


1 Introduction
With breakthroughs in materials science, nanotechnology has been widely used in various industries. Nanotechnology, defined as the study and application of structures ranging in size from 1 to 100 nanometers (nm), has received significant attention (Rawat et al., 2006). Notably, nanoparticles have distinctive optical, electronic, and structural properties that distinguish them from macromolecules (Sinha et al., 2006) and offer unique capabilities at cellular, atomic, and molecular levels (Rawat et al., 2006). Therefore, nanotechnology has the potential to revolutionize the landscape of medical and healthcare solutions, particularly in disease diagnosis, treatment, and prevention at the cellular level, giving rise to the term “nanomedicine” (Bayford et al., 2017).
Nanomedicine encompasses two fundamental domains: nanomedicine-based diagnostics and nanotechnology-based therapeutics. Implementing nanomedicine enables the early detection, precise diagnosis, effective treatment, and monitoring of infections (Archakov, 2010). Nanotechnology has significantly advanced restorative diagnostics by introducing highly efficient and precise instrumentation for both in vitro and in vivo diagnostics (W. Zhang et al., 2018). Pathologists have used nanoparticles to distinguish malignant growth cells in biopsies by exploiting the distinct light dissipation and absorption spectra of these cells (Zitka et al., 2012). Moreover, nanoparticles are useful in medical imaging because of their comparable size to biomolecules, such as enzymes and receptors, enabling their use as probes for tracking cell motility and molecular changes (Cuenca et al., 2006; Rawat et al., 2006). Consequently, nanoparticle-based molecular imaging probes and contrast agents have become increasingly prominent, surpassing other single-molecule-based contrast agents. Imaging agents encompass various contrast materials, including those with fluorescent and radioactive properties (Bennett et al., 2008). Furthermore, nanoparticles have emerged as effective Magnetic Resonance Imaging (MRI) contrast agents, such as superparamagnetic iron oxide nanoparticles (SPION), which exhibit superior performance compared with conventional superparamagnetic reagents (D. Kim et al., 2018).
Regarding the therapeutic realm of nanotechnology, significant global research has focused on ZnO nanoparticles, single-walled carbon nanotubes, and antibiotic-coated nanoparticles (Baptista, 2014). Notably, an important area in nanomedicine research involves the targeted design of anticancer drugs, exploiting the distinctive features of tumors, such as endothelial cell openings ranging from 200 nm to 1.2 µm, permitting nanoparticle penetration into the extravascular space (Hobbs et al., 1998). Various nanodevices, such as dendrimers, ceramic nanoparticles, and carbon nanotubes, can target cancer cells (Sugiyama, 2015). Functionalization of nanoparticles through monoclonal antibodies or cell surface receptor ligands exploits specific receptors on cancer cell surfaces for targeted drug delivery (Mitra et al., 2006). Ligand-coordinated nanoparticle binding to tumor cell receptors represents a promising approach for particle therapy (Misra et al., 2010). Drug-loaded nanoparticles act as carriers, forming nanocapsules or nanospheres, thereby improving drug delivery (C.-Y. Zhao et al., 2018). Oral administration of zinc oxide nanoparticles has demonstrated efficacy in treating diabetes by affecting serum insulin, glucose tolerance, and blood glucose levels (P. Yang et al., 2023).
Furthermore, nanotechnology has significantly affected stem cell biology research, offering new avenues for regenerative medicine (Sanchez et al., 2011). Recently, diverse nanostructured materials have been used to reconstruct human organs, including bone, muscle, and skin (van Rijt & Habibovic, 2017). Mesenchymal stem cells (MSCs) have demonstrated significant potential for proliferation and differentiation into cardiomyocytes within AUNP-mixed polycaprolactone (PCL) scaffolds, showing promise for myocardial infarction repair (Jain, 2008). In addition, magnetic nanoparticles can isolate and group stem cells, whereas nanocarriers binding to biomolecules can modulate stem cell proliferation and differentiation.
Nanomedicine has demonstrated unique potential and interdisciplinary characteristics in modern medical care, with its transformative impact spanning various fields, including diagnosis, treatment, and regenerative medicine (Shi et al., 2017). Therefore, employing bibliometric tools to monitor research trends and scientific results in this field is essential (Betker et al., 2013).Identifying emerging technologies in the field constitutes an imperative strategy to afford countries and businesses opportunities to surmount innovation challenges, achieve cutting-edge technological breakthroughs, and cultivate growing markets (Ahmed et al., 2017).The identification of emerging technologies in the field of nanomedicine not only summarizes the current technological status but also highlights emerging technological fields that may influence nanomedicine. This process thus facilitates the discovery of technologies that urgently require development, providing superior solutions for timely intervention and improved clinical outcomes (Dundar et al., 2020a).
Numerous experts and scholars in the field of bibliometrics have contributed to the discovery of emerging technologies. For example, the Foresight and Understanding of Science Expositions (FUSE) project, funded by the Intelligence Advanced Research Projects Activity (IARPA) in 2011, aimed to identify emerging topics from scientific, technological, and patent literature (McKeown et al., 2016; Porter et al., 2019). Conversely, some scholars have focused on emerging technology forecasting in the medical-device industry in their study (AlSumait et al., 2009). Boyack et al. (2014) used citation analysis to identify technology topics in two nanotechnology domains. Chen et al. (2018) detected and visualized emerging trends and transient patterns in scientific literature. Ke (2017) redefined the metrics of fundamentality and novelty to investigate the technological impacts of biomedical research. M. Kim et al. (2018) used a data mining approach to compare the emergence of industrial robots in various countries and assess discrepancies between nations. Jiang et al. (2024) propose an innovative lexical-level framework to identify and understand emerging technologies from the perspective of Technical knowledge Flow (TKF), construct and interpret multidimensional indicators reflecting the attributes of ETs by comprehensively analyzing knowledge absorption, growth, and diffusion, effectively evaluating emerging scores at the terminology level and accurately identifying ETs. Using deep learning and weak signal analysis, Ebadi et al. (2022) propose a multi-layer quantitative approach to help strategic planners and domain experts better identify and monitor emerging technology trends. Wang et al. (2024) measure the innovative development path of emerging technologies by improving triple reference networks, proposing a compression method of reference networks from the perspective of data sets, and using technical interference degree as the main path to extract reference network importance criteria. Li et al. (2019) propose a novel approach to identifying emerging topics in science and technology by combining two large-scale scientific literature models based on direct citation and co-citation, and using a difference function to reward those emerging and rapidly growing clusters to nominate emerging topics. These findings emphasize the role of scientific publications as surrogates for scientific research and technological development (Xu et al., 2018).
Nevertheless, most studies have focused on quantifying publications and citation networks (Huang et al., 2022) or analyzing abstracts or titles using text-mining techniques (Abbasi et al., 2022; Ding et al., 2022). Only a few scholars have conducted analyses by examining the full text of the literature (Cao et al., 2023; Richard et al., 2022). Full-text analysis captures details and complexities in an article that are often overlooked or only briefly mentioned in titles and abstracts. By analyzing the full text, researchers are able to gain an in-depth understanding of the article’s core arguments, research methodology, experimental results, and their interpretations, resulting in a richer and more precise understanding of the research topic (Tosatto et al., 2022). This study utilizes advanced deep-learning techniques to extract relevant information from full-text literature. Subsequently, we applied Noiseless Latent Dirichlet Allocation (NLDA) topic modeling to the refined information and established metrics to identify emerging technologies (Churchill & Singh, 2021).
In general, the innovations of this research are primarily encapsulated in the following dimensions:
Firstly, this study proposes a technology framework grounded in innovative content extraction, utilizing SciBERT for the classified extraction of key information and identifying emerging technologies through NLDA modeling of the extracted data. This holistic approach eliminates redundant data, enhancing both the explanatory power and accuracy of the subject model.
Secondly, utilizing full-text processing of scientific articles, this study diverges from traditional methodologies that prioritize abstracts or titles, thereby uncovering cutting-edge advances in nanomedicine. This in-depth textual analysis facilitates a comprehensive discovery of emerging technologies by capturing nuanced details and core essences of research potentially overlooked in summaries or headlines.
Additionally, this study develops multidimensional metrics for assessing technological emergence, incorporating measures of novelty, innovation, growth, impact, and thematic intensity. Used collectively, these indicators quantify the emergence of new technological domains, offering a comprehensive perspective on technological advances in nanomedicine.
Finally, The study further incorporates a cross-country analysis and a time series analysis to examine the global distribution and identify decade-long trends in innovative nanomedical research, respectively. These analyses yield valuable insights into the geographical and temporal dynamics of innovation within nanomedical research.
The remainder of this paper is structured as follows. Section 2 reviews related work. Section 3 introduces a framework based on information extraction (IE) and topic modeling. Section 4 presents the experimental results and discusses the nanomedicine literature dataset for 2013-2023. Section 5 summarizes the work and provides policy implications.
2 Related Work
2.1 Information extraction
Numerous studies have emphasized the significant impact of the Internet’s rapid expansion on the scientific and technical literature across all domains throughout the year (Nasar et al., 2018; C. Zhang et al., 2022). A report by the international association of scientific, technical, and medical Publishers revealed that the number of published researches has increased by an annual average of 4%-5%. Approximately 2.2 million fresh scientific articles were disseminated in 2016 (Canagarajah, 2022; Khanna et al., 2022). Consequently, the challenge of extracting essential insights from an extensive repository of literary data while disregarding background information has become an important concern. Boegel et al. (2022) characterized this endeavor as Information Extraction (IE). Moreover, numerous studies have highlighted the increasing application of IE techniques in various fields, such as medicine, genetics, and other biological sciences (Seeger et al., 2022).
Among the various methodologies, Arshamian et al. (2013) adopted a rule-based approach to extract core ideas from research papers. In contrast, Gupta and B. Hu et al. (2014) applied sentence matching, dependency trees, and seed rules to identify focal points, techniques, and domains. Machine learning methods have gained prominence in recent years. Schneider et al. (2018) used preposition disambiguation with Naiver-Bayesian classification for entity extraction. I. C. Kim et al. (2014) proposed a support vector machine-based framework that utilized a linear kernel function during training to extract sentence-level key insights. Several scholars have adopted a structured learning approach with residuals to process a corpus of 400 articles from ACM and ACL using various training algorithms, including Perceptron, AdaGrad, and SVM (Bianchi et al., 2016; Peng et al., 2014).
Experts in this field have adopted diverse methodologies for IE. However, existing studies have primarily focused on abstracts, with a limited exploration of full-text articles. Therefore, a significant contribution of this study is the utilization of an advanced deep-learning approach. Herein, the BERT model was used for comprehensive IE from all articles instead of the conventional practice of abstract-based extraction, marking an innovation (Song et al., 2023).
2.2 Topic model
Topic models represent a category of unsupervised machine learning techniques devised to elucidate the fundamental topics inherent in a collection of documents (Gruen & Hornik, 2011; Jelodar et al., 2019; Zhao et al., 2011). They demonstrate exceptional proficiency in condensing a vast corpus of documents into a concise summary represented as a topic or cluster of related terms.
The inception of topic modeling can be traced back to the early 1990s when Letsche & Berry (1997) introduced a Latent Semantic Indexing (LSI) model, demonstrating how latent semantic analysis can be used in the automated indexing and retrieval of documents from vast databases. Subsequently, in 1999, Thomas Hofmann made a significant contribution to the field of topic modeling by introducing Probabilistic Latent Semantic Indexing (pLSI). Latent Dirichlet Allocation (LDA), proposed by Blei et al. in 2001, has emerged as a seminal contribution. LDA draws inspiration from pLSI (Blei et al., 2003) and develops a unique generative model based on the Dirichlet distribution (Nigam et al., 2000). This model features more comprehensive assumptions regarding text generation than its counterparts, rendering LDA the most widely used probabilistic topic model.
LDA has undergone numerous adaptations and applications in various facets of natural language processing. Jelodar et al. (2019) thoroughly investigated LDA and its variations in their survey of LDA-based topic models. For example, Lafferty and Blei developed a Correlated Topic Model (CTM) to address the challenges of interrelated topics (Blei & Lafferty, 2007). Recently, topic modeling has been improved by integrating Word2Vec and other word-embedding models with innovative natural language processing techniques (Zhang et al., 2018). Hu et al. (2018) presented the Biterm Topic Model (BTM), designed for short texts like tweets and social media posts, demonstrating exceptional performance in short text modeling. Fu et al. (2018) introduced the Embedding Topic Model (ETM), where words and topics are represented as vectors within the embedding space. Thompson (2020) later suggested using the BERT language model to generate topics by applying k-means clustering to tokens derived from BER-extracted context vectors. Furthermore, Churchill & Singh (2021) proposed a Topic-Noise Model that integrated the modeling of topic and noise distributions, resulting in superior noise filtration. They combined a Topic-Noise Discriminator (TND) and LDA to formulate an integrated Topic-Noise Model, known as NLDA, which demonstrated improved consistency compared to LDA. This is supported by quantitative and qualitative assessments of topic interpretability, facilitated by illustrative topics and human assessments (Churchill & Singh, 2023, 2022b).
The NLDA model was used in this study to process the text data IE. This approach effectively filters out extraneous text information, producing more interpretable topics for human understanding. Subsequently, the supporting documents for each topic were identified based on the document-probability matrix generated by this model.
2.3 Identifying technology emergence
Academic approaches to identifying emerging technologies involve qualitative methods based on specialized knowledge and quantitative text analysis (Bishop, 2006). Technical approaches include inventive problem-solving theory, scenario management, bibliometric analysis, and data mining (Arora et al., 2013; Breitzman & Thomas, 2015; Holmes & Ferrill, 2005; Keenan, 2003; Li et al., 2019; Noh et al., 2016). Various studies have focused on developing metrics for emerging technologies from multiple perspectives. Rotolo et al. (2015) refined five attributes to characterize emerging technologies: radical novelty, rapid growth, coherence, prominent impact, and the presence of uncertainty and ambiguity. Scholars have identified emerging technology and emergent topics by analyzing citations and co-citations in scientific data, highlighting the novelty and growth of emerging technologies (Sidaway, 2020; Vatanasakdakul et al., 2023). Other scholars have utilized publication and author counts to identify burgeoning areas in science (Long et al., 1980; Uddin & Khan, 2016; D. Zhao & Strotmann, 2011). Chakraborty & Pradeep (2017) introduced a model for detecting emerging clusters founded on four identifying characteristics: the public sector ratio, scientific index, originality index, and reference index. Other attributes developed by scholars encompass data validity, data availability, implementation cost, ease of use, and methodological adaptability (Dash et al., 2007; Gokhberg et al., 2013; Guderian, 2019; Lee et al., 2018).
Furthermore, frameworks rooted in time series evolution analysis are employed in identifying emerging technologies, aiming to comprehend the dynamic nature of technological progress. For instance, Xu et al. (2021) developed a framework employing thematic models to predict the emergence of new technologies through the analysis of sequential text data. Shen et al. (2020) proposed a deep learning model, SeriesNet, which predicts future technology trends by learning from time series data at multiple ranges and levels, utilizing sophisticated analytical techniques. Mercer and Keogh (2022) developed another predictive model for monitoring outlier behavior in time series, facilitating the discovery of new technologies in industrial and natural sciences. Additionally, Ebadi et al. (2022) combined deep learning with weak signal analysis in a multi-layer quantitative approach to predicting technological trends, including advances in the field of hypersonic motion.
In summary, methods for identifying emerging technologies exhibit significant diversity. In this context, our research has developed discovery metrics for emerging technologies in nanomedicine. These metrics stem from information extracted from technology topic support documents through topic modeling, ultimately facilitating the identification of emerging technologies.
3 Methodology
This section elucidates four dimensions of research pertaining to the discovery of emerging technologies.
The first dimension involves data preprocessing, including acquisition, partitioning, cleansing, and textual annotation. Data were obtained from established repositories of scientific literature in biomedicine. These raw data are transmuted through meticulous curation into a structured corpus amenable to computational recognition. A subset of this data was annotated manually by specific rules in anticipation of the subsequent model training and processing.
The second dimension involves the extraction and condensation of important information. In the knowledge extraction process, a sophisticated machine learning model was developed by training the annotated data obtained from the preliminary phase. Subsequently, this model was used to predict crucial insights embedded within the entirety of the literature data. These distilled fragments of significant knowledge were then summarized in accordance with the classification that corresponds to each literary. This undertaking was executed to lay the foundation for ensuing model recognition.
The third dimension focuses on identifying technology topics. The key knowledge corpus produced in the previous phase serves as the substratum. Potential technology topics are identified from this corpus using a combination of expert interviews and topic modeling of the relevant literature. This process encompasses the thorough elimination of unnecessary terminology.
The final dimension involved developing and quantifying indicators relevant to emergent technological topics. Indicators are devised through an in-depth review of the relevant literature. Subsequently, these sub-indicators were computed for each thematic facet and combined into composite indicators. This cumulative metric enhances the ability to identify emergent technological topics, thereby facilitating the formulation of judicious policy directives and strategies for technological advancements.
3.1 Data collection
We obtained data from PubMed Central (PMC) and Web of Science (WOS) databases. PMC is an open-access archive containing full-text biomedical and life science journal articles from the National Library of Medicine (NLM) of the National Institutes of Health (NIH) (Roberts, 2001). Currently, it comprises an extensive collection of thousands of journal articles, totaling over 8 million full-text articles, spanning centuries of research in biomedical and life sciences from the late 1700s to the present (Hsiao & Torvik, 2023; Lin et al., 2023). This content comprised articles published in scholarly journals, peer-reviewed author manuscripts, and preprint versions of articles publicly available before peer review (Michaleff et al., 2011). Therefore, we used this database for our comprehensive literature dataset.
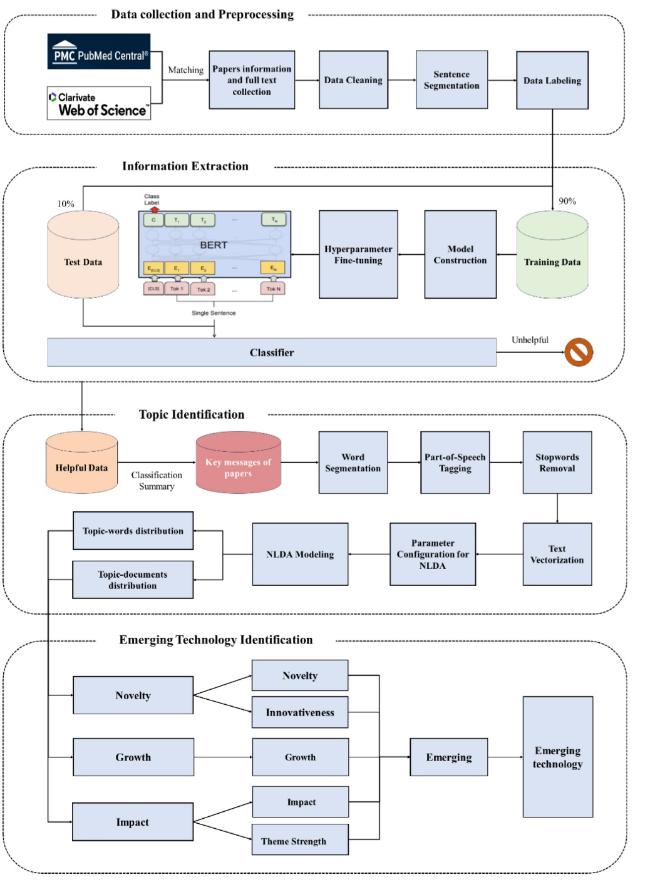
Figure 1. A framework of data acquisition and analysis. |
The WOS is a valuable resource for citation data in bibliometric analyses (Falagas et al., 2008). Furthermore, WOS offers bibliometric software to produce comprehensive statistical insights (Harzing & Alakangas, 2016). Therefore, this database is frequently used by researchers as a primary resource for extensive bibliometric analysis.
Drawing on the research methods of past scholars, we established the time span for the data collection process as 2013-2023, as this period witnessed a 7.39-fold increase in global annual publications, from 1,851 to 13,683, offering a rich resource for research (Tao et al., 2023). The data collection process consisted of two distinct phases. In the initial phase, a search was conducted in PMC using the keyword “nanomedicine”. Web crawlers were developed using Python Selenium and the Beautiful Soup library to retrieve and analyze HTML content. This process facilitated the extraction of relevant information from the literature, including titles, full texts, and DOI numbers. Notably, we extracted content from full-text articles after the abstract and before the references. The extracted content formed the basis of our text database. Subsequently, we used a similar approach in WOS using the Science Citation Index Expanded (SCI-Expanded) journal categories. The subsequent dataset comprises titles, authors, keywords, publication years, and DOI numbers. In addition, the dataset incorporates supplementary metrics, including the number of citations, citation density (number of citations per year), affiliations, countries of affiliation, journals of publication, and associated impact factors (IF) based on the Journal Citation Reports. This information is brought together in our indicator database.
3.2 Data preprocessing
The preprocessing work performed on the text database and indicator data obtained in the previous step was as follows: First, the two databases were matched based on the DOI numbers of the articles. After matching, 2,083 full-text articles and their corresponding indicators were obtained. The articles were subsequently subjected to sentence processing using the NLTK package. An automated toolkit for sentence splitting has been used over traditional punctuation sentences to more accurately split sentences based on context and obtain precise results (Schmitt et al., 2019; Yao, 2019). Statements containing only formulas and special symbols were removed, and the remaining sentences (totaling 673,642) were stored in a database and traced back to their source literature. We used the criteria described in Table 1 to distinguish between academically innovative and non-innovative sentences.
Table 1. Criteria for distinguishing sentences. |
| Sentences with academic innovation | Sentences that lack innovation |
|---|---|
| Introduce new ideas, unique approaches, or novel methods. | Furnish common background information or definitions. |
| Display original discoveries, experimental results, or undocumented data. | Elucidate routine procedures and methods that are commonly used in this field. |
| Propose unique applications, materials, or techniques. | Provide a summary of well-established information or results available in the literature. |
A sentence database consisting of 2,276 innovative utterances and 7,724 non-innovative utterances was obtained after labeling. This dataset was used to train the upcoming deep-learning models.
3.3 Information extraction (IE)
It has been empirically demonstrated that fine-tuned BERT models produce superior results across various natural language processing tasks, such as text categorization and automated question-answering (Devlin et al., 2019). The advantages of using BERT include accelerated development, reduced data prerequisites, and improved outcomes (Bello et al., 2023; Reimers & Gurevych, 2019). Therefore, we selected the fine-tuned BERT model to categorize sentences as innovative or non-innovative in the context of IE from an innovative perspective.
To optimize outcomes while saving valuable training time, it is imperative to make an informed decision regarding the pre-trained model. SciBERT was used as the pre-training model in our study, initially trained on a random sample of 1.14 million papers from Semantic Scholar (Lobanova et al., 2023). This corpus comprised 18% papers from computer science and 82% from various biomedical fields. Using the pre-trained parameters of this model as initial weights not only conserve time and resources but also improves performance by transferring its generalized linguistic representations, obtained from extensive text data, to subsequent classification tasks (Shenet al., 2023; Thierryet al., 2023). Consequently, it achieves state-of-the-art performance across a wide spectrum of scientific domain natural language processing (NLP) tasks. Further evaluation details can be found in the associated paper, with the evaluation code and data available in the associated repository.
Our approach to fine-tuning BERT based on the pre-trained model unfolds as follows: Initially, the model was implemented using the Keras package and integrated with the SciBERT pre-training model. Subsequently, we thoroughly preprocessed the input data, involving the disambiguation of text and its conversion into three essential embedding vector representations: word, position, and type embeddings. These embedding vectors are fundamental components that facilitate the BERT model in comprehending the text.
We fine-tuned several hyperparameters during the training phase to ensure training effectiveness. Table 2 indicates the final selection of the hyperparameter values. The learning rate of the optimizer was set to 2e-5, a standard value for fine-tuning the pre-trained models. In order to accommodate longer text sequences, we have broken the limitations of standard BERT. Specifically, the standard BERT model can accommodate a maximum sequence length of 512 tokens. When encountering text that is longer than 512 tokens but still less than 1,024 tokens, our current approach is to truncate the text and retain only the first 512 tokens. This approach is simple and efficient, but may inadvertently result in the exclusion of potentially critical information in the second half of the text. We have therefore adopted a different strategy for excessively long texts with more than 1,024 tokens. In this case, the text is divided into multiple segments, each containing no more than 512 tokens. Each segment is then processed independently. For text shorter than 512 bytes, we use padding techniques to extend the text length to the necessary 512 bytes. The truncation, chunking, and padding processes we employ ensure that the length of the input text is consistent and that the model fully learns the semantic information. The batch size was set as 32 to expedite the training process. Eight iterations were performed to ensure the complete convergence of the model. A fully connected layer was constructed in the final layer of the BERT model for sentence classification, which selected the output category with the highest probability. We used softmax as the activation function instead of the sigmoid function because of scalability concerns. The fully connected layer accepts the multidimensional vectors of the [CLS] tokens obtained after training as input. Unlike pre-training [CLS] tokens, which contain no information, post-training tokens encapsulate information about the entire current utterance (Jeonget al., 2020). To assess the performance and generalization capability of the model, we implemented a ten-fold cross-validation technique. Figure 2 illustrates that the fundamental BERT model consists of 12 transformer layers and 12 attention heads.
Table 2. BERT model hyperparameterization. |
| Hyperparameter | Values | Description |
|---|---|---|
| batch_size | 32 | Number of samples per batch during training |
| max_seq_length | 500 | Maximum length of input sequences |
| learning_rate | 2e-5 | Learning rate, subject to tuning |
| train_epochs | 20 | Number of training epochs |
| warmup_proportion | 0.1 | Proportion of total training steps for learning rate warm-up |
| adam_epsilon | 1e-8 | Epsilon value for the Adam optimizer |
| dropout_prob | 0.1 | Dropout probability in dropout layers |
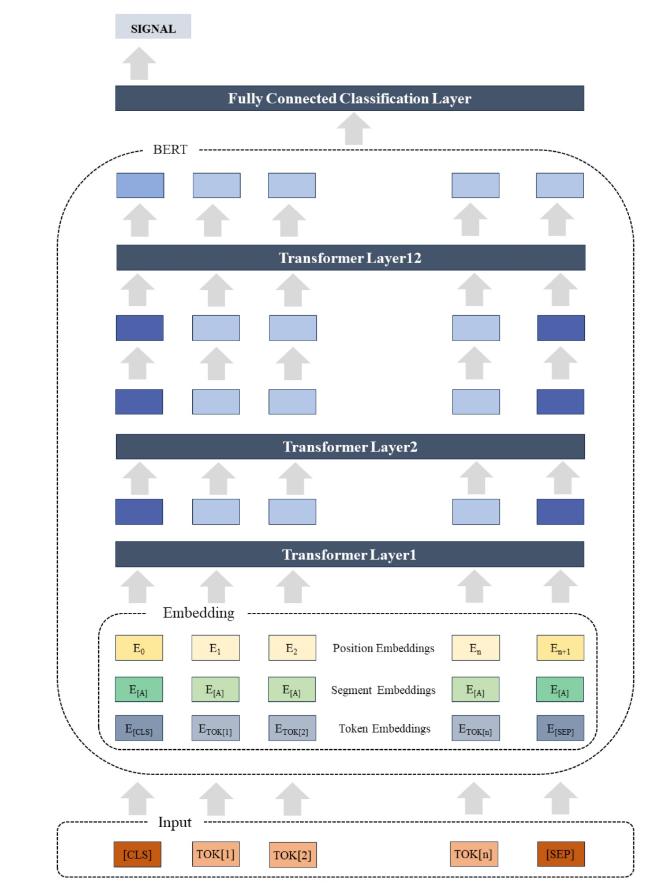
Figure 2. A framework of the BERT model. |
The model with the highest F1 score was selected for predictive purposes during the prediction phase. Following IE, we summarized all statements predicted as innovative sentences through article classification, resulting in refined literature content.
3.4 Topic identification
The Noiseless Latent Dirichlet Allocation (NLDA) represents a substantial advancement in topic modeling, particularly in addressing the challenges posed by brevity and noise prevalent in short text data (Churchill & Singh, 2021). NLDA markedly enhances subject modeling by the integration of the traditional latent Dirichlet allocation (LDA) framework with an innovative noise filtering technology, namely the Topic Noise Discriminator (TND) model. Its principal advantage lies in its capacity to simultaneously identify and separate meaningful subject content and noise from the data, thereby generating a more coherent and differentiated subject distribution. The key to the NLDA lies in its capacity not only to identify the subject content but also to construct a detailed noise distribution. Through the careful design of noise distribution construction, random and context-specific noise are systematically filtered out, significantly enhancing the purity and interpretability of the topics (Churchill & Singh, 2023). In particular, NLDA works with any generative topic model through a pre-trained TND noise distribution to enable two-tier analysis, a technique that refines the topic output while retaining the high-quality topic structure inherent in LDA, thereby generating topics that are both diverse and deeply reflective of the underlying data (Churchill & Singh, 2022b).
Detailed architectural depictions of the LDA and TND models are presented in Figure 3. In our notation, D denotes a dataset comprising M documents or posts represented by $D=\left\{d_{0}, d_{1}, \ldots, d_{M-1}\right\} $. Each document d is a compilation of N words, expressed as $d=\left\{w_{0}, w_{1}, \ldots, w_{N-1}\right\}$. A topic, denoted by t, encompasses a set of λ words, expressed as $t=\left\{w_{0}, w_{1}, \ldots, w_{\lambda-1}\right\}$, with these words characterized by their coherence and interpretability. The collection of topics is encapsulated in a topic set, $T=\left\{t_{0}, t_{1}, \ldots, t_{k-1}\right\}$, whereas a complementary noise set, $H=\left\{w_{0}, w_{1}, \ldots, w_{p-1}\right\}$, is used to detect the presence of the noisy elements.
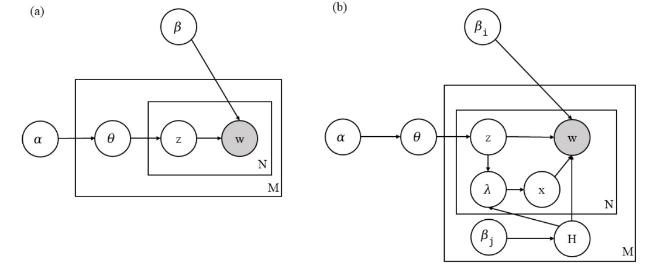
Figure 3. LDA (a) and TND (b) graphical models. |
In contrast to the comprehensive generative process for LDA elucidated by previous scholars (Blei et al., 2003), we present a concise overview of high-level generative processes using our notation.
For each document d in D:
(1) Stochastically determine the word count N for d.
(2) Sample the topic distribution θ from the Dirichlet distribution, conditioned on the parameter αx.
(3) For each word wi where 0 ≤ i < N:
(a) Draw a topic zi from the distribution θ.
(b) Select a word wi based on the conditional probability of wi, a given topic zi, conditioned on a parameter β.
Importantly, TND not only generates topics but also provides a valuable noise distribution that can be readily adapted to work with other topic models (Churchill & Singh, 2023). Using a pre-trained topic model that approximates topics through topic word distributions, we can use the pre-trained noise distribution from TND in the integration process to accomplish probabilistic removal of noisy words similar to the process in TND. The generative process for the TND can be summarized as follows:
For each document d in D:
(1) Stochastically determine the word count N for d.
(2) Sample the topic distribution θ from the Dirichlet distribution and condition it on the parameter α.
(3) For each word wi, where 0 ≤ i < N:
(a) Draw a topic zi from the topic distribution θ.
(b) Select a word either from zi or from the noise distribution H, as dictated by the beta distribution and conditioned on the parameter α.
(c) If drawing from zi, choose wi based on the conditional probability of wi the given topic and condition on the parameter β0.
(d) If drawing from H, select wi based on the conditional probability of wi given H, and conditioned on parameter β1.
Within NLDA, we combine the noise distribution produced by TND with LDA to develop an LDA variant that exhibits a reduced incidence of noisy words in its topics.
To implement NLDA, the noise distribution H on the dataset D was trained using TND, whereas the LDA model was simultaneously trained on a distinct dataset D2, which was not necessarily congruent D. Subsequently, we fused the noise distribution from the TND with the topic word distribution from the LDA to produce a topic set. Similar to the process of distinguishing between a topic word or a noise word, for each topic t within T, we exclude words wi based on the beta distribution of the frequencies of both the noise and the LDA topic distributions to make noise distributions more transferable to various parameters of LDA. We incorporated a topic weight parameter σ into the beta distribution calculation to downsample or oversample noise distribution. Equation 1 demonstrates how σ is used to scale the noise distribution based on k, the number of topics in the LDA model.
$\operatorname{Beta}\left(\sqrt{\theta_{t}^{i}+\beta_{1}}, \sqrt{H_{i}(\sigma / k)}\right)$
Taken together, the NLDA offers a practical and efficient solution to the long-standing challenge of noise in text-subject modeling. NLDA achieves effective separation of noise and subject matter through a refined model design, which enables researchers to more clearly capture and analyze hidden topics in text data, thereby motivating our choice of this model for subject recognition work.
Following the initial IE step, we thoroughly processed the textual data extracted from the paper during this phase of the experimental workflow. This data served as our primary source for conducting comprehensive topic modeling using the NLDA algorithm. Our data preparation protocol involves two critical steps: word segmentation and comprehensive data cleansing. Word segmentation involves dividing the text into individual words or tokens, facilitating subsequent analysis. Data cleansing procedures were used to remove inconsistencies, irregularities, or extraneous elements from the text to ensure the highest data quality.
The NLDA algorithm was implemented using the “gdtm” package, a sophisticated utility for topic modeling tasks. To ensure the reliability and robustness of our findings, the algorithm was executed 20 times. In each run, we varied the number of topics from 2 to 50, covering a wide spectrum of topic configurations. This comprehensive exploration enabled us to evaluate the model’s performance across various topic scenarios systematically.
After identifying the optimal number of topics, we applied the NLDA model to preprocessed textual data under this configuration. This step produced two important outputs: the topic-word matrix, providing insights into the word distribution within each topic, and the document-topic matrix, unveiling the associations between individual documents and topics. These matrices served as the fundamental component of our topic modeling framework, facilitating the extraction of meaningful and interpretable insights from the textual data extracted from the paper.
3.5 Emerging technology identification
The NLDA model can reveal significant latent topics by removing noisy words. This prompts the question of how emerging topics can be extracted from these latent ones. Previous studies have revealed that emerging topics generally exhibit three key characteristics: novelty, growth, and impact (S. Xu et al., 2021). This study uses originality and innovation to represent novelty, employs growth rate to reflect growth, and assesses topic strength and significance to evaluate impact. Given that the NLDA model can provide a document-topic probability matrix, we first evaluated ηj, which represents the average weight of each topic j. A document is classified as a supporting document for a given topic when the weight 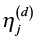 of the topic j in the document d exceeds ηj.
of the topic j in the document d exceeds ηj.
of the topic j in the document d exceeds ηj.a. Innovation
Recent research has demonstrated a high level of Innovation. Thus, the average appearance time of papers related to this topic indicates Innovation (Small et al., 2014). This calculation is outlined in Equation 2, where Nj signifies the degree of Innovation of the topic j, Ti represents the publication time of paper i, and N indicates the total number of papers supporting the topic.
$N_{j}=\sum_{i=1}^{N} \frac{T_{i}}{N}$
b. Originality
Highly novel research findings should contain more valuable elements (Keenan, 2003). Therefore, Originality can serve as an indicator of a topic’s novelty. This is computed using Equation 3, where Ij denotes the novelty of the topic j, Ai represents the number of innovative sentences in the paper i, and N is the total number of papers supporting the topic.
$I_{j=} \sum_{i=1}^{N} \frac{A_{i}}{N}$
c. Growth
We consider the annual growth rate of papers outputs related to the topic to measure growth. Referring to a previous study (Noh et al., 2016), to mitigate the impact of factors, such as changes in publication volume over time, we adopted the average annual growth rate of theses over the past three years, as illustrated in Equations 4 and 5. Here, YGRi represents the growth rate of articles in year i, Pi indicates the publication volume of theses in year i, and G signifies the growth rate of the topic.
$Y G R_{\mathrm{i}}=\frac{P_{i+1}-P_{i}}{P_{i}}$
$G=\frac{\sum_{t=0}^{2} Y G R_{i-t}}{3}$
d. Significance
The significance of scientific topics is primarily reflected in the citations of related papers (Iorfino et al., 2017). However, citations tended to accumulate over time. Therefore, to analyze the influence of scientific research topics on current academic research, we integrated the time weight ti into the measurement of academic influence, as specified in Equation 6. Here, ti denotes the time weight of the citation frequency of topic-related papers in the year i, and n is the number of years the dataset covers. It has been shown that more recent research generally has more influence on the field, so the numerator 2i in Equation 6 ensures that the most recent year has a higher weight, and as i increases, t increases. The denominator n(n+1) is a normalization factor that ensures that the weights of all years sum to 1. This constant does not directly affect the individual weights, but ensures a proportional distribution of weights. The method for measuring the influence of scientific topics is presented in Equation 7, where Bs represents the academic influence of the topic and Ci represents the citation frequency of papers related to the topic in the first year.
$t_{i}=\frac{2 i}{n(n+1)}$
$B_{s}=\sum_{i=1}^{n} t_{i} * C_{i}$
e. Topic Strength
Recent studies have emphasized the importance of topic intensity as a quantitative index for determining whether a scientific research topic is a research hotspot (Blei et al., 2003). It is frequently calculated by dividing the sum of the weight of the research topic in all scientific literature by the total weight of the research topic. In Equation 8, ηj denotes the topic intensity value of the topic j, N represents the total volume of the supporting literature, and $\eta_{j}^{(d)}$ denotes the weight of the topic j in the document d. Topic intensity reflects the importance of a topic in the text set, with a higher proportion of each document indicating greater significance. This method can be used to represent the impacts of a particular topic.
$\eta_{j}=\frac{\sum_{d=1}^{N} \eta_{j}^{(d)}}{N}$
To address the significant variation in the indicator levels, we used forward deviation standardization to standardize the indicator values, as described in Equation 9, where Yi indicates the standardized indicator value, Xi is the original indicator value, and Xmax and Xmin are the maximum and minimum indicator values, respectively.
$Y_{i}=\frac{X_{i}-X_{\min }}{X_{\max }-X_{\min }}$
Multidimensional measurement indices were used to calculate a composite index to identify the emerging technology. Previous research has demonstrated the extensive use of the Criteria Importance Through Intercriteria Correlation (CRITIC) method in the library and intelligence fields (Diakoulaki et al., 1995; Peng et al., 2020). The CRITIC method provides objective weighting by evaluating the relative strength and conflict of indicators, thereby producing scientifically sound and reproducible analyses. A greater divergence among the indicator values and a lower similarity with other indicators demonstrated higher informativeness and importance, as per Equation 10, where CRj signifies the information content of the indicator j, δj denotes the standard deviation of the indicator j, n represents the number of indicators, and rij represents the correlation coefficient between indicators i and j. We normalized the information quantity of the indicator CRj, as per Equation 11, to obtain the objective weight Wj of the indicator j. Finally, the comprehensive index of emerging topics was calculated using indicator weights and normalized values. The topic that exhibits a higher comprehensive index is an emerging research topic.
$C R_{j}=\delta_{j} \sum_{i=1}^{n}\left(1-r_{i j}\right)$
$W_{j}=\frac{C R_{j}}{\sum_{j=1}^{n} C R_{j}}$
4 Results
4.1 BERT-based classification performance
During this phase of our study, we systematically annotated a dataset of 10,000 sentences, distinguishing between innovative and non-innovative sentences. This dataset served as the training corpus for our model. Throughout the training, we consistently optimized various hyperparameters to improve the metrics. Table 2 lists the finalized BERT hyperparameters.
Subsequently, a 10 cross-validation process was conducted, during which various metrics, including average accuracy and return rate, were calculated. In addition, we also implemented a variety of traditional machine learning text classification methods and calculated relevant indicators. The quantitative results of these evaluations are shown in Table 3.
Table 3. Model evaluation indicators. |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| BERT+ Classifier | 0.836 | 0.864 | 0.853 | 0.858 |
| TF-IDF+SVM | 0.524 | 0.537 | 0.530 | 0.533 |
| TF-IDF+KNN | 0.600 | 0.617 | 0.593 | 0.604 |
| TF-IDF+NB | 0.582 | 0.553 | 0.569 | 0.560 |
| Word2Vec+ SVM | 0.650 | 0.658 | 0.614 | 0.635 |
| Word2Vec+ KNN | 0.696 | 0.628 | 0.603 | 0.615 |
| Word2Vec+ NB | 0.623 | 0.609 | 0.634 | 0.621 |
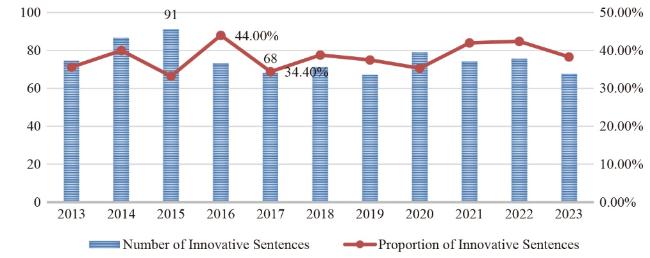
These findings unequivocally validate the efficiency of our model in the critical task of identifying innovative sentences, compared with other traditional machine learning classification models, each index of our model is about 20% higher. We use our optimized model to predict innovative sentences within a comprehensive collection of research papers, extracting 101,619 innovative sentences. Following this milestone, we organized these innovative sentences by publication and skillfully integrated publication metadata. We analyzed the distribution of innovative sentences, focusing on two key aspects: the average number of innovative sentences per article and the percentage of innovative sentences per article. Figure 4 illustrates the analytical insights.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 4. Innovation sentence distribution trends. |
Our careful analysis revealed that the number of innovative sentences appearing in the articles and the percentage of innovative sentences were relatively stable. Generally, there were 70-90 innovative sentences in the articles. The time series analysis revealed that the number of innovative sentences peaked at 91 in 2015 and dropped to 68 in 2017. The proportion of innovative sentences to the total number of innovative sentences fluctuated from 30% to 45%, reaching a peak of 44.00% in 2016 and declining to 34.40% in 2017.
Furthermore, we conducted an in-depth cross-country analysis by compiling statistics on the number and proportion of innovative sentences per article. To ensure the robustness of our findings, we excluded countries with insufficient article representation to minimize the impact of potential outliers. Table 4 summarizes the top 20 countries ranked by the number of innovative sentences per article. The United States has emerged as the leader in this regard, with 91 innovative sentences per article. Meanwhile, Mexico has the distinction of having the most innovative sentences per article at 47%.
Table 4. Regional distribution of innovation indicators. |
| Region | Average count | Percentage (%) |
|---|---|---|
| USA | 91.0 | 0.35 |
| Australia | 89.5 | 0.40 |
| Poland | 87.5 | 0.33 |
| France | 86.5 | 0.44 |
| Greece | 85.5 | 0.42 |
| Iraq | 83.5 | 0.42 |
| Denmark | 83.0 | 0.38 |
| Jordan | 82.0 | 0.35 |
| Kenya | 81.0 | 0.34 |
| Hungary | 81.0 | 0.38 |
| Malaysia | 79.0 | 0.38 |
| India | 75.5 | 0.39 |
| Mexico | 75.5 | 0.47 |
| Thailand | 75.5 | 0.25 |
| China | 74.5 | 0.40 |
| Germany | 74.0 | 0.41 |
| Nepal | 73.5 | 0.44 |
| Brazil | 73.0 | 0.40 |
| Italy | 71.0 | 0.37 |
| Netherlands | 71.0 | 0.45 |
4.2 NLDA topic extraction results
The “gdtm” package was used in the present study to build an NLDA model. A series of experiments was performed to determine the optimal hyperparameters for the model. Table 5 presents the results.
Table 5. NLDA model hyperparameterization. |
| Hyperparameter | Values | Description |
|---|---|---|
| num_topicsint | 20 | Number of topics |
| Alphaint | 50 | Alpha parameter of TND |
| Betafloat | 0.01 | Beta parameter of TND |
| Iterationsint | 200 | Number of training iterations |
| random_seed | 54 | Random seed to ensure consistent results |
To assess the significance and relevance of each topic, we initially identified the first ten topic words associated with each topic. Subsequently, words ranked from positions 11 to 40 were generated. In a concerted effort to ensure the accuracy and validity of our findings, we engaged specialists in the field of nanobiomedicine for their expert assessment. Through this collaborative process, we determined that the optimal number of topics in our study was 20. Tables 6a and b indicate the detailed outcomes, including the topic words and their corresponding weights.
Table 6 (a). NLDA Topic-Word Distribution. |
| Topic 1: Nanostructures and Polymer Chemistry | Topic 2: Graphene and Nanocomposites in Drug Delivery | Topic 3: Nanomaterial Quality and Surface Properties | Topic 4: Nanoparticles in Cancer Research and Therapy | ||||
|---|---|---|---|---|---|---|---|
| Polymers | Structures | Bacteria | Diffraction | Nanoparticles | Solution | Nanoparticles | Treatment |
| Nanoparticles | Nanostructures | Graphene | Surface | Nanomedicines | Surface | Transfection | Delivery |
| Copolymer | Solution | Nanoparticles | Solution | Information | Factors | Migration | Concentration |
| Treatment | Polymerization | Spectroscopy | Treatment | Product | Quality | Solution | Exosomes |
| Surface | Polymerization | Nanocomposites | Coating | Treatment | Molecules | Pathway | Surface |
| Topic 5: Ultrafast Centrifugation and Nanomaterial Preparation | Topic 6: Antitumor Therapy and Tumor Stem Cells | Topic 7: Nanoparticles and Drug Delivery | Topic 8: Photothermal Therapy and Nanomaterials in Cancer | ||||
| Microscope | Centrifugation | Survival | Metastasis | Nanoparticles | Solubility | Cancer | Treatment |
| Supernatant | Reagent | Resistance | Cancer | Curcumin | Solution | Nanoparticles | Conversion |
| Nanoparticles | Solution | Chemotherapy | Treatments | Encapsulation | Content | Nanosheets | Photothermal |
| Minutes | Transmission | Antitumor | Cancers | Hydrogel | Surface | Solution | Hypoxia |
| Microplate | Concentration | Nanoparticles | Doxorubicin | Storage | Treatment | Species | Performance |
| Topic 9: Antidiabetic Nanodrug Carriers and Biomedical Applications | Topic 10: Animal Studies and Biomedical Protocols | Topic 11: Nanoparticle Surface Characterization and Complex Structures | Topic 12: Inflammation and Biomaterial Interactions in Disease Research | ||||
| Extract | Insulin | Animals | Staining | Adsorption | Solution | Inflammation | Solution |
| Nanoparticles | Surface | Biodistribution | Committee | Nanoparticles | Treatment | Nanoparticles | Treatment |
| Dendrimers | Delivery | Nanoparticles | Liver | Surface | Complexes | Macrophage | Responses |
| Activities | Treatment | Sections | Solution | Nanotubes | Structures | Collagen | Surface |
| Solution | Concentration | Group | Surface | Results | Material | Cytokines | Inflammatory |
Table 6 (b). NLDA Topic -Word Distribution. |
| Topic 13: Nanotechnology in Vaccine Research and Infectious Diseases | Topic 14: Liposomes and Receptors in Drug Delivery | Topic 15: Nanoparticles in Materials Science | Topic 16: Nanocarriers for Hormone Release and Antitumor Drugs | ||||
|---|---|---|---|---|---|---|---|
| Nanoparticles | Treatment | Peptides | Affinity | Nanoparticles | Silicon | Nanocarriers | Loading |
| Authors | Concentration | Antibodies | Solution | Channel | Treatment | Nanoparticles | Micelle |
| Science | Diseases | Vesicles | Receptor | Solution | Diffusion | Carrier | Circulation |
| Solution | Results | Nanoparticles | Membranes | Surface | Results | Dialysis | Prodrug |
| Nanotechnology | Disease | Conjugation | Treatment | Parameters | Frequency | Antitumor | Solution |
| Topic 17: Luminescence and Spectroscopy in Nanomaterials | Topic 18: Endocytosis and Cell Signaling with Nanoparticles | Topic 19: Methods for Nanoparticle Preparation and Purification | Topic 20: Nanoparticle Permeation Properties in Oncology Treatments | ||||
| Emission | Wavelength | Internalization | Pathway | Dispersion | Product | Transport | Circulation |
| Nanoparticles | Spectrum | Endocytosis | Nucleus | Nanoparticles | Solution | Nanoparticles | Solution |
| Excitation | Signals | Nanoparticles | Surface | Centrifugation | Calibration | Penetration | Spheroids |
| Resonance | Solution | Mechanisms | Treatment | Ethanol | Treatment | Vessels | Surface |
| Resolution | Fluorescent | Solution | Pathways | Compound | Surface | Permeability | Treatment |
These topics are important for encapsulating the key topics that underpin the domain of nanobiomedicine. We distilled the main topics embodied in each topic through expert discussions and consensus.
The meaning of each topic was summarized based on expert discussions, with topic 1 focusing on research related to nanostructures and polymer chemistry, with particular emphasis on nanostructures, polymer chemistry, and delivery control. The research in Topic 2 focuses on bacteria, graphene, and nanocomposites and their applications in drug delivery and biomaterials. Topic 3 highlights the quality and product information of nanomaterials, including the quality assessment, surface properties, and methods for various nanomaterial applications. Topic 4 examined the use of nanoparticles in transfection, cell migration, and signaling pathways, with particular emphasis on cancer research and therapy. Topic 5 discusses ultrafast centrifugation, colloidal dispersion, the preparation of nanomaterials, and experimental methods related to microbiology.
Topic 6 concentrates on antitumor therapy, drug tolerance, and tumor stem cells, emphasizing different therapeutic approaches to tumors. Topic 7 focuses on nanoparticles, hormone release, and nanogels, emphasizing drug delivery and characterization of nanopreparations. Topic 8 covers photothermal therapy, photosensitizers, and the use of nanomaterials in cancer therapy, with a special emphasis on research related to biocompatibility and properties. Topic 9 focuses on antidiabetic nanodrug carriers, insulin delivery, and applications of bioactive molecules, with an emphasis on biomedical research. Topic 10 deals with animal studies, biodistribution, immunohistostaining, and laboratory manipulation, emphasizing protocols in biomedical experiments. Topic 11 focuses on adsorption, surface characterization, and the complex structures of nanoparticles, with particular applications in chemical and physical research.
Topic 12 is concerned with inflammation, cellular responses, and biomaterial interactions and has specific applications in disease research and therapy. Topic 13 covers nanotechnology, vaccine research, and infectious diseases with specific applications in vaccine development and infections. Topic 14 examines antibodies, liposomes, receptors, and cell permeation mechanisms, with particular applications in drug delivery and molecular recognition. Topic 15 discusses transport, deposition, and nanoparticles for materials science applications, focusing on material preparation and physical characterization. Topic 16 describes nanocarriers, hormone release, antitumor drugs for drug delivery, and nanomaterial applications. Topic 17 delves into luminescence, excitation, and spectroscopy, particularly highlighting optical techniques in nanomaterial research and fluorescence applications. Topic 18 deals with endocytosis, cell signaling pathways, and nanoparticles in biology, particularly their role in intracellular processes. Topic 19 discusses methods for dispersing, precipitating, dissolving, and purifying nanoparticles and their applications in chemical synthesis and biomaterials. Topic 20 deals with the permeation properties of nanoparticles in blood circulation, tissue retention, and oncology treatments, emphasizing therapeutics and therapeutic strategies. Collectively, these topics constitute a comprehensive summary of nanomaterial research, covering all aspects of research and application areas.
In addition, Table 7 demonstrates the results of LDA topic modeling using only three metadata elements of papers in the field of nanomedicine: the article title, abstract, and keywords. The dataset comprises 5000 articles, and the number of predefined topics is set to 12 based on perplexity analysis (Baimakhanbetov, 2023; Wang et al., 2019). The topic-keyword distribution in Table 7 appears disorganized, and the specialized vocabulary is scattered, making it difficult to summarize the appropriate semantic information of the topics.
Table 7. LDA Topic -Word Distribution. |
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 |
|---|---|---|---|---|---|
| protein | delivery | nanoparticles | nps | antibacterial | applications |
| corona | cell | silver | nanoparticles | cells | properties |
| cell | nanoparticles | agnps | delivery | bacteria | review |
| proteins | review | activity | brain | activity | materials |
| bone | drugs | nm | size | vivo | titanium |
| Topic 7 | Topic 8 | Topic 9 | Topic 10 | Topic 11 | Topic 12 |
| exosomes | based | tumor | wound | clinical | nanosheets |
| cells | high | cancer | materials | cancer | surface |
| tumour | cell | therapy | tissue | therapy | go |
| nanoparticles | clinical | cells | healing | photothermal | mxenes |
| drug | detection | pdt | bone | agents | applications |
4.3 Identification of emerging technology topics
The NLDA model was used in this study as the primary tool for obtaining a document probability matrix. This matrix served as the basis for determining supporting documents for each thematic area under consideration. Subsequently, the NLDA model facilitated the quantification of five distinctive sub-indicators within the context of each thematic area: novelty, innovation, growth, impact, and topic strength. These sub-indicators were subjected to a standardization procedure, resulting in normalized values, which were then used to calculate a comprehensive indicator representing the emergence of each topic.
This composite indicator, termed the “degree of emergence,” was systematically determined using the CRITIC method, encapsulating the multifaceted facets of topic relevance, innovation, and significance. The findings of this analytical process, wherein the degree of emergence of each topic was determined, are presented in Table 7. The tabular representation provides a comprehensive overview of the sub-indicator values and the corresponding total indicators, thereby offering holistic insight into the emergent attributes of each thematic element.
Table 8 . Results of the calculation of thematic indicators. |
| Innovation | Originality | Growth | Significance | Topic strength | Emerging degree | |
|---|---|---|---|---|---|---|
| Topic 12 | 0.793 | 0.446 | 0.390 | 0.913 | 1.000 | 0.722 |
| Topic 8 | 1.000 | 0.489 | 0.698 | 0.507 | 0.567 | 0.614 |
| Topic 6 | 0.632 | 0.591 | 0.616 | 0.709 | 0.375 | 0.595 |
| Topic 4 | 0.580 | 0.296 | 1.000 | 0.592 | 0.499 | 0.569 |
| Topic 2 | 0.145 | 0.566 | 0.191 | 0.730 | 0.777 | 0.533 |
| Topic 16 | 0.557 | 0.769 | 0.581 | 0.359 | 0.426 | 0.529 |
| Topic 9 | 0.351 | 0.342 | 0.144 | 0.882 | 0.376 | 0.474 |
| Topic 7 | 0.530 | 0.315 | 0.391 | 0.709 | 0.284 | 0.465 |
| Topic 3 | 0.272 | 0.000 | 0.342 | 1.000 | 0.256 | 0.427 |
| Topic 5 | 0.403 | 1.000 | 0.426 | 0.103 | 0.180 | 0.417 |
| Topic 13 | 0.310 | 0.217 | 0.379 | 0.768 | 0.046 | 0.383 |
| Topic 15 | 0.000 | 0.124 | 0.000 | 0.777 | 0.609 | 0.363 |
| Topic 11 | 0.090 | 0.213 | 0.360 | 0.753 | 0.044 | 0.343 |
| Topic 14 | 0.292 | 0.238 | 0.222 | 0.684 | 0.071 | 0.341 |
| Topic 1 | 0.264 | 0.263 | 0.262 | 0.506 | 0.268 | 0.334 |
| Topic 18 | 0.208 | 0.479 | 0.238 | 0.540 | 0.000 | 0.333 |
| Topic 10 | 0.329 | 0.758 | 0.404 | 0.000 | 0.246 | 0.330 |
| Topic 20 | 0.358 | 0.089 | 0.206 | 0.705 | 0.117 | 0.328 |
| Topic 17 | 0.216 | 0.332 | 0.447 | 0.392 | 0.156 | 0.318 |
| Topic 19 | 0.273 | 0.544 | 0.255 | 0.127 | 0.007 | 0.242 |
This high-level academic analysis focuses on the emergence and impact of various topics in emerging technology research. Twenty different topics were evaluated based on five sub-metrics (novelty, innovative, growth, impact, and topic strength), which are important for understanding the development and significance of each topic.
In Table 7 , we observe distinct trends in various research topics within the field of nanomedicine, as indicated by their performance in different assessment categories. Notably, Topic 8, “ Photothermal Therapy and Nanomaterials in Cancer,” and Topic 12, “ Inflammation and Biomaterial Interactions in Disease Research,” demonstrated the highest levels of “Novelty.” This signifies that they have received significant research attention in recent years due to their innovative contributions.
Furthermore, Topic 5, “ Ultrafast Centrifugation and Nanomaterial Preparation,” received the highest innovation score, highlighting its significant contribution to the field. On the growth trajectory, Topic 4, “ Nanoparticles in Cancer Research and Therapy,” and Topic 8, “A Photothermal Therapy and Nanomaterials in Cancer,” exhibited the highest growth rates. This reflects their rapid expansion and development within the biomedical research landscape.
Our impact metrics revealed intriguing insights. Topic 3, “ Nanomaterial Quality and Surface Properties,” and Topic 12, “ Inflammation and Biomaterial Interactions in Disease Research,” emerged as the highest-impact topics. In addition, Topic 12 obtained the highest topic intensity value, indicating its significant influence on the scientific community. In contrast, Topic 10, “ Animal Studies and Biomedical Protocols,” and Topic 18, “ Endocytosis and Cell Signaling with Nanoparticles,” demonstrated the lowest impact and topic strength, indicating relatively lower research attention in these areas. Disruptive innovations may be necessary for these topics to gain prominence in the field.
The comprehensive index provides an overview of the research landscape. Topic 12, “ Inflammation and Biomaterial Interactions in Disease Research,” and Topic 8, “ Photothermal Therapy and Nanomaterials in Cancer,” claimed the top two positions. This indicates that these research areas are at the forefront of emerging topics. Notably, this surge may be attributed to the profound impact of the COVID-19 pandemic on preventive medicine and infectious disease research, which has resulted in significant advances in vaccine development and infection studies. Concurrently, nanomedicine has made significant advances in the field of cancer treatment in recent years, which is why Topic 8 stands out.
In this study, we identified emerging research topics by selecting those with an emerging degree above the average threshold. Table 9 provides a summary of our final results on emerging theme identification.
Table 9. Emerging technologies in nanomedicine. |
| Topic id | Topic meaning |
|---|---|
| 12 | Inflammation and Biomaterial Interactions in Disease Research |
| 8 | Photothermal Therapy and Nanomaterials in Cancer |
| 6 | Antitumor Therapy and Tumor Stem Cells |
| 4 | Nanoparticles in Cancer Research and Therapy |
| 2 | Graphene and Nanocomposites in Drug Delivery |
| 16 | Animal Studies and Biomedical Protocols |
| 9 | Antidiabetic Nanodrug Carriers and Biomedical Applications |
| 7 | Nanoparticles and Drug Delivery |
To validate our results, we reviewed the bibliometric and review studies of previous scholars on nanomedicine and summarized the emerging technologies identified in the field, as shown in Table 10 (Bragazzi, 2019; Chang et al., 2015; Dundar et al., 2020b; Ledet & Mandal, 2012; Sandhiya et al., 2009; Yeo, 2013). By comparing Table 10 with the emerging technologies we identified, we observed some overlap, demonstrating the credibility of our identification method and results.
Table 10. Emerging nanomedicine technology keywords classification. |
| Category | Keywords |
|---|---|
| Nanomaterial Applications | Nanoparticles; Nanotubes; Nanofibers; Nanocrystals; Nanoshells; Metal nanoparticles (e.g.; Gold; Silver); Carbon nanomaterials (e.g.; Graphene; Fullerenes); Quantum dots; Polymeric nanoparticles; Nucleic acid Nanostructures |
| Drug Delivery Systems | Drug-loaded nanoparticles; Nanomicelles; Nanoemulsions; Nanocapsules; liposomes; Polymeric drug conjugates; Targeted drug delivery; Controlled release systems; PH-responsive nanocarriers; Temperature-responsive nanocarriers |
| Diagnostics and Imaging | Molecular imaging; Magnetic resonance imaging (MRI); Positron emission tomography (PET); Single photon emission computed tomography (SPECT); Optical imaging; Fluorescence imaging; Raman spectroscopy imaging; Upconversion nanoparticle imaging; Multimodal imaging |
| Cancer diagnosis and treatment | Nanoparticles; Hypoxia therapy; Tumor-targeted therapy; Nano-immunomodulators |
| Nanotherapy for infectious diseases | Nano-antimicrobials; Inflammation; Antimicrobial peptides; Nano-vaccines; Nano-antibiotics |
| Rational Design of Antimicrobial Peptides | Antimicrobial peptides (AMPs); Peptide design; Membrane disruption mechanisms; Antibiotic resistance |
In summary, our analysis highlights the dynamic landscape of nanomedicine research, wherein certain specific topics have gained attention owing to their novelty, innovation, growth, and impact. These findings underscore the evolving priorities and emerging areas of significance in the field that have been influenced by recent global events and scientific breakthroughs.
5 Discussion
This study introduced a comprehensive framework that integrates state-of-the-art natural language processing, topic modeling, and bibliometric techniques to identify emerging technologies in the scientific literature. Using the SciBERT pre-trained model to extract informative sentences and NLDA to identify potential topics, our method overcomes the limitations of existing methods that rely solely on raw text, titles, or abstracts. Our proposed multidimensional metrics provide a quantifiable assessment of the emergence of novel topics across various dimensions, such as novelty, innovation, growth, impact, and intensity.
When applied to a nanomedicine publication dataset, our methodology revealed an upward trend in vaccine development and research related to antitumor therapies, emphasizing their status as cutting-edge research domains. This trend aligns with the significant impact of the COVID-19 pandemic on stimulating infection control measures and fostering innovation in vaccine development. In summary, our data-driven approach provided actionable technical intelligence.
5.1 Theoretical contributions
In terms of technology, our approach uses advanced natural language processing models to extract knowledge from a diverse range of textual data more effectively. This approach presents significant advantages in terms of ease and accuracy compared with the traditional machine leaning methods used by scholars for IE. Furthermore, we mitigate the noise word interference encountered in conventional LDA models by using NLDA topic modeling for improved topic recognition, thereby enhancing the interpretability of topic identification methods (Churchill & Singh, 2022a). This shift toward a data-driven approach has improved the efficiency of uncovering critical insights within the vast scientific literature.
Moreover, we adopted a diverse set of evaluation metrics. We have introduced innovativeness and topic strength indicators based on the IE and topic identification outcomes of this study. These multidimensional indicators provide a comprehensive quantitative perspective on the emergence of technology topics. The CRITIC methodology integrates these indicators to provide a holistic measure, thereby furnishing a more nuanced assessment of the emergence level of each technology topic (Diakoulaki et al., 1995). These multidimensional indicators expand the toolkit available for researchers investigating emerging technologies.
These theoretical contributions serve as templates for other researchers, assisting them in systematically discovering and analyzing emerging technologies. In addition to nanomedicine, these contributions have the potential to shape the way emerging trends are studied in various disciplines, thereby contributing to a deeper theoretical comprehension of the evolution of knowledge and technology.
5.2 Application contributions
Furthermore, this study offers several practical contributions, particularly in applying these findings (L. Yang et al., 2023). Identifying emerging technologies in nanomedicine provides practical insights for decision-makers, stakeholders, and policymakers. It is important to use technical methods to identify technology topics with a high degree of emergence in practical domains. For example, our study identified “ Inflammation and Biomaterial Interactions in Disease Research “ and “ Photothermal Therapy and Nanomaterials in Cancer “ as topics of notable prominence, implying their importance for further research and investment. Policymakers can use this information to make informed funding decisions, prioritizing areas with a higher potential for scientific progress and societal impact (J. S. Lee et al., 2022). Industry stakeholders can identify untapped market opportunities and focus their research and development efforts on areas with high growth potential.
Moreover, our cross-country analysis offers a global perspective on the distribution of innovative research in nanomedicine. In addition, the analysis of time reveals trends in innovative research in the field over the past decade. This practice promotes international collaboration and facilitates a more efficient allocation of resources.
5.3 Limitations and future research
Although our study provides valuable insights, it is crucial to acknowledge its limitations and identify potential avenues for future research. One notable limitation is our reliance on the existing scientific literature, which may introduce publication biases and language constraints. Furthermore, despite the meticulous manual annotation of the dataset, it remains susceptible to subjectivity and can be time-consuming. Future studies should consider exploring larger datasets, incorporating additional data sources, and automating the annotation process to address and mitigate these limitations effectively.
It is important to note that this research is confined to the domain of nanomedicine, and the identified topics are specific to this field. This methodology can be adapted and extended to investigate emerging technologies in other scientific domains. Furthermore, assessment criteria for emerging topics can be tailored to specific contexts and objectives, facilitating a more precise analysis.
In summary, this study presents a comprehensive framework for identifying emerging technologies, providing theoretical and practical contributions with far-reaching implications. These limitations serve as a roadmap for future research, extending the potential application of this methodology to various scientific disciplines and decision-making contexts.
Funding information
This work was supported by the National Natural Science Foundation of China (Project No. 22342011).
Acknowledgement
The authors would also like to thank anonymous reviewers for their valuable comments.
Author contributions
Yifan Wang (wyf_bjfu@163.com): Conceptualization (Lead), Data curation (Lead), Formal analysis (Lead), Methodology (Lead), Software (Lead), Writing - original draft (Lead), Writing - review & editing (Equal);
Xiaoping Liu (liuxp@mail.las.ac.cn): Conceptualization (Supporting), Funding acquisition (Equal), Project administration (Lead), Supervision (Lead), Writing - review & editing (Lead);
Xiang-Li Zhu (Zhuxl@mail.las.ac.cn): Funding acquisition (Supporting), Project administration (Supporting), Supervision (Supporting), Writing - review & editing (Supporting).
Declaration of interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.