event extraction corpora. Section 3 explains the methodology for developing an annotated closed-domain corpus for event extraction tasks. It covers essential aspects, such as the common annotation format, suitable tools for annotation tasks, steps for document selection, and criteria for event annotation. Section 4 comprehensively discusses existing corpora for event extraction and provides insights into their limitations, annotation challenges, potential solutions, and recent advancement of LLMs for corpus annotation. Finally, Section 5 summarizes the main findings and provides recommendations for future research in the field of event extraction.
2 Fundamentals of corpus annotation and event extraction
A corpus (plural: corpora) is a linguistic resource composed of large amounts of unstructured text in a specific domain. Hence, it is commonly used in linguistics and text-mining research. A corpus contains a large amount of useful information that can be analyzed by training ML algorithms to understand and find hidden information or patterns. However, similar to structured data, unstructured data, such as text, need to be processed and labeled before they can be used for supervised training. The process of labeling a text corpus is known as annotation. Once annotated, a corpus becomes a highly valuable resource for developing knowledge graphs (KG) and training ML models to detect patterns for event extraction tasks. In general, there are two strategies for creating annotated corpora: (i) automatic corpus annotation using an ML-based text tagger, and (ii) manual corpus annotation using text annotation tools (explained in Section 3) (O’Donnell, 2008). Some researchers may also adopt a combination of both methods, which is referred to as semi-automatic corpus annotation.
The automatic corpus annotation method was introduced to automate the process of corpus annotation, thereby reducing the time and effort required by annotators to manually annotate text (Akmal & Romadhony, 2020; Wu et al., 2020). In automatic annotation, ML algorithms are used to learn document-level and sentence-level features, such as contextual and lexical features from large amounts of annotated texts (Abdullah, Aziz, Abdulkadir, Alhussian, et al., 2023; Vauth et al., 2021). Recent studies (Csanády et al., 2024; Frei & Kramer, 2023; Li et al., 2023) presented a method to automate corpus annotation using advanced methods such as LLMs. However, these studies are limited to LLM applications for corpus annotation in NER tasks. Although automatic corpus annotation is feasible, it is typically confined to annotating simpler information, such as named entities (Adnan et al., 2019). This limitation is due to the risk of introducing noise into the data, which can render the corpora unreliable. Additionally, automatic corpus annotation becomes much more challenging when dealing with domain-specific texts, such as in medical, chemical, legal, aviation, and other industries.
Thus, manual corpus annotation remains a more suitable strategy for domain-specific texts, as it involves domain experts to manually hand-label text during the annotation process. Domain experts can ensure the correctness and truthfulness of the annotations, making manually annotated corpora more reliable than those created via automatic annotation methods. Despite its labor-intensive nature, manual annotation yields gold-quality annotated corpora suitable for benchmarking purposes. This reliability is crucial, especially when the data come from sources with unknown truth, such as social media data, which may contain false information for ML models to learn. Although manual annotation is a tedious and time-consuming task (Akmal & Romadhony, 2020; Wu et al., 2020), it is an excellent way to ensure that the corpus is annotated correctly and helps maintain the annotations in sync with the context of its domain. Consequently, manually annotated corpora are preferred for training extraction systems due to their accuracy and reliability.
To better understand the technique of event detection from a corpus, it is essential to establish a clear definition of an event. According to the Oxford Advanced Learner’s Dictionary, an event is defined as “a thing that happens, especially something important.” Kim et al. (2008) defined an event as a change in the state, properties, or location of an entity. Combining these definitions, an event can be characterized as a change in the state, attributes, or location of an entity, particularly changes that are considered important or have a noticeable impact. This definition guides us in determining which information to annotate from a corpus. Hence, when annotating a text corpus, it is important to keep in mind that any part of the text that explains changes in the state, characteristics, or location of an entity can indicate the presence of an event. To understand event detection, it is necessary to first grasp the concept of trigger words and their significance in identifying events from text corpora.
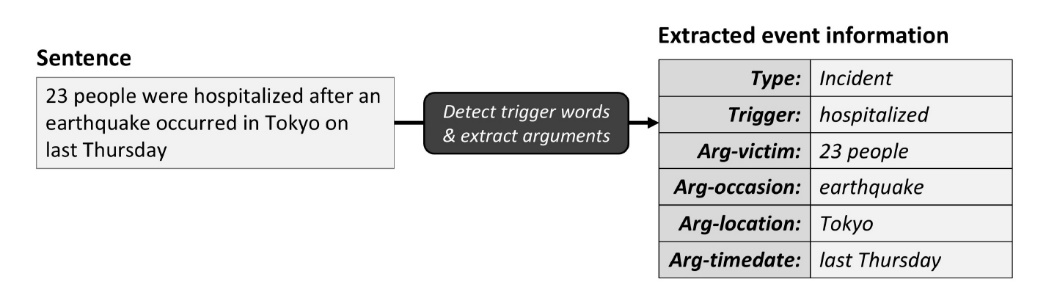
Trigger words are words that indicate the possibility of an event occurring in a text corpus. Thus, most event detection mechanisms rely on trigger words to provide a clue for the detection of events in a text corpus (Abdullah, Aziz, Abdulkadir, Akhir, et al., 2022). For example, given the sentence “23 people were hospitalized after an earthquake occurred in Tokyo on Thursday,” the word “hospitalized” serves as a trigger word (clue) to indicate the presence of an event in the sentence. Once a trigger word is detected, the event extraction mechanism needs to determine the event class. From the sentence given, the trigger word “hospitalized” helps to determine the event as a type of “incident”. However, event detection using ML or DL approach requires a large annotated corpus for training in order to understand the generalization of events in a textual context. One way to extract event-related details is to use an event extraction schema. Figure 1 shows the mechanism used to detect and extract event-related information from text using a predefined schema for a closed-domain event extraction task.
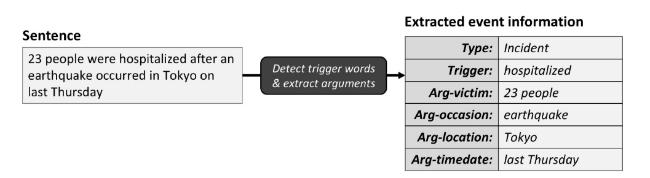
Figure 1. Example of a closed-domain EE using a predefined event schema. |
Event detection (ED) and event extraction (EE) tasks can be categorized into two main types: open-domain event extraction and closed-domain event extraction. Open-domain EE systems are used to locate and gather data on events originating from general domain sources. The main focus of open-domain EE is to extract the event occurrence and determine the type of event itself (Adnan et al., 2019). Conversely, closed-domain EE systems are used to handle events from a specific domain since they utilize a predetermined event schema for the extraction procedure, such as security, justice, finance, biological activities, and chemical reactions. A few studies (Abdullah, Aziz, Abdulkadir, Alhussian, et al., 2023; Adnan & Akbar, 2019a) provided in-depth explanations of event extraction methods from unstructured text data. The next subsection provides details of existing corpora suitable for event extraction tasks.
2.1 Existing corpus for event extraction tasks
Data serve as an essential component in training ML models. Consequently, many commercial and open-source research groups have curated manually annotated corpora specifically designed for training event extraction models. However, it is important to note that while many of these annotated corpora are freely available, some were developed for commercial purposes and thus will require a license purchase for access. Access to these corpora is essential for researchers to enhance the accuracy and performance of current event extraction models. Additionally, the availability and accessibility of event extraction corpora play a crucial role in shaping the landscape of ML research and development, particularly in the domain of NLP. Table 1 lists the existing event extraction corpora, thereby addressing RQ1.
Table 1. Annotated corpus for the event extraction task. |
| ID | Corpus Short Name | Corpus Full Name | Domain Area | Language | Corpus Size (# docs) | Annotation Method | Public Access | Charges | Format | Benchmark Corpus |
|---|---|---|---|---|---|---|---|---|---|---|
| C01 | MUSIED | Multi-Source Informal Event Detection | General | Chinese | 11,381 | Manual | √ | Free of charge | JSON | × |
| C02 | MAVEN | MAssive eVENt detection dataset | General | English | 4,480 | Manual | √ | Free of charge | JSON | √ |
| C03 | ACE 2005 | ACE 2005 Multilingual Training Corpus1 | General | English, Chinese | 599 (En), 633 (Ch) | Manual | × | Licensed (Paid) | XML | √ |
| C04 | CFEE | Chinese Financial Event Extraction | Finance | Chinese | 2,976 | Automatic | √ | Free of charge | JSON | √ |
| C05 | ChFinAnn | ChFinAnn | Finance | Chinese | 32,040 | Manual | √ | Free of charge | JSON | √ |
| C06 | FEED | Chinese Financial Event Extraction Dataset | Finance | Chinese | 31,748 | Automatic & manual | √ | Free of charge | JSON | × |
| C07 | EPI | Epigenetics and Post-Translational Modifications 2011 | Biomedical | English | 1,200 | Manual | × | Free of charge | BioNLP Standoff | √ |
| C08 | ID | Infectious Diseases 20112 | Biomedical | English | 30 | Manual | √ | Free of charge | BioNLP Standoff | √ |
| C09 | GE 11 | Genia Event Extraction 2011 | Biomedical | English | 1,210 | Manual | √ | Free of charge | BioNLP Standoff | √ |
| C10 | PC | Pathway Curation 2013 | Biomedical | English | 525 | Manual | √ | Free of charge | BioNLP Standoff | √ |
| C11 | CG | Cancer Genetics 2013 (CG) | Biomedical | English | 600 | Manual | √ | Free of charge | BioNLP Standoff | √ |
| C12 | BB3 | Bacteria Biotope 2016 | Biomedical | English | 215 | Manual | × | Free of charge | BioNLP Standoff | √ |
| C13 | MLEE | Multi-Level Event Extraction | Biomedical | English | 262 | Manual | √ | Free of charge | BRAT Standoff, CoNLL-U | √ |
| C14 | LEVEN | Large-Scale Chinese Legal Event Detection Dataset | Legal | Chinese | 8,116 | Automatic & manual | √ | Free of charge | JSON | √ |
1 The ACE 2005 (Arabic) corpus is excluded since it is not supported for the event extraction task. 2 The size of the ID corpus is relatively small since the number reflects count of full text documents, instead of only abstracts |
2.1.1 General domain corpora
MUSIED is a general domain event detection corpus that contains informal texts. The corpus was first introduced in a study by Xi et al. (2022) as a Chinese language resource, along with benchmarking results using four different models. In contrast to other corpora, MUSIED presents distinct challenges due to the unique characteristics of informal texts sourced from Chinese e-commerce platforms, which makes event extraction tasks from the corpus even more difficult. It consists of user reviews, text chats, and phone calls. This demonstrates the complexity of multi-source informal event detection, which is still an open subject that requires additional effort. The corpus contains text from 11,381 documents, with 7.105 million tokens, 315,743 sentences, 35,313 event mentions, and 21 event types. This massive amount of text makes MUSIED one of the largest annotated text corpora in Chinese. The corpus and benchmark models are made available from the GitHub repository at https://github.com/myeclipse/MUSIED (retrieved: 1 August 2024).
MAVEN stands for a MAssive eVENt detection dataset. Wang et al. (2020) introduced the massive English corpus to address the issue of scarcity (very limited and small-sized corpus) and low coverage (limited event types) of text corpora, which are insufficient for training modern DL-based event extraction models and hinder stable benchmarking of the models. The corpus contains 4,480 documents, 1.276 million tokens, 49,873 sentences, 118,732 event mentions, 497,261 negative events, and 168 event types originating from English Wikipedia articles. The result of MAVEN corpus benchmarking against smaller datasets demonstrates that event extraction remains a difficult task and requires additional research efforts. MAVEN corpus is available for download from the GitHub repository at https://github.com/THU-KEG/MAVEN-dataset (retrieved: 1 August 2024).
ACE 2005 Multilingual Training Corpus (LDC2006T06) is a popular benchmark corpus for NLP and IE challenges, including event extraction tasks (Walker et al., 2006). The corpus was released in 2006 and contains data from a variety of sources, including broadcast conversations, broadcast news, newsgroups, phone dialogues, and weblogs. It contains text from three languages: English, Mandarin, Chinese, and Standard Arabic. However, the corpus for event extraction tasks is only available in two languages: English and Chinese. ACE 2005 (English) contains text from 599 documents, 303,000 tokens, 15,789 sentences, and 5,349 event mentions. Meanwhile, ACE 2005 (Chinese) has 633 documents, 321,000 tokens, 7,269 sentences, and 3,333 event mentions. The event-related tasks cover five event types: interaction, movement, transfer, creation, and destruction. The corpus is stored as four files, which include source text in UTF-8 encoding (.sgm), the official ACE annotation file (.apf.xml), the annotation files created using the LDC annotation toolkit (.ag. xml) and mapping tables between the IDs in the ag.xml files and their corresponding apf.xml files (.tab). The corpus is not available to the public and is only available to Linguistic Data Consortium (LDC) members or through license purchase for non-members via https://doi.org/10.35111/mwxc-vh88 (retrieved: 1 August 2024).
2.1.2 Financial domain corpora
CFEE or the Chinese Financial Event Extraction corpus was introduced by Yang et al. (2018) using an automatic labeling method. The original text data are sourced from the official announcements released by companies and obtained from Sohu Securities website①(① https://investors.sohu.com (retrieved: 1 August 2024)). This financial domain Chinese corpus comprises 2,976 documents, 3,044 event instances, and 32,936 negative event instances, focusing on four event types: Equity Pledge (EP), Equity Overweight (EO), Equity Repurchase (ER), and Equity Freeze (EF). CFEE promises two challenges: (i) sentence-level event extraction, and (ii) document-level event extraction. The corpus is available for download from the GitHub repository at https://github.com/yanghang111/DCFEE (retrieved: 1 August 2024).
ChFinAnn is a large-scale Chinese financial event extraction corpus that contains official announcements of publicly listed companies on the Chinese stock market from 2008 to 2018 (Zheng et al., 2019). The data source is crawled from CnInfo website②(② http://www.cninfo.com.cn/ (retrieved: 1 August 2024)) to get the financial announcements of listed companies in China. The corpus covers 32,040 documents, with an average of 20 sentences per document, 912 tokens per document on average (Xu et al., 2021), and a total of more than 40 thousand event mentions. The documents were randomly divided into 80% training set, 10% development set, and 10% testing set, with events classified into five event types: EP, EO, ER, EF, and Equity Underweight (EU). This is approximately 10 times larger than the CFEE corpus and 53 times larger than the ACE 2005 corpus. Due to its huge size, this corpus presents various issues, including multiple event detection within or across sentences, as well as event arguments spread across multiple sentences. The corpus is available from the GitHub repository https://github.com/dolphin-zs/Doc2EDAG (retrieved: 1 August 2024).
FEED is an open large-scale Chinese Financial Event Extraction Dataset constructed using an automatic annotation method with distant supervision. The data source for this corpus is the Chinese financial portal East Money③(③ https://www.eastmoney.com/ (retrieved: 1 August 2024)), which contains announcements from Chinese financial firms from 2008 to 2018. The corpus contains 31,748 documents, with 900 documents manually annotated to ensure their quality (Li et al., 2022), while the remaining 30,848 documents were automatically annotated. Each document contains approximately 19 sentences on average. The entire corpus includes 46,960 event mentions and five event types (EP, EO, ER, EF, and EU). The corpus can be downloaded from a GitHub repository at https://github.com/seukgcode/FEED (retrieved: 1 August 2024).
2.1.3 Biomedical domain corpora
Epigenetics and Post-Translational Modifications (EPI) is one of the event extraction tasks published under the BioNLP 2011 Shared Task, focusing on events that are essential for control or gene expression and protein functions, which include epigenetic changes and protein post-translational modifications (Ohta et al., 2011; Pyysalo, Ohta, Rak, et al., 2012). EPI task corpus was manually annotated from PubMed abstracts, targeting documents related to “DNA methylation” and “prominent PTM types”. The corpus consists of 1,200 abstracts, 253,628 tokens, 3,714 events, 369 event modifications, and eight event types. The dataset is provided in BioNLP Standoff format. The full annotated corpus is no longer available due to a broken link, however, the description of the corpus and sample data are still available at https://2011.bionlp-st.org/bionlp-shared-task-2011/epigenetics-and-post-translational-modifications-task-epi/ (retrieved: 1 August 2024).
Infectious Diseases 2011 (ID 2011) is an event extraction corpus manually annotated by the Tsujii laboratory team in the biomedical area (Pyysalo et al., 2011b). The team compiled the corpus from 30 full-text articles encompassing 10 types of biochemical activities related to infectious diseases, which consist of 153,153 tokens, 5,118 sentences, 12,740 entities, 5,150 events, and 214 event modifications. The 30 full-text articles make up approximately 800 PubMed abstracts worth of text (Pyysalo, Ohta, Rak, et al., 2012). Manual corpus annotation was completed in two stages: first entity annotation and second event annotation (focusing on event and event modifications), following a specific corpus annotation guideline (Pyysalo et al., 2011a). The annotation is completed without the use of automatic annotation tools to avoid potential bias. The corpus was divided into training, development, and test sets in a 3:1:2 ratio, with the training set containing approximately 50% of the overall text. The low ratio of the training set in the ID 2011 corpus indicates a greater challenge for the event extraction task. The corpus is provided in the BioNLP Standoff format, available from https://2011.bionlp-st.org/bionlp-shared-task-2011/infectious-diseases-task-id (retrieved: 1 August 2024).
Genia Event Extraction 2011 (GE 11) is a biomedical corpus published as part of the BioNLP-ST 2011 challenge (Kim et al., 2011). It contains a collection of biomedical literature compiled from 1,210 Medline abstracts, 267,229 tokens, 13,603 events, and nine event types. The corpus was manually annotated by a team of domain experts to facilitate the development and evaluation of IE systems in the molecular biology field. The ratio of events to words in abstracts is 5.09%, while events to entities (protein) is 90.87%. This demonstrates that event occurrences are closely tied to entities. The corpus and its evaluation tools are available for download at https://bionlp-st.dbcls.jp/GE/2011/downloads/ (retrieved: 1 August 2024).
Pathway Curation (PC) is prepared as an event extraction corpus that poses a challenge for the extraction of biomolecular reaction events from text (Ohta et al., 2013). The main objective of this task is to extract the event and its structures, which may be connected to several entities and other events. This challenge can also be defined as a multiple event detection problem and nested event detection from a corpus of 21 event types. The base entity in this corpus was tagged automatically using a NER entity mention tagger, while the event and event modifications are fully manually annotated using the BRAT annotation tool by a group of domain experts from the National Center for Text Mining (NaCTeM) and Korea Institute of Science and Technology Information (KISTI) to ensure quality and consistency of the annotations (Ohta et al., 2013). The PC task is composed of text from 525 documents, 108,356 tokens, 15,901 entities, 12,125 events, and 571 event modifications. The corpus remains an open challenge and its resources are available in the BioNLP Standoff format from https://2013.bionlp-st.org/tasks/pathway-curation-pc-task (retrieved: 1 August 2024).
Cancer Genetics (CG) is an event extraction corpus involving 18 entities and 40 event types from 600 abstracts, 129,878 tokens, 17,248 event mentions, and 1,326 event modifications (Pyysalo et al., 2013). The corpus was released as part of the BioNLP open challenge to accelerate research in the field of event extraction from text, particularly related to the extraction of biological process events in cancer development and progression. It was prepared by Tomako Ohta, who is a domain expert PhD biologist with expertise in event annotation tasks. First, the entity annotations were carried out using a custom automated NER pipeline, before it was manually verified to finalize the annotations, as described in Stenetorp et al. (2011). Next, the events were manually annotated using the BRAT annotation tool to minimize any potential bias, following the corpus annotation guidelines established by Pyysalo, Ohta, Miwa, et al. (2012). This annotated corpus presents a challenge for event extraction, with 50% of the data split for the training set, 17% retained for the development set, and 33% for testing. The CG corpus is provided in the BioNLP Standoff format, and the related materials can be downloaded from https://2013.bionlp-st.org/tasks/cancer-genetics-cg-task (retrieved: 1 August 2024).
Bacteria Biotope 2016 (BB3) corpus is an open task released under the BioNLP-ST 2016 challenge, with the aim of extracting information about bacterial biotopes and phenotypes. The BB3 tasks consist of three subtasks:(i) CC-cat and BB-cat+ner, (ii) BB-event and BB-event+ner, and (iii) BB-kb and BB-kb+ner. The cat and cat+ner subtasks focus on categorization, the event and event+ner on event extraction, and the kb and bb+ner on knowledgebase population. In this study, we emphasize the BB-event and BB-event+ner subtasks, with the primary goal of extracting events and named entities from text. The BB-event task provides text resources from 146 PubMed abstracts, totaling 35,380 tokens and 890 event mentions. Meanwhile, the BB-event+ner is derived from 161 PubMed abstracts, containing 39,118 tokens, and 864 event mentions. Both event-related tasks are annotated to link two categories of events. The BB3 corpus has been manually annotated on the AlvisAE annotation editor (Papazian et al., 2012) by a group of seven domain-expert annotators with diverse expertise (Deléger et al., 2016). The corpus presents researchers with the complexity and challenge of sentence-level event extraction, as well as intra- and inter-sentence event extraction. Resources related to this corpus are no longer available due to broken links, however, the corpus description is still accessible at https://2016.bionlp-st.org/tasks/bb3/ (retrieved: 1 August 2024).
Multi-Level Event Extraction (MLEE) is a corpus manually annotated by a PhD biologist domain expert using the BRAT annotation tool (Stenetorp et al., 2012) in the Standoff format. The corpus contains 262 documents, 56,588 tokens, 2,608 sentences, 29 event types, and 6,677 event mentions from abstracts published on angiogenesis, the process of developing new blood vessels from existing ones (Pyysalo, Ohta, Miwa, et al., 2012). Previous biomedical corpora typically present a difficulty for molecular-level event extraction. The MLEE corpus presents new challenges, such as multi-level event extraction, which includes extracting events on multiple levels. Event annotations in the MLEE corpus not only cover the molecular-level events, but also cellular, tissue, and organ-level events. This includes annotations on biological processes that produce organism-level effects, which are the primary interest in most biomedical research. The corpus and its descriptions are available from https://nactem.ac.uk/MLEE/ (retrieved: 1 August 2024).
2.1.4 Legal domain corpus
Large-Scale Chinese Legal Event Detection Dataset (LEVEN) is a Chinese annotated corpus containing the essential facts required to prove a case in a court of law (Yao et al., 2022). Thus, this corpus provides a fundamental challenge in understanding and identifying events from texts in the legal domain. The LEVEN corpus consists of 8,116 documents with over 2.241 million tokens, 63,616 sentences, 150,977 event mentions, and 108 event types. It is one of the largest annotated corpora available to date and includes 64 charge-oriented events and 44 general events. The LEVEN annotated corpus has been tested with DMCNN, BiLSTM, BiLSTM+CRF, BERT, BERT+CRF, and DMBERT baseline models. Despite the use of advanced event extraction methods, the LEVEN corpus has more to offer. The best-performing model, DMCNN, achieved a training precision of 85.88% with a ±0.70 tolerance, whereas DMBERT achieved 86.22% with ± 0.77 tolerance and 85.48% with ±0.18 tolerance for micro-recall and F1 score. Meanwhile, for model testing, the DMBERT model performs the best with 81.57% with ±1.04 tolerance, 80.90% with ±1.38 tolerance, and 80.34% with ±0.74 tolerance for precision, micro-recall, and F1 score, respectively. The corpus is available at https://github.com/thunlp/LEVEN/ (retrieved: 1 August 2024). The corpus was adopted for the Challenge of AI in Law (CAIL 2022)④(④ http://cail.cipsc.org.cn/ (retreived: 1 August 2024)) competition.
3 Developing a closed-domain annotated corpus for event extraction tasks
A text corpus can be annotated through linguistic and biological annotation (Kim et al., 2008). Linguistic annotation can be done by using language features through POS-tagging, shallow annotation, or deep annotation. Biological annotation, on the other hand, involves annotating biological events in a text corpus. The annotated corpus is curated specifically for the Named Entity Recognition (NER), Relation Extraction (RE), or Event Extraction (EE) tasks. Once a corpus is correctly annotated, ML algorithms can be used to learn the annotation pattern and thus help to recognize such features from the text. Since this study is focused on the event extraction corpus, the previously established definition of events will be referred to as it will help researchers to annotate the corpus correctly. This section aims to answer RQ2, with Figure 2 illustrating the process of creating an annotated corpus through a flowchart.
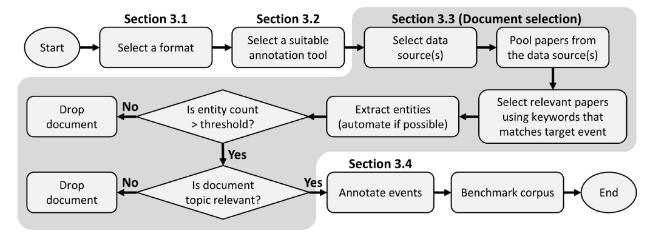
Figure 2. Flowchart of the manual corpus annotation procedure. |
The process of creating an annotated corpus begins with the selection of a suitable annotation format. The usual format for creating an annotated corpus is explained in more detail in Section 3.1. Once the annotation format is defined, the annotators must select an annotation tool for the creation of the corpus annotation (see Section 3.2). The process then continues with the document selection, as explained in Section 3.3. This begins with the selection of data sources that contain large amounts of text data with event occurrence information that can be annotated. Common sources for large amounts of text are freely accessible newspapers, forums, blogs, articles, reports, and news feeds, which are publicly available and do not require permission to use to avoid copyright issues. Once a suitable data source has been identified, the next step is to pool the text resources from the source.
The amount of text data to be pooled depends on the size of the annotated corpus to be created. Next, we can select only relevant data from the pooled text data gathered from the source by searching for keywords that match the target event. For example, if the corpus to be created is to be used for tagging chemical reactions and processes, the keyword that matches the target event must be related to the specific terms used to describe chemical reactions and processes involved. Thus, a list of documents containing only the exact event information is required for the annotation process. As is generally known, an event is inextricably linked to entities.
Thus, the next step in the corpus annotation pipeline is to annotate all entities present in each document. This method can be performed either automatically (using NER tagger tools, if possible), semi-automatically, or manually if the entities involved are very domain-specific and cannot be recognized by normal NER tagger tools. In order to include only relevant documents with sufficient references to events, document selection criteria must be used. If the number of entities in a document exceeds the minimum threshold, the document will proceed to the next phase; otherwise, it will be excluded. Next, the passing documents are manually or semi-automatically reviewed to determine whether they are related to the topic of interest.
After annotating the corpus with entities and selecting only relevant documents, it is time to annotate the events (Section 3.4). The general rules for annotating events can be found in Subsection 3.4.1, the elements of event annotation in Subsection 3.4.2, information that should be annotated in Subsection 3.4.3, and information that should not be annotated in Subsection 3.4.4. Finally, the complete annotated corpus must be benchmarked using event extraction models before it is made available to the public.
3.1 Common text annotation formats
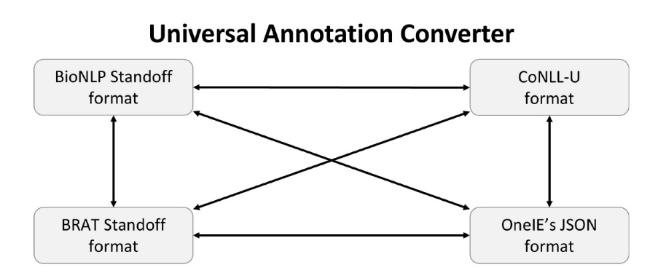
According to Zaman et al. (2020), one of the most prominent challenges in IE from unstructured data, such as text, is the lack of a standard approach for all domains. Since there are various ways to annotate text data, researchers often use their propriety method to annotate corpora. This leads to inconsistencies and incompatibility issues, which overwhelm researchers. Currently, there are many formats for annotating text data, but the four most commonly used formats are (i) the BioNLP Standoff format, (ii) the BRAT Standoff format, (iii) the CoNLL-U format, and (iv) the OneIE’s JSON format. The annotation structures for each format are explained below.
BioNLP Standoff format is a text annotation format commonly used in BioNLP Shared Task and BioNLP Open Shared Task challenges. The structure for this annotation format is composed of three files with the raw text of each document given as a text (.txt file), while the annotations are stored separately as entity annotation (.a1 file) and event annotation (.a2 file). All annotation files follow the same structure, with each annotation assigned an ID that begins with a specific letter (e.g. “T” for text-bound entity or trigger word, “E” for event, “R” for relations, “M” for modifications, “N” for normalization, and an asterisk “*” for equivalent terms). These annotations are encoded as tab-delimited text files. Note that any ID beginning with the character “T” in the entity annotation file stands for entities, while any ID beginning with the character “T” in the event annotation file stands for an event trigger. The remaining structure of the annotations varies based on the annotation type (e.g. entity, event trigger, event, modifications, normalization, and equivalent terms). A full description of the data is available at https://2011.bionlp-st.org/bionlpshared-task-2011/file-formats/ (retrieved: 1 August 2024). Figure 3 illustrates the structure of the entity and event annotations in the BioNLP Standoff format.
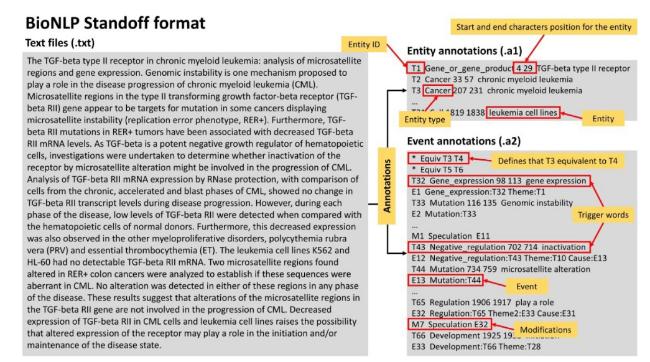
Figure 3. Structure of annotated corpus in the BioNLP Standoff format. |
BRAT Standoff format is the standard format for storing text annotations created with the BRAT annotation tool. This format is similar to the BioNLP Standoff format described above, whereby the annotations are stored separately from the raw document text. The document text is saved as a plain text file (.txt) and is not modified by the tool, while the annotations are stored in a single annotation file (.ann). Each annotation starts on a new line, with the first character defining the annotation type. For example, each line in the annotation file starting with the character “T” defines an entity or event trigger annotation, “E” defines an event annotation, “R” defines relationship annotation, “A” defines an attribute, “M” defines modifications, “N” defines a normalization, and a hash character “#” marks a comment segment or note. In addition, an asterisk “*” is used as a placeholder for an ID in special cases. A comprehensive explanation of the format can be found at https://brat.nlplab.org/standoff.html (retrieved: 1 August 2024). Figure 4 shows the annotation of the corpus according to the BRAT Standoff format.

Figure 4. Structure of annotated corpus in BRAT Standoff format. |
CoNLL-U format is a sentence-level annotation scheme specifically designed to facilitate NLP research (Buchholz & Marsi, 2006). It provides formal linguistic corpora annotations in plain text, with each CoNLL annotation file consisting of three types of lines: comment lines, word lines, and blank lines. Comment lines are marked with a hash sign “#” at the beginning and contain metadata such as the sentence ID and the raw text for each sentence. Word lines contain 10 types of annotations for a single word or token, each separated by a tab character. Lastly, there is a blank line at the end of each sentence level to mark the sentence boundaries. Corpus annotation in CoNLL-U format⑤(⑤ https://universaldependencies.org/format.html (retrieved: 1 August 2024)) can be prepared with Python using the spacy_conll package⑥(⑥ https://spacy.io/universe/project/spacy-conll (retrieved: 1 August 2024)). Figure 5 shows an example of an original text and its annotations in the CoNLL-U format, whereas the description for each annotation unit is given as follows:
● ID: Identifier for the word in a particular sentence
● FORM: Word or punctuation symbol in its current form
● LEMMA: The base or root form of a word or punctuation symbol
● UPOS: Universal part-of-speech tag
● XPOS: Language-specific part-of-speech tag
● FEATS: Morphological features
● HEAD: Syntactic head of the current word
● DEPREL: Universal dependency relationship to HEAD
● DEPS: Improved dependency relations
● MISC: Any additional annotations
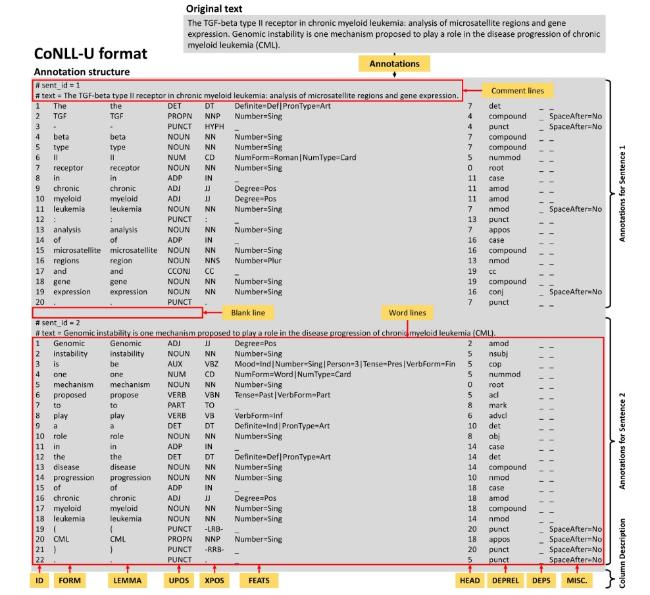
Figure 5. Structure of annotated corpus in the CoNLL-U format. |
OneIE’s JSON format is a structured annotation format used in the OneIE package (Lin, 2020; Lin et al., 2020) for corpus annotation purposes. This format is generally used to provide annotations for multiple sentences in a single JSON file by storing the sentence information and annotations in JSON objects. These JSON objects organize information such as document ID, sentence ID, tokens from the sentence, entity annotations, event annotations, and relation annotations. This format extensively retains all information required for NER, RE, and EE tasks, which makes it suitable as a candidate for being a standard format for annotating text data. Further details on the annotation structure can be found in OneIE’s package documentation⑦(⑦ https://blender.cs.illinois.edu/software/oneie/The_OneIE_Package.pdf (retrieved: 1 August 2024)). It provides a clear guide and extensive details of the structure of the JSON file. The structure of OneIE’s JSON format is illustrated in Figure 6.

Figure 6. Structure of annotated corpus in the OneIE’s JSON format. |
In summary, each annotation format is created by a different team and employs distinct approaches for providing annotation to texts. Most annotation formats, such as BioNLP Standoff and BRAT Standoff, require expert annotators to manually annotate the text. However, the ConLL-U format can be created automatically using a Python package, while OneIE’s JSON format can be prepared using a preprocessing script or manual data transformation. Nonetheless, these formats differ from one another in terms of the annotation structure and the information recorded. Despite these annotation formats are quite easy to use, they can lead to data inconsistency when employed in different extraction systems. Table 2 summarizes each corpus annotation format in tabular form.
Table 2. Comparison summary of the common annotation formats. |
| Annotation Format | Summary | Output Files | Implementation method | Annotation structure |
|---|---|---|---|---|
| BioNLP Standoff | The annotation format is widely used in BioNLP Shared Task and BioNLP Open Shared Task challenges. | .txt .a1 .a2 | Manual annotation using text corpus annotation tool | Tab-delimited data |
| BRAT Standoff | The annotation format is almost identical to the BioNLP format, with the annotations combined into a single annotation file (.ann). | .txt .ann | Manual annotation using text corpus annotation tool | Tab-delimited data |
| CoNLL-U | The sentence-level annotations are presented in three types of lines: comment, word, and blank lines. | .txt .conll | Python’s spacy_conll package | Tab-delimited data |
| OneIE’s JSON format | Provides a comprehensive annotations storage for each sentence in a JSON objects structure. | .JSON | Use OneIE’s package preprocessing script1 or manual data transformation | JSON structure |
1https://github.com/dwadden/dygiepp/tree/master/scripts/data (retrieved: 1 August 2024) |
In addition to the formats listed above, some annotators use proprietary formats to store text annotations, such as JSON/JSONL or XML file structures. This causes incompatibility with other formats. For simplicity and compatibility, we recommend utilizing BioNLP Standoff, BRAT Standoff, CoNLL-U, or OneIE’s format, which are widely used. Using the widely accepted annotation format reduces the incompatibility issues between different IE systems. Nonetheless, various formats may be utilized for a specific application (if required).
3.2 Tools for annotating a text corpus
Once a suitable annotation format is determined, the next step is to choose a compatible annotation tool to annotate the text. This subsection aims to answer the RQ3. Based on our findings, there are various tools available for annotating information from unstructured text. As a result, new researchers may have difficulty determining which tool is most suited for annotating corpora for event extraction tasks. To bridge the gap, Neves and Leser (2012) conducted a survey of annotation tools for biomedical texts and provided insights into the ability and features of each tool for unstructured text annotation. The survey was given new insights by Neves and Ševa (2019), which presented an updated and detailed assessment of tools for manual text annotation. In line with the findings from our exploration, the three most used and recommended tools for annotating a corpus are AlvisAE, BRAT Rapid Annotation Tool, and TextAE. The details of each tool are provided in Table 3.
Table 3. Corpus annotation tools. |
| ID | Tool Name | Platform Compatibility | Output Format | Charges & License Information | Latest Stable Release1 |
|---|---|---|---|---|---|
| T01 | AlvisAE | Web-based (RESTful web app) | JSON | Free (Open Source) No license provided | 2016 |
| T02 | BRAT Rapid Annotation Tool | Web-based (Python package) | BRAT Standoff | Free MIT License | vl.3 Crunchy Frog (Nov 8, 2012) |
| T03 | TextAE | Online/Web-based (Python package) | JSON | Free (Open Source) MIT License | v4.5.4 (Mar 1, 2017) |
1Latest stable release checked on 1 August 2024 |
AlvisAE is a web-based text annotation editor introduced by Papazian et al. (2012) that supports collaborative annotation for group annotators. AlvisAE uses several types of approaches to annotate and various types of annotations: (i) text-bound annotations for defining boundaries for information such as entities and events, (ii) relations annotations for marking relations between entities, and (iii) groups which are collections of annotations, either linked or organized. Currently, the program has been used in several annotation projects from the biology and agricultural sciences, such as the OntoBiotope project (Nédellec et al., 2018) and bacteria gene interactions (Bossy et al., 2012), although it can also be utilized for annotating text from other domains. AlviseAE source code and instructions for deployment can be found on the GitHub repository at https://github.com/openminted/alvisae (retrieved: 1 August 2024). The code needs to be deployed as a web service on a host or server. Once deployed, end users can access the annotation editor via the provided public Uniform Resource Locator (URL). Figure 7 visualizes the user interface of the AlvisAE text annotation editor, which was adapted from Papazian et al. (2012).
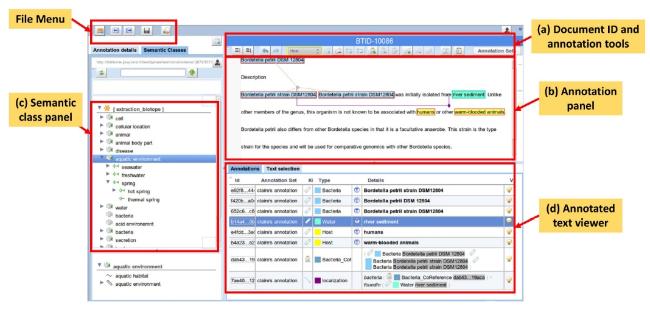
Figure 7. AlvisAE text annotation editor. |
BRAT Rapid Annotation Tool is an efficient web-based application for text corpus annotation, visualization, and editing (Stenetorp et al., 2012). BRAT was built using Python 2, but it is still relevant today due to its cross-platform compatibility. The program can be downloaded and installed easily by deploying its source code to a web server or localhost server. After the installation process is completed, annotators can use the software by navigating to the URL address provided on the command prompt interface. The program is lightweight, accessible through modern web browsers, and has a simple user interface. This offers new users a relatively low to moderate learning curve and allows them to quickly become familiarized with the annotation process. The BRAT annotation tool supports three main types of annotations: entity annotation, event annotation, and relation annotation. It is commonly used to annotate corpora for BioNLP challenges, following the guidelines prepared by Stenetorp et al. (2011). Further information about the BRAT annotation tool is available at http://brat.nlplab.org/ (retrieved: 1 August 2024) and the source code is available from the GitHub repository at https://github.com/nlplab/brat (retrieved: 1 August 2024). Figure 8 shows the user interface of the BRAT annotation tool.
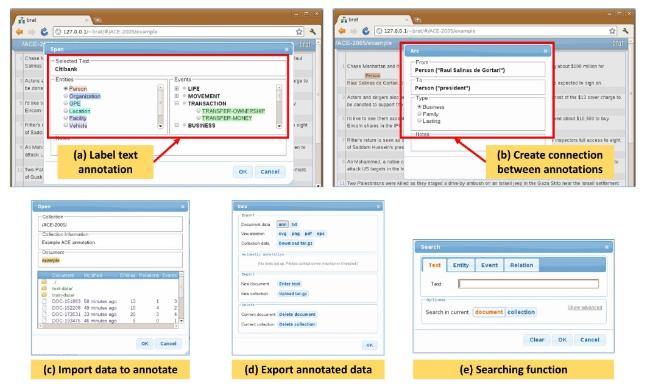
Figure 8. BRAT annotation tool. |
TextAE is an open-source web-based visual editor for text annotation (Lever et al., 2020). The editor features a simple and versatile interface that allows users to annotate text using the What-You-See-Is-What-You-Get (WYSIWYG) editor. TextAE is the default viewer and editor for PubAnnotation. TextAE editor requires no installation and is available online at https://textae.pubannotation.org/ (retrieved: 1 August 2024). Alternatively, the editor can be served on a localhost and accessed via any web browser with the full source code available on a GitHub repository at https://github.com/pubannotation/textae (retrieved: 1 August 2024). Figure 9 shows the user interface of the TextAE annotation editor.
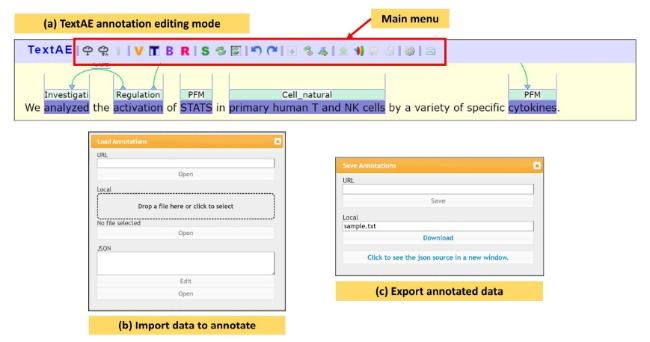
Figure 9. TextAE online text annotation editor. |
Based on our literature review and exploration, the BRAT annotation tool is the most commonly used tool for annotating information from unstructured text. It is popular among annotators as it provides cross-platform access via a web interface and its ability to annotate various types of information. In addition, the annotated corpora can be later exported as high-quality visuals.
3.3 Document selection
This paper examines many studies in order to generalize the common document selection strategies used in the development of a closed-domain text corpus. According to our findings, the document selection strategy used by Ohta et al. (2011), Pyysalo et al. (2013), and Deléger et al. (2016) can be summarized as follows:
1. Select a data source. For example, PubMed is an excellent resource for obtaining biomedical domain abstracts and full text. Once a suitable data source has been discovered, pool papers from the source that contain the identified keywords “DNA methylation” and “prominent PTM types”. These keywords define the search scope for relevant documents from the source.
2. Randomly select papers from the pooled abstracts in Step 1. To only include documents that involve EPI- related events, choose samples tagged with the MeSH word matching the target event (e.g. acetylation). MeSH is a vocabulary used to annotate every PubMed document.
3. Automatically annotate protein or gene entities in selected abstracts. Abstracts containing fewer entities than the predefined threshold were eliminated automatically. Entity annotation is necessary when constructing a corpus for event extraction tasks because event detection requires entity annotations.
4. Next, manually filter documents that are irrelevant to the topic (optional).
5. Finally, manually annotate events following the prepared event annotation guidelines.
The method above can be adopted to develop an annotated corpus for other domains as well. This includes critical domains, such as safety, security, laws, healthcare, and disaster response. The steps listed above are depicted in Figure 10.

Figure 10. Steps for selecting documents to build an event extraction corpus. |
3.4 Event annotation process
Once enough text data have been gathered from the source, the next step will be to randomly split the data into training, development, and testing sets. The size or ratio for each set generally depends on the quantity of data available from the obtained documents, but commonly training set should be the largest subset (Talpur et al., 2023). Some corpora utilize a ratio of 5:3:2 for training, development, and testing sets, respectively (Pyysalo et al., 2011b). The data split must be encoded into the format chosen, based on the specification outlined in Section 3.1 previously. The general rules for annotating events, elements of event annotation, and information that should or should not be annotated are detailed in subsections 3.4.1 until 3.4.4 to answer the RQ4 of this study.
3.4.1 General rules for annotating events
As previously established, an event can be defined as a substantial change in the state, attributes, or location of an entity. This definition serves as a foundational guideline for annotating events within text corpora. In addition to following the official documentation specific to each corpus, the identified event must adhere to the following principles to ensure the consistency and accuracy of corpus annotations:
3.4.2 Elements of event annotation
Unstructured text may contain a variety of elements that reflect various types of information, including events. To construct an annotated corpus for the event extraction task, any events that occur in the text corpus should be annotated according to a corpus annotation guideline. The event-related elements that should be annotated are (Linguistic Data Consortium, 2005; Ohta et al., 2007; Pyysalo et al., 2011a):
● Event: An event frame is identified by its unique ID throughout the document.
● Type: The classification of event type.
● Theme: Links an event with the entity in which the state, properties, or location is changed by the event. The “theme_id” should point to an annotated term or another event.
● Cause: Refers to the entity that influences the occurrence of the event. The “cause_id” should point to an annotated term or another event.
● Clue: Includes trigger words or text fragments that provide hints regarding events in the text.
● Comment: Used to provide remarks related to any text fragments for reference purposes.
The annotation of the elements listed above will help ML models learn the relationships between entities and events. This information can also be represented as a knowledge graph, which allows us to understand the correlations between event elements. Figure 11 shows the events annotated using the BRAT annotation tool.

Figure 11. Example of event annotation using the BRAT annotation tool. |
Note that the annotated text is marked in different colors with lines connecting the annotated elements. Different colors are used to represent the different elements of event annotation from the corpus. The completed annotated corpus will be significant for NLP and text-mining research.
3.4.3 Information that should be annotated
To construct a gold-standard annotated corpus, it is necessary to annotate text representing any individual event, regulatory events, and correlations between events and entities (Lin et al., 2020). An individual event is a type of event that describes a change of state, properties, or location of an entity in a text. Regulatory events, on the other hand, describe a change in the time, frequency, rate, or location of an entity. Lastly, correlations between events and entities represent a causal relationship between entities and events. A causal relationship between entity and events can take the form of nested events, where events are contained within other events. A correct event annotation will ensure that the resulting annotated corpus is of high quality and reliable for analysis.
3.4.4 Information that should not be annotated
There are descriptions in a text corpus that may appear like events, but they are relationship descriptions for the entities in the text. Such text should not be annotated during the event annotation process. Examples of text relationships that should not be annotated are as follows (Consortium, 2005; Ohta et al., 2007; Pyysalo et al., 2011a):
● Static relations between entities are not considered as events; hence, they should not be annotated.
● A smaller part of a whole relationship or structural relationship should not be annotated. Examples:
○ Donator has three accounts.
○ The first account contains four million dollars.
○ Ahmad is a member of the donator group.
● Other than that, some texts should not be annotated, as they do not reflect an event in the text:
○ Expressions that indicate the state after an event.
○ Terms that compare states in activities (i.e. more or less).
○ Terms that represent the degree of the state (i.e. best, worst, poorly, slightly, excellent, low, medium, high, and other indicators).
● Any part of the text that represents inferences (determined using keywords, i.e. indicate, shows).
Text examples, such as those above, should not be annotated to avoid annotation errors, which can result in incorrect ML model training. Therefore, researchers are advised to strictly adhere to the prepared guidelines for event annotation from a text corpus. A detailed example of annotation guidelines includes the ACE 2005 English Annotation Guidelines for Events, available at https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/english-events-guidelines-v5.4.3.pdf (retrieved: 1 August 2024).
4 Discussion
This subsection examines the study findings from several aspects, including the distribution of available text corpora based on languages and domain areas, limitations of the existing corpora, annotation challenges, and potential solutions. First, it is important to note that the text corpora for event extraction tasks are mostly available in two languages: Chinese and English. There may be more event extraction corpora in other languages; however, they are less commonly used. The distribution of the corpus based on language and domain is visualized in Figure 12.

Figure 12. The distribution of corpus based on language and domain. |
Following the figure above, out of the 14 corpora reported in this study, 60% are in English, while the remaining 40% are in Chinese. Within the English corpora, 13% belong to the general domain (equivalent to 22% of all English corpora), while 47% belong to the biomedical domain (equivalent to 78% of all English corpora). Meanwhile, half of the corpora in the Chinese language are from the financial domain, while the other half are split between the general domain and the legal corpus. Notably, there are no English corpora found in the financial domain, highlighting the lack of corpora outside the biomedical domain in English. This disparity poses challenges as NLP problems are highly language-specific. Furthermore, researchers unfamiliar with Chinese will face difficulties in utilizing and validating the experimental results obtained from Chinese corpora. Hence, it is evident that there is a critical need for corpora from various domain areas to significantly improve the performance of state-of-the-art event extraction methods. This includes domains such as law, security, agriculture, natural disasters, and incidents. Expanding the corpus collection across diverse domain areas will enable machines to learn event patterns from a broader range of texts, thus enriching their capabilities for domain-specific event extraction tasks. Table 4 presents a summary of the compiled statistics of the existing event extraction corpora.
Table 4. Corpus statistics. |
| ID | Corpus Name | Data Sources | Tokens Count | Sentences Count | Event Mentions | Negative Events | Event Types |
|---|---|---|---|---|---|---|---|
| C01 | MUSIED | 11,381 docs | 7.105 M | 315,743 | 35,313 | N/A | 21 |
| C02 | MAVEN | 4,480 docs | 1.276 M | 49,873 | 118,732 | 497,261 | 168 |
| C03 | ACE 20051 | 599 docs (En), 633 docs (Ch) | 303k (En), 321k (Ch) | 15,789 (En), 7,269 (Ch) | 5,349 (En), 3,333 (Ch) | N/A | 5 |
| C04 | CFEE | 2,976 docs | N/A | N/A | 3,044 | 32,936 | 4 |
| C05 | ChFinAnn | 32,040 docs | 29,220,480† | 640,800† | > 48,000 | N/A | 5 |
| C06 | FEED | 31,748 docs | 28,954,176† | 603,212† | 46,960 | N/A | 5 |
| C07 | EPI | 1,200 abstracts | 253,628 | N/A | 3,714 | 369 | 8 |
| C08 | ID | 30 full-text articles | 153,153 | 5,118 | 5,150 | 214 | 10 |
| C09 | GE 11 | 1,210 abstracts | 267,229 | N/A | 13,603 | N/A | 9 |
| C10 | PC | 525 docs | 108,356 | N/A | 12,125 | 571 | 21 |
| C11 | CG | 600 abstracts | 129,878 | N/A | 17,248 | 1,326 | 40 |
| C12 | BB3 | 146 abstracts (ee), 161 abstracts (ee+ner) | 35,380 (ee), 39,118 (ee+ner) | N/A | 890 (ee), 864 (ee+ner) | N/A | 2 |
| C13 | MLEE | 262 docs | 56,588 | 2,608 | 6,677 | N/A | 29 |
| C14 | LEVEN | 8,116 docs | 2.241 M | 63,616 | 150,977 | N/A | 108 |
*docs = documents, M = millions, k = thousands, En = English, Cn = Chinese, N/A = not available, †estimated value from calculations, > exceeding 1 The ACE 2005 (Arabic) corpus is excluded since it does not support the event extraction task. |
Note that the majority of English corpora are from the biomedical field, with very few corpora from other domains. These biomedical corpora were offered as part of the BioNLP Shared Tasks in 2011, 2013, and 2016. The token and sentence count in the ChFinAnn and FEED annotated corpora were estimated using the average number of tokens per sentence and the average number of sentences per document available for the corpus. According to the corpus statistics above, some corpora were taken from the abstracts of published studies, while others were sourced from the entire document text. Since the average length of text from abstracts and whole text documents differs, evaluating corpus size solely on the number of data sources is inequitable. Instead, the corpus size can be determined by the total number of tokens (words) and sentences in each corpus. In other words, the more tokens and sentences a corpus contains, the larger it is. Figure 13 presents a bar chart of the top five largest annotated corpora by the number of tokens and sentences. The axis on the left indicates the token count (in millions), while the axis on the right reflects the sentence count (in thousands).
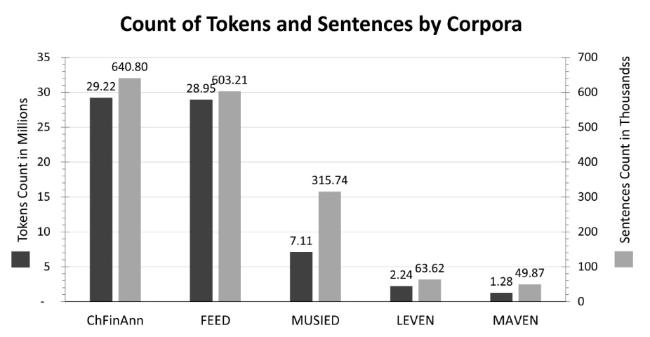
Figure 13. Top five largest annotated corpora for event extraction tasks. |
Among the top five largest annotated corpora for event extraction, the largest three are ChFinAnn, FEED, and MUSIED, each comprising over 7 million tokens and 300 thousand sentences. This is followed by LEVEN which contains 2.24 million tokens and 63.62 thousand sentences, while MAVEN comprises 1.28 million tokens and 49.87 thousand sentences. It is noteworthy that among the top five largest corpora listed above, the largest English annotated corpus ranked last in terms of size, with the top four largest corpora being in Chinese. In terms of token counts, the largest available corpus (ChiFinAnn) is approximately 22.8 times larger than the largest English annotated corpus (MAVEN) and 12.9 times larger in terms of sentence count. This highlights that even the largest English corpus is notably smaller in comparison to the largest accessible corpus known. Therefore, there is a need for additional large-annotated English corpora to enhance event detection algorithms. Additionally, it is crucial to examine the number of event mentions in the corpus relative to the token and sentence counts, as presented in Figure 14.
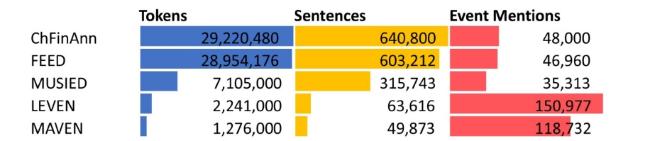
Figure 14. Comparison of tokens, sentences, and event mentions in existing annotated corpora. |
Based on the figure above, the corpora with the highest number of tokens and sentences (ChFinAnn, FEED, and MUSIED) exhibited a lower count of event mentions. In contrast, the LEVEN and MAVEN corpora stand out for their notably higher frequency of event references, surpassing the top three corpora by 4-5 times. This indicates that despite their smaller size, these corpora pose greater challenges for event detection and contain more event mentions that can be utilized to train event detection systems. Consequently, the MAVEN corpus is recognized as an exceptionally large-scale English annotated corpus in a non-biomedical domain, as evidenced by the ratio of tokens/sentences to event mentions. The distribution of event mention counts for all available corpora is shown in Figure 15.

Figure 15. The count of event mentions in each corpus. |
The distribution of event mention counts reveals that LEVEN has the highest number of event mentions, exceeding 150 thousand, while MAVEN follows closely with over 118 thousand event mentions. Despite being ranked last among the top five largest corpora by size (refer to Figure 13 and Figure 14 ), both LEVEN and MAVEN exhibit remarkably high event mention counts. This indicates that these corpora are rich in events, presenting a greater challenge for an event extraction system to detect all event instances. Following this, ChFinAnn, FEED, and MUSIED each contain over 35 thousand event mentions, with the remaining corpora preceding the list.
4.1 Limitations of the existing annotated corpora
One of the fundamental issues in existing corpora is the limited availability of annotated corpora in specific domain areas. This issue can be attributed to the substantial cost of the data annotation process (Yang et al., 2018). In the context of English annotated corpora, there is a noticeable scarcity of corpora across diverse domains, with English corpora largely confined to the biomedical domain. This scarcity becomes evident when examining the data presented in Figure 12 , which reveals that only 22% of all English annotated corpora belong to domains other than biomedical. Subsequently, researchers may encounter difficulties in creating and modifying a personalized event extraction model for a particular domain area without the assistance of domain experts. Because researchers rely on data to run experiments and validate their methods, the significance of annotated corpora in various domains has never been more pronounced.
The second limitation pertains to the accessibility of the existing annotated corpora. Since the majority of English corpora were released a few years ago, some of these repositories are no longer maintained, and the URLs are no longer accessible. This issue is evident in the case of the EPI and BB3 (Table 1 ) corpora for event extraction tasks, which are no longer accessible because of broken links. Consequently, researchers who wish to use these corpora may need to contact individual researchers who have previously used them in their studies to obtain access. Moreover, several benchmark corpora are exclusively accessible to certain group members or are accessible only through license purchases. Upon our investigation, it is important to highlight that high-quality corpus annotations can be published on PubAnnotation website⑧(⑧ https://blender.cs.illinois.edu/software/oneie/The_OneIE_Package.pdf (retrieved: 1 August 2024)) for public download and use. Therefore, we encourage researchers to make high-quality corpora available as open sources for research purposes.
Finally, there is an issue regarding the compatibility of existing annotated corpora for integration into IE systems (Abdullah, Aziz, Abdulkadir, Alhussian, et al., 2023; Adnan & Akbar, 2019b). As stated in Section 3.1, there are four main formats for annotating text data. Because these annotations employ different annotation formats and encoding structures from one another, compatibility issues may arise when working with multiple IE systems. More specifically, the compatibility issue leads to parsing errors when an IE system encounters a corpus with an unsupported format. This limitation restricts researchers from utilizing specific corpora when selecting a particular system to work with and makes it challenging for researchers to benchmark their work against various corpora. There are a few scripts available for converting some of these annotation file formats; however, they are not well documented, and some of them are no longer maintained by their developers.
4.2 Annotation challenges and potential solutions
The first challenge in this domain area is the lack of high-quality annotated data available for event extraction tasks. This problem is rooted in the tedious task of manually annotating a domain-specific text corpus. Manual corpus annotation requires the involvement of domain experts and can take several months to complete because a large amount of data is required to train ML models. Although manual corpus annotation is extremely tedious, it is crucial to ensure that the prepared corpus is of high quality and avoids noise in the annotated data. To address this problem, a hybrid approach can be adopted, as demonstrated by Li et al. (2022) in the preparation of the FEED corpus, which encompasses a total of 31,748 annotated text documents. Li et al. (2022) manually annotated 900 text documents before training ML algorithms to automatically annotate the remaining 30,848 documents. This strategy helps reduce the cost of manually annotating thousands of documents while maintaining the quality of the annotations. Nonetheless, the output of the corpus annotation must be benchmarked to validate the accuracy of the annotation created.
The second challenge is the incompatibility of annotated corpora across various event extraction systems. This issue arises because of the lack of a universally accepted annotation format for all text domains (Zaman et al., 2020). This results in each annotation team utilizing its proprietary format or adopting an existing format for annotation purposes. As a result, the created annotated corpus will not be fully cross-compatible with all IE systems, thus requiring the use of custom-made annotation converters. For example, Liu et al. (2018) created a preprocessing script⑨(⑨ https://github.com/nlpcl-lab/ace2005-preprocessing (retrieved: 1 August 2024)) to transform the ACE 2005 corpus into a specific JSON structure for their experimentation. To address this issue, researchers need to develop a standard annotation format that can be universally accepted for annotating text corpora. This format must be able to contain every piece of information required for common event extraction tasks, such as entities, events, relations, processes, arguments, and other language semantic details. Alternatively, researchers need to develop a universal text annotation convertor that can convert annotations from one format to another, thus solving the compatibility issue, as visualized in Figure 16.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 16. Conceptual representation of the universal text annotation converter. |
The third challenge is to deal with subjectivity and ambiguity in understanding the contextual meaning of the text. Annotators may struggle to maintain annotation consistency since contextual understanding varies from person to person (Mirzakhmedova et al., 2024). According to Xi et al. (2022), the common issues encountered while manually annotating a corpus are subjectivity in candidate selection, boundary confusion, as well as ambiguous expressions from the original text. Another example is that an event of category “incident” might be classed as either an “incident” or “disaster”, depending on the annotator’s perspective. This may lead to inconsistencies during event annotation, resulting in a less accurate ML model trained to extract events from the corpus. To overcome and reduce the impact of this issue, each annotation team should develop a complete annotation guideline that includes a precise description for each term and event, and strictly adhere to it throughout the annotation process. Furthermore, tools like Git version control can be used to add an extra layer of protection against any broken changes by securely keeping backups of annotation versions in repository servers. This also prevents merging conflicts when combining several annotation files from multiple annotators. Table 5 summarizes the challenges and suggested solutions for better clarity and readability.
Table 5. Summary of challenges and recommendations. |
| Challenges | Recommendations |
|---|---|
| Lack of high-quality annotated data | ·To facilitate the rapid development of an annotated corpus, it is suggested to employ a hybrid approach as demonstrated by Li et al. (2022). ·This involves partially annotating the texts manually, and then training ML algorithms to annotate the remaining data based on the trained model. ·This strategy is faster than manually annotating all data. However, it is critical to measure the accuracy of the automatic annotations. |
| Incompatibility of annotated corpus formats | ·Develop a standardized annotation format that is universally accepted for annotating text corpus. ·These formats should store all information required for common EE tasks. ·Develop a universal text annotation converter for converting annotations between different formats ( |
| Subjectivity and text ambiguity | ·Develop a complete annotation guideline and strictly adhere to it throughout the annotation process. ·Utilize tools like Git version control to manage the version of annotation files. |
4.3 Recent advancement of LLMs for corpus annotation
Recent advances in the NLP field have led to breakthroughs in LLMs. Many people today rely on the applications of LLMs, such as GPT, BERT, and Llama for daily routine tasks, such as document and text preparation. Generally, LLMs thrive at handling many text-related tasks, such as text generation and summarization. However, this technology is still emerging, and it has not been thoroughly benchmarked for corpus annotation tasks. Hence, this has led us to question whether LLMs are suitable as a tool for automating corpus annotation tasks. This subsection explores the potential and limitations of LLMs in the context of corpus annotation.
To further investigate this, studies have explored several strategies to leverage LLMs for corpus annotation purposes. For instance, a recent study by Csanády et al. (2024) presented hybrid LLMs and smaller-scale transformer encoders called LlamBERT in an attempt to prepare automatic corpus annotation for the NER corpus. This study utilized two IMDb review datasets to demonstrate the potential applications of LLMs as annotation tools. The result suggests that the proposed strategy is efficient in annotating large amounts of text; however, the accuracy is compromised to provide cost-effectiveness. The authors suggested combining the output model with gold-standard data to yield better results, indicating that LLMs alone are not good enough to create high-quality annotations. Since the model is designed for entity annotation, the output annotated corpus is not suitable for event extraction.
In another study, Akkurt et al. (2024) demonstrated the capability of LLMs to provide annotations for Turkish and English Universal Dependencies (UD) treebanks. The focus of their study was to compare the annotations in the two different versions of the treebank with the expectation of a better annotation scheme and a high success rate. The result shows a successful recovery of approximately 2% higher, with all models showing improved performance. However, there are several issues with this method: (i) the annotation outcome can vary depending on the specificity of the user’s prompt, and (ii) the output of corpus annotation is designed for annotating named entities for NER tasks. Therefore, this approach is not compatible with annotations for event extraction tasks.
On the other hand, Frei and Kramer (2023) presented an approach to create an annotated dataset using LLMs for non-English medical NLP. The study aimed to solve the problem of limited availability of annotated corpora in German medical texts by leveraging the capability of LLM for text annotation tasks. This demonstrates the training of LLM to obtain German medical texts as a synthesis dataset for NER tasks (although the method can be applied to other languages as well). Their findings show that although the validation of the NER model generally shows a strong performance, the annotations are valid for use. However, the proposed method is computationally expensive, and the dataset itself remains synthetic in nature; thus, it cannot be considered a gold-standard corpus. The study then emphasizes the need for additional validation on the LLM-annotated corpus, such as manual inspection and annotation, to reduce uncertainty.
Lastly, Li et al. (2023) presented a paradigm for human and LLMs co-annotation of a large corpus. This helps to address the issue of laborious annotation tasks by human annotators and provides a cost-effective alternative for annotating entities from a large corpus. The result of this method shows up to a 21% performance improvement over random baselines. However, since LLMs have been trained on a large corpus available publicly, there may be data leakage where the model has seen some data, resulting in a lower entropy response. The experiment was only conducted in the English language corpus and was designed for entity annotation; thus, the output was not suitable for event extraction. Table 6 summarizes the most recent studies on LLMs for corpus annotations.
Table 6. Summary of recent studies on LLMs for corpus annotations. |
| Study | Results | Advantages | Limitations |
|---|---|---|---|
| Csanády et al. (2024) | BERT shows 91.2% to 96.5% test accuracies on the IMDb datasets using the model on random baselines. | ·The proposed method can handle large-scale text annotation tasks. ·Provides a cost-effective alternative to annotate large amounts of text. | ·Annotation using LLMs slightly compromises the annotation accuracy. ·LLMs alone cannot provide high-quality corpus annotations. ·The annotated corpus is not suitable for EE task. |
| Akkurt et al. (2024) | ·The proposed approach improved result by 2%. ·All models show improved performance with the GPT-4 + UD Turkish BOUN v2.11: 76.9% (best performance). | ·The model has been tested with data from UD English and Turkish Treebanks. ·The authors use public data and verify the methodology complies with ethical standards. | ·The annotation outcome varies (inconsistent) depending on the user’s prompt. ·The method is for entity annotation; thus output is not suitable for EE tasks. |
| Frei and Kramer (2023) | Result on various baseline models: ·gbert-large (P: 70.7%, R:97.9%, F1: 82.1%) ·GottBERT-base (P: 80.0%, R: 89.9%, F1: 84.7%) ·German-MedBERT (P: 72.7%, R: 81.8%, F1: 77.0%) | ·Solves limited corpus availability for non- English medical texts. ·The proposed method shows a reliable performance. | ·The proposed method is computationally expensive. ·The annotated corpus cannot be considered a gold-standard and requires more validation. ·The method is for entity annotation, thus output is not suitable for EE tasks. |
| Li et al. (2023) | The result shows up to 21% performance improvement over random baselines. | ·The annotation process is done together by humans and LLMs. ·Provides a cost-effective alternative to annotate large amounts of text. | ·The study does not assess if LLM-generated annotations outperform human-annotated corpus. ·The method is for entity annotation, thus output is not suitable for EE tasks. |
Based on Table 6 and the discussion above, it is clear that despite LLMs applications serving potential in automatic corpus annotation, the study in this area is still new and limited work has demonstrated applications of LLMs for corpus annotation (Li et al., 2023). Additionally, studies that leverage LLMs for annotation tasks mainly focus on entity annotation only and not on event annotation. LLMs have the potential to help annotate large amounts of text at a lower cost (Csanády et al., 2024); nevertheless, limited research has explored methods to optimize the allocation of humans and LLMs for corpus annotation to achieve both quality and cost objectives (Li et al., 2023). Additionally, the majority of these studies are still at the preliminary stage and researchers should be conscious of ethical concerns (Li et al., 2023; Tan et al., 2024; Törnberg, 2024) and legal issues, particularly when considering LLMs as a strategy to provide annotation to text corpus. For instance, in the context of the European Union, the use of AI requires high legal requirements on data management and ethics. In addition, corpus annotations using LLMs is currently less reliable when compared to a corpus manually prepared by human experts and cannot be considered gold standard annotations (Frei & Kramer, 2023).
5 Conclusion and future works
This paper presents a comprehensive review of existing corpora and the method for preparing an annotated corpus for a closed-domain event extraction task. To ensure correct annotation for closed-domain event extraction, this study includes a clear definition of events, general guidelines for event annotation, and criteria for determining which text should be annotated. Additionally, this study presented common annotation formats and suggested suitable tools to be used for the corpus annotation task. To the best of the authors’ knowledge, the information provided in this study has been kept as accurate as possible.
The limitations and challenges discussed in Section 4 emphasize the ongoing challenge that researchers must address in relation to corpus preparation for event extraction tasks. There is still much room for improvement in the field of event extraction from text, which begins with the acquisition of more annotated data. While this will require substantial effort, we genuinely believe that this study offers comprehensive guidelines for researchers to enhance the quality of data annotations, particularly for event extraction tasks across various domains.
Moving forward, researchers can broaden their focus to preparing annotated corpora in diverse domains beyond biomedical research, considering the current limitations of the available corpus annotations. Further advancements can be made in this area, particularly through the development of accessibility tools to facilitate the conversion of annotations between different formats. Additionally, more in-depth studies are needed to explore the use of LLMs to achieve more reliable corpus annotations. The authors believe that this study provides valuable knowledge to serve as a guiding framework for preparing and accurately annotating events from text corpora.
Acknowledgment
The authors would like to thank Universiti Teknologi PETRONAS for providing the facilities and funding required to complete this research.
Author Contributions
Mohd Hafizul Afifi Abdullah (hafizul94@gmail.com, hafizul@ieee.org, ORCID: 0000-0002-1427-2571): Conceptualization, Methodology, Data curation, Formal analysis, Writing - original draft, Validation, Writing - review & editing, Approval of final manuscript.
Norshakirah Aziz (norshakirah.aziz@utp.edu.my, ORCID: 0000-0001-5563-0286): Conceptualization, Methodology, Data curation, Writing - original draft, Validation, Writing - review & editing, Approval of final manuscript.
Said Jadid Abdulkadir (saidjadid.a@utp.edu.my, ORCID: 0000-0003-0038-3702): Formal analysis, Interpretation of results, Validation, Writing - review & editing, Approval of final manuscript.
Kashif Hussain (kashif.talpur@solent.ac.uk, ORCID: 0000-0003-0011-2726): Conceptualization, Methodology, Validation, Writing - review & editing, Approval of final manuscript.
Hitham Alhussian (seddig.alhussian@utp.edu.my, ORCID: 0000-0003-3947-269X): Formal analysis, Interpretation of results, Validation, Writing - review & editing, Approval of final manuscript.
Noureen Talpur (noureen.talpur@utp.edu.my, ORCID: 0000-0003-4162-7910): Data curation, Writing - original draft, Validation, Writing - review & editing, Approval of final manuscript.